MinerU 是一款由上海人工智能实验室OpenDataLab团队发布的全能、开源的文档与网页数据提取工具。它能够将包含图片、表格、公式等元素的多模态PDF文档转化为清晰、易于分析的Markdown格式,同时也支持从包含广告等干扰信息的网页中快速解析、抽取正式内容,并将其批量转化为Markdown格式。

一、主要特点
多功能性:MinerU 包含两个主要部分:Magic-PDF和Magic-Doc,分别负责PDF文档提取和网页与电子书提取。
多模态处理:Magic-PDF能够处理PDF中的图像、表格、公式等多种内容类型,并保留原文档的结构和格式。
高质量解析:MinerU使用了先进的模型,如LayoutLMv3、YOLOv8、UniMERNet和PaddleOCR,以确保数据提取的高准确度。
广泛的应用场景:适用于学术、财务、法律等多个领域,并支持多达176种语言的准确识别。
跨平台支持:能够在Windows、Linux和Mac平台上运行,并支持CPU和GPU环境。

二、使用场景
MinerU 适用于需要从复杂格式的文档中提取数据的场景,尤其适合于AI研究和大模型训练中处理大量非结构化数据的需求。
三、技术细节

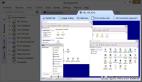
PDF文档提取:MinerU的PDF提取过程包括PDF文档分类预处理、模型解析和管线处理等环节。它能够识别和处理文本型、图层型和扫描版的PDF文档,并通过一系列深度学习模型进行版面分析、OCR和公式识别。
网页与电子书提取:Magic-Doc能够从多种类型的网页和电子书中提取信息,支持包括epub、mobi在内的多种格式,并能够处理文章、论坛、音乐、视频等内容类型。

四、快速安装与使用
CPU Demo
Docker 快速部署
更多使用方式,请查阅如下提供地址
总结
体验链接: https://opendatalab.com/OpenSourceTools/Extractor/PDF
开源仓库:https://github.com/opendatalab/MinerU/
MinerU开源模型(PDF-Extract-Kit): https://modelscope.cn/models/OpenDataLab/PDF-Extract-Kit