在软件开发中,导出大量数据到 Excel 文件是一个常见需求,但往往也面临性能瓶颈。本文将详细探讨如何优化 C# 项目中的 Excel 导出性能,包括数据库查询优化、数据处理优化、Excel 库的选择、异步处理、分页导出等多个方面,并提供具体的示例代码。

一、性能问题识别
首先,需要明确导出过程中性能瓶颈所在。通常,导出 Excel 文件的性能问题主要集中在以下几个环节:
- 数据库查询:查询大量数据可能导致数据库响应缓慢。
- 数据处理:数据转换、格式化等操作可能消耗大量 CPU 资源。
- Excel 文件生成:生成大型 Excel 文件时,内存和磁盘 I/O 可能成为瓶颈。
二、优化策略
1. 数据库查询优化
- 避免大范围的联表查询:对于大型数据集,尽量避免使用联表查询,特别是当表数据量达到千万级或亿级时。
- 分批查询:采用分批查询策略,每次只查询一定数量(如2000条)的数据,减少单次查询的压力。
- 利用缓存:根据数据访问模式合理设计缓存策略,预加载部分数据。
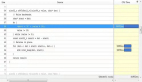
示例代码:
2. 数据处理优化
- 减少循环次数:避免在循环内部进行数据库查询或其他重操作。
- 使用合适的数据结构:如使用 List<T> 存储待查询的 ID,便于批量查询。
3. Excel 库的选择
选择性能优异的 Excel 处理库,如 EPPlus 或 NPOI。这些库通常支持直接将数据写入 Excel 文件的二进制流,减少中间对象的创建。
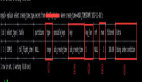
示例代码(使用 NPOI 库):
4. 异步处理
如果系统支持,使用异步编程模型可以提高性能。通过异步读取数据库和写入 Excel,可以释放主线程,使其专注于其他任务。
5. 分页导出
对于非常大的数据集,可以考虑分页导出,让用户逐步下载,而不是一次性加载所有数据。
6. 内存管理
保持良好的内存管理习惯,及时释放不再使用的对象,避免内存泄漏。
三、结论
通过上述策略的综合运用,可以显著提升 C# 项目中导出数据到 Excel 的性能。开发者应根据具体的应用场景和数据特性,灵活选择和调整优化方法,以达到最佳的性能效果。同时,持续监控和评估导出性能,根据实际情况不断优化和调整优化策略。