












大型语言模型(LLMs)在各个领域都是一个优秀的助手,广大科研人员也对LLM在加速科学发现方面的潜力充满期待,比如已经有研究提出了能够自主生成和验证新想法的研究智能体。
然而,至今还没有评估结果能够证明LLM系统能够生成新颖的、达到专家水平的想法(idea),更不用说接手完成整个研究流程了。
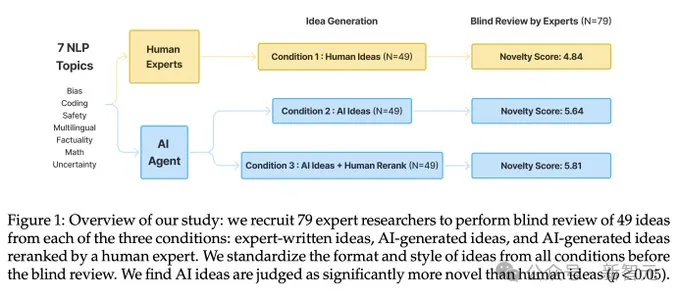
为了填补这一空白,斯坦福大学的研究人员最近发布了耗时一年完成的新实验,获得了第一个具有统计学意义的结论:LLM生成的想法比人类专家撰写的想法更新颖!

论文链接:https://arxiv.org/pdf/2409.04109
在论文中,研究人员设计了一个完整的实验,可以评估模型在新研究思路生成方面的能力,同时对可能的干扰因素进行控制,首次将专家级的自然语言处理(NLP)研究人员与LLM创意代智能体进行直接比较。
实验招募了超过100名高水平NLP研究人员来撰写新想法,然后对LLM生成的想法和人类想法进行盲审,参与者来自 36 个不同的机构,大部分是博士和博士后。
通过这种方式,研究人员首次得出「LLM在研究创意生成」能力的统计显著结论:LLM生成的想法在新颖性方面优于人类专家的想法(p < 0.05),但在可行性方面略逊一筹。
在深入研究基线模型时,研究人员发现了构建和评估研究智能体中的一些开放性问题,包括LLM自我评估的不足以及在生成过程中缺乏多样性。
在实验过程中,研究人员意识到,即使是专家,对想法新颖性的判断可能也非常困难,因此,文中提出了一个端到端的研究设计,招募研究人员将这些想法转化为完整的项目。
问题设置
研究人员将科研想法评估(research idea evaluation)分为三个独立的子部分,主要关注潜在的混杂因素,如研究领域、研究想法的格式和评估过程。
1. 想法本身,根据指令产生;
2. 传达想法的书面报告(writeup);
3. 专家对书面报告的评估。
构想的范围和指令(Ideation Scope and Instructions )
研究想法既可以是一个能够提高模型性能的技巧,也可以是博士论文中描述的大规模研究计划,任何关于构想的实验都必须仔细平衡研究想法的「现实性」和「趣味性」。
受思维链等项目的启发,一些简单的提示思路就能大幅提升LLM的性能,还能够在不复杂的计算硬件上执行,所以研究人员选择「基于提示的自然语言处理」研究作为初步实验领域。
在提示词的编写思路上,LLM更倾向于安全的主题,与人类的偏好不一致,所以研究人员为了统一目标,从最近的NLP会议的征稿页面中提取了七个具体的研究主题,包括偏见(bias)、编码(coding)、安全性(safety)、多语言性(multilingual)、事实性(factuality)、数学(math)和不确定性(uncertainty)。

想法书面报告(idea writeup)
一个想法只有在被写出来后,其他人才能以此交流并评估,但写作过程会引入其他混杂因素,例如人类研究者可能会用春秋笔法让研究内容看起来更高大上,比如包括更多的例子和实现细节。
研究人员从资助申请中使用的指南中获得灵感,编写了一个模板来指定想法提案的结构和详细程度,包括标题、问题陈述、动机、提出的方法、逐步实验计划、测试用例示例和备选计划等字段。

不过,即使有了模板,可能仍然存在微妙的写作风格差异,例如,人类可能倾向于以更具吸引力和非正式的语气写作。
为此,研究人员又开发了一个风格标准化提示,使用LLM将所有想法转换为相同的写作和格式化风格,而不改变原始内容。

评审和评估(review and evaluation)
对研究想法的评审往往是主观的,研究人员的目标是设计一个明确定义所有评审标准的表格,以尽可能地将评审过程标准化和锚定评估。
研究人员在设计评审表格时,遵循了AI领域会议(如ACL和ICLR)评审的最佳实践,定义了四个分解指标,包括新颖性(novelty)、兴奋度(excitement)、可行性(feasibility)和预期效果(expected effectiveness)。
每个指标在评审时,都有一个1-10的数字评分,和一段文本作为理由。
盲审评估从三种不同条件下对想法进行对比:
1. 人类想法(human ideas):由招募的专家研究者撰写的想法提案。
2. AI想法:由LLM智能体生成的想法提案,直接从智能体的输出中获取排名靠前的想法。
3. AI想法+人类重新排名:由LLM智能体生成的想法提案,再由人工手动从LLM智能体生成的所有想法中选择了排名靠前的想法,以便更好地估计AI想法的上限质量。

想法生成智能体(idea generation agent)
论文检索
为了使创意生成有据可依,智能体需要检索与给定研究主题相关的论文,以便在生成新创意时能够了解相关研究。
研究人员利用检索增强生成(RAG),给定一个研究主题后,例如「能够提高事实性并减少大型语言模型幻觉的新型提示方法」,首先提示一个LLM生成一系列对Semantic Scholar API的函数调用,然后使用claude-3-5-sonnet-20240620作为智能体的骨干模型,论文检索的动作空间包括:{KeywordQuery(关键词), PaperQuery(论文ID), GetReferences(论文ID)}。
然后根据一系列标准对检索到的文献进行评分和排序,包括文献与主题的相关性、是否包含计算实验的经验性研究,以及文献的创新性和启发性,最多检索120篇论文。
创意生成
研究人员的思路是,首先用LLM为每个研究主题生成4000个种子创意,创意生成提示包括示范示例和检索到的论文;然后用排序器来从中选取出一小部分高质量的,为了从庞大的候选创意池中去除重复的创意,使用Sentence-Transformers中的all-MiniLM-L6-v2对所有种子创意进行编码,然后计算成对的余弦相似度来进行一轮去重,最后得到大约5%非重复创意。
创意排名
为了对创意进行排名,研究人员利用了1200篇ICLR 2024会议中与大型语言模型相关的论文及其评审分数和接受决定的数据。
结果发现,当直接要求LLMs预测论文的最终分数或接受决定时,模型的预测准确性不高,但在成对比较中判断哪篇论文更优秀时,却能够达到较高的准确性。
研究人员使用Claude-3.5-Sonnet模型作为自动排名器,在零样本提示下,通过成对比较任务达到了71.4%的准确率,优于其他模型。
为了确保所有项目提案的排名可靠性,采用瑞士制比赛系统进行多轮评分;在验证集上,发现排名前10的论文与排名后10的论文在平均评审分数上有明显差异,证明了排序器的有效性;在实验中,选择了5轮作为评分标准。
此外,为了比较AI排序器与人类专家的差异,研究人员还设置了一个条件,即由人工手动对生成的项目提案进行重排,结果显示两种排名方法存在一定差异。



















