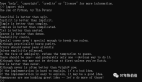
1. 利用三元操作符简化条件赋值
理论讲解:
在Python中,我们可以使用一种叫做“条件表达式”(也叫“三元操作符”)的方式来简化条件判断语句。这种表达式的语法是 value_if_true if condition else value_if_false。
代码示例:
代码解释:这段代码首先定义了一个变量 age 并赋值为 20。接下来,使用条件表达式来根据 age 的值决定 status 的值。如果 age 大于等于 18,则 status 被设为 '成年',否则为 '未成年'。
使用技巧:
- 适合简单的条件判断。
- 可以嵌套使用,但建议不要超过两层以保持代码可读性。
注意事项:不要滥用,对于复杂的逻辑,还是应该使用标准的 if-else 语句。
2. 使用列表推导式快速创建列表
理论讲解:
列表推导式是一种使用单行代码创建新列表的方式。其基本语法形式为 [expression for item in iterable]。
代码示例:
代码解释:
这里使用列表推导式生成了一个包含 1 至 5 的平方的新列表。range(1, 6) 生成一个从 1 到 5 的序列,x ** 2 对每个元素求平方。
使用技巧:可以加入条件判断:[expression for item in iterable if condition]。
注意事项:当列表很大时,考虑性能和内存使用,可以使用生成器表达式代替。
3. 字典推导式轻松构建字典
理论讲解:
类似于列表推导式,字典推导式允许你以简洁的方式创建字典。语法为 {key_expression: value_expression for item in iterable}。
代码示例:
代码解释:该代码片段展示了如何利用字典推导式根据名字列表创建一个字典,其中键为名字,值为名字长度。
使用技巧:结合条件表达式:{key_expression: value_expression for item in iterable if condition}。
注意事项:确保键是唯一的,否则后面的键会覆盖前面的键值。
4. 使用集合推导式快速创建集合
理论讲解:集合推导式用于创建集合,其语法为 {expression for item in iterable}。
代码示例:
代码解释:通过集合推导式从一个含有重复元素的列表中提取出所有唯一值并存储在一个新的集合中。
使用技巧:集合推导式非常适合去除重复项。
注意事项:集合是无序且不允许重复的,因此不能用于需要保留顺序或重复的数据。
5. 用any()和all()简化布尔逻辑
理论讲解:any() 和 all() 函数分别用于检查迭代器中的元素是否至少有一个为真或全部为真。
代码示例:
代码解释:在这个例子中,any() 返回 False 因为所有元素都是假值。而 all() 同样返回 False,因为没有一个元素是真的。
使用技巧:当需要检查某个集合中是否存在任何符合条件的元素时,使用 any()。
当需要确认所有元素都满足特定条件时,使用 all()。
注意事项:这些函数仅适用于布尔值或可以转换为布尔值的对象。
6. 利用enumerate()遍历带索引的序列
理论讲解:enumerate() 函数可以在遍历序列的同时获取当前项的索引和值。
代码示例:
代码解释:通过 enumerate() 函数,每次循环都能同时访问到列表中的元素及其索引位置。
使用技巧:常用于需要索引信息的场合。
注意事项:默认索引从 0 开始,可以通过传入第二个参数来改变起始索引。
7. 用zip()合并多个序列
理论讲解:zip() 函数能够将多个序列合并成一个新的序列,其中新序列的每一项都是原序列中对应位置的元素组成的元组。
代码示例:
代码解释:zip() 将两个列表组合在一起,生成一个新的列表,每个元素都是一个元组,包含原来两个列表中相同位置上的元素。
使用技巧:当需要同时处理多个相关的序列时非常有用。
注意事项:如果输入的序列长度不一致,则 zip() 会以最短的那个为准。
8. 利用sorted()函数进行排序
理论讲解:sorted() 是一个内置函数,可以用来对任何可迭代对象进行排序,默认按照元素的自然顺序排序。
代码示例:
代码解释:这里使用 sorted() 对一个整数列表进行升序排序。
使用技巧:
- 可以通过设置 reverse=True 来实现降序排序。
- 也可以指定 key 参数来自定义排序规则。
注意事项:sorted() 不会修改原始列表,而是返回一个新的排序后的列表。
9. 使用切片操作简化数组操作
理论讲解:Python 中的切片操作允许你通过指定开始、结束和步长来访问序列的一部分。
代码示例:
代码解释:该代码片段展示了如何使用切片从列表中取出一个子集,从索引 2 开始,每隔一个元素取一次,直到索引 8 结束。
使用技巧:切片操作非常灵活,可以用来反转列表、获取副本等。
注意事项:索引是从零开始的,且结束索引不包含在内。
实战案例:统计一段文本中单词出现频率
假设我们需要编写一个程序来统计给定文本中每个单词出现的次数。我们可以结合使用字符串分割、字典推导式以及列表推导式来实现这一功能。
代码示例:
代码解释:
首先,我们将文本按空格分割成单词列表。然后,利用字典推导式统计每个单词出现的次数。为了避免重复计数,我们先将单词列表转换成集合,然后再进行计数。