












最近一段时间,有关 AI 科学家的研究越来越多。大语言模型(LLM)有望帮助科学家检索、综合和总结文献,提升人们的工作效率,但在研究工作中使用仍然有很多限制。
对于科研来说,事实性至关重要,而大模型会产生幻觉,有时会自信地陈述没有任何现有来源或证据的信息。另外,科学需要极其注重细节,而大模型在面对具有挑战性的推理问题时可能会忽略或误用细节。
最后,目前科学文献的检索和推理基准尚不完善。AI 无法参考整篇文献,而是局限于摘要、在固定语料库上检索,或者只是直接提供相关论文。这些基准不适合作为实际科学研究任务的性能代理,更重要的是,它们通常缺乏与人类表现的直接比较。因此,语言模型和智能体是否适合用于科学研究仍不清楚。
近日,来自 FutureHouse、罗切斯特大学等机构的研究者们尝试构建一个更为强大的科研智能体,并对 AI 系统和人类在三个现实任务上的表现进行严格比较。这三个任务有关搜索整个文献以回答问题;生成一篇有引用的、维基百科风格的科学主题文章;从论文中提取所有主张,并检查它们与所有文献之间的矛盾。
这可能是第一个在多个现实文献搜索任务上评估单个 AI 系统的强大程序。利用新开发的评估方法,研究者探索了多种设计,最终形成了 PaperQA2 系统,它在检索和总结任务上的表现超过了博士生和博士后。

将 PaperQA2 应用于矛盾检测任务让我们能够大规模识别生物学论文中的矛盾。例如,ZNF804A rs1344706 等位基因对精神分裂症患者的大脑结构有积极影响的说法与后来发表的研究相矛盾,该研究发现 rs1344706 对大脑皮质厚度、表面积和皮质体积的影响会加剧患精神分裂症的风险。

- 论文地址:https://storage.googleapis.com/fh-public/paperqa/Language_Agents_Science.pdf
- GitHub 链接:https://github.com/Future-House/paper-qa
网友纷纷表示这项工作太棒了,并且是开源的。

回答科学问题
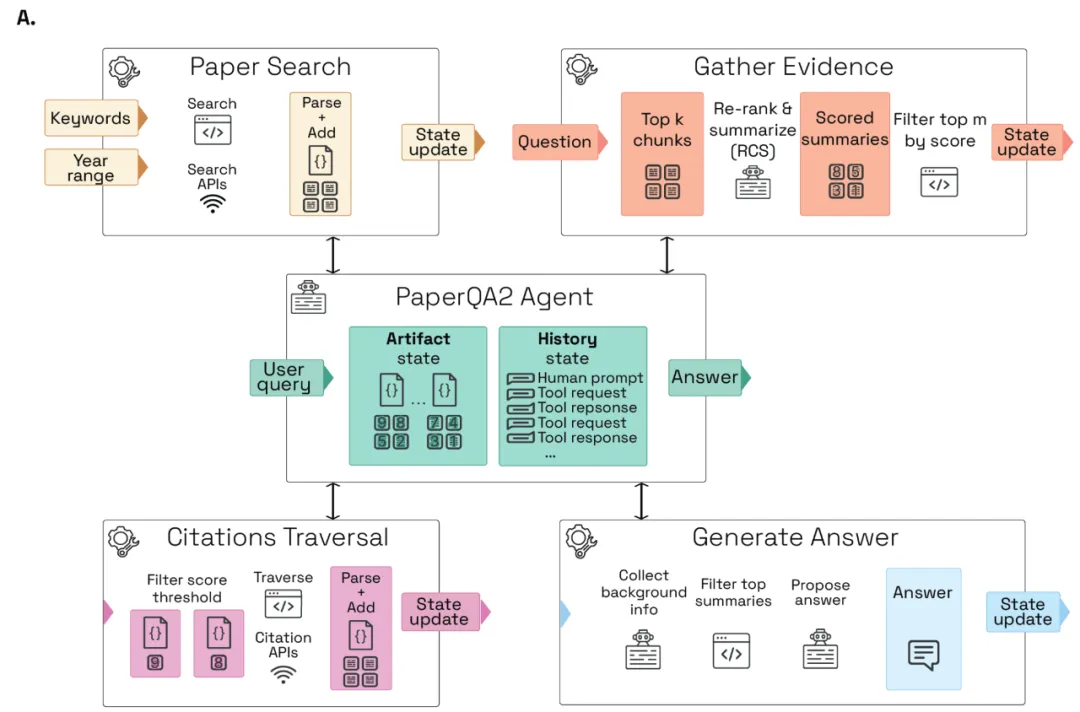
为了评估 AI 系统对科学文献的检索能力,研究者首先生成了 LitQA2,这是一组共 248 个多项选择题,其答案需要从科学文献中检索。LitQA2 问题的设计目的是让答案出现在论文正文中,但不出现在摘要中,理想的情况下,在所有科学文献中只出现一次。这些约束使我们能够通过将系统引用的来源 DOI 与问题创建者最初分配的 DOI 进行匹配来评估回答的准确性(下图 A)。
为了执行这些标准,研究者生成了大量关于最近论文中模糊的中间发现的问题,然后排除了任何现有 AI 系统或人类注释者可以使用替代来源进行回答的问题。它们都是由专家生成的。
在回答 LitQA2 问题时,模型可以通过选择「信息不足,无法回答此问题」来拒绝回答。与先前的研究和实际的科学问题类似,有些问题本来就是无法回答的。研究者评估了两个指标:精确度(即在提供答案时正确回答的问题的比例)和准确度(即所有问题中正确答案的比例)。此外还考虑了召回率,即系统将其答案归因于 LitQA2 中表示的正确源 DOI 的问题的总百分比。

在开发了 LitQA2 之后,研究者利用它来设计一个科学文献的 AI 系统。在 PaperQA 的启发下,PaperQA2 是一个 RAG 智能体,它将检索和响应生成视为一个多步骤智能体任务,而不是一个直接过程。PaperQA2 将 RAG 分解为工具,使其能够修改其搜索参数,并在生成最终答案之前生成和检查候选答案(下图 A)。
PaperQA2 可以访问「论文搜索」工具,其中智能体模型将用户请求转换为用于识别候选论文的关键字搜索。候选论文被解析为机器可读的文本,并分块以供智能体稍后使用。PaperQA2 使用最先进的文档解析算法(Grobid19),能可靠地解析论文中的章节、表格和引文。找到候选论文后,PaperQA2 可以使用「收集证据」工具,该工具首先使用 top-k 密集向量检索步骤对论文块进行排序,然后进行大模型重新排序和上下文摘要(RCS)步骤。
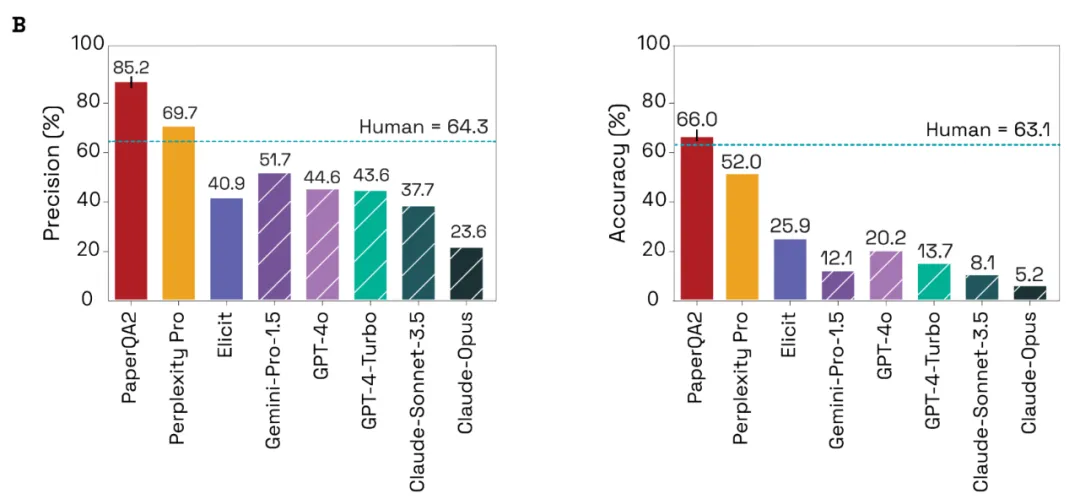
在回答 LitQA2 问题时,PaperQA2 平均每道题解析并使用 14.5 ± 0.6(平均值 ± SD,n = 3)篇论文。在 LitQA2 上运行 PaperQA2 可获得 85.2% ± 1.1%(平均值 ± SD,n = 3)的精确度和 66.0% ± 1.2%(平均值 ± SD,n = 3)的准确度。另外,系统在 21.9% ± 0.9%(平均值 ± SD,n = 3)的答案中选择报告「信息不足」(下图 B)。
研究者发现 PaperQA2 在 LitQA2 基准测试中的精确度和准确度均优于其他 RAG 系统。我们还可以发现,除 Elicit 外所有测试的 RAG 系统在精确度和准确度方面均优于非 RAG 前沿模型。
为了确保 PaperQA2 不会过拟合,从而无法在 LitQA2 上取得优异成绩,研究者在对 PaperQA2 进行大量工程改动后,生成了一组新的 101 个 LitQA2 问题。
PaperQA2 在原始 147 个问题上的准确率与后一组 101 个问题的准确率没有显著差异,这表明在第一阶段的优化已经很好地推广到了新的 LitQA2 问题(下表 2)。

PaperQA2 性能分析
研究者尝试改变 PaperQA2 的参数,以了解哪些参数决定其准确性(下图 C)。他们创建了一个非智能体版本,其中包含一个硬编码操作序列(论文搜索、收集证据,然后生成答案)。非智能体系统的准确率明显较低(t (3.7)= 3.41,p= 0.015),验证了使用智能体的选择。
研究者将性能差异归因于智能体更好的记忆能力,因为它可以在观察到找到的相关论文数量后返回并更改关键字搜索(论文搜索工具调用)。
结果显示,LitQA2 运行准确度最高时为每个问题进行了 1.26 ± 0.07(平均值 ± SD)次搜索,每个问题进行了 0.46 ± 0.02(平均值 ±SD)次引用遍历,这表明智能体有时会返回进行额外搜索或遍历引用图以收集更多论文。
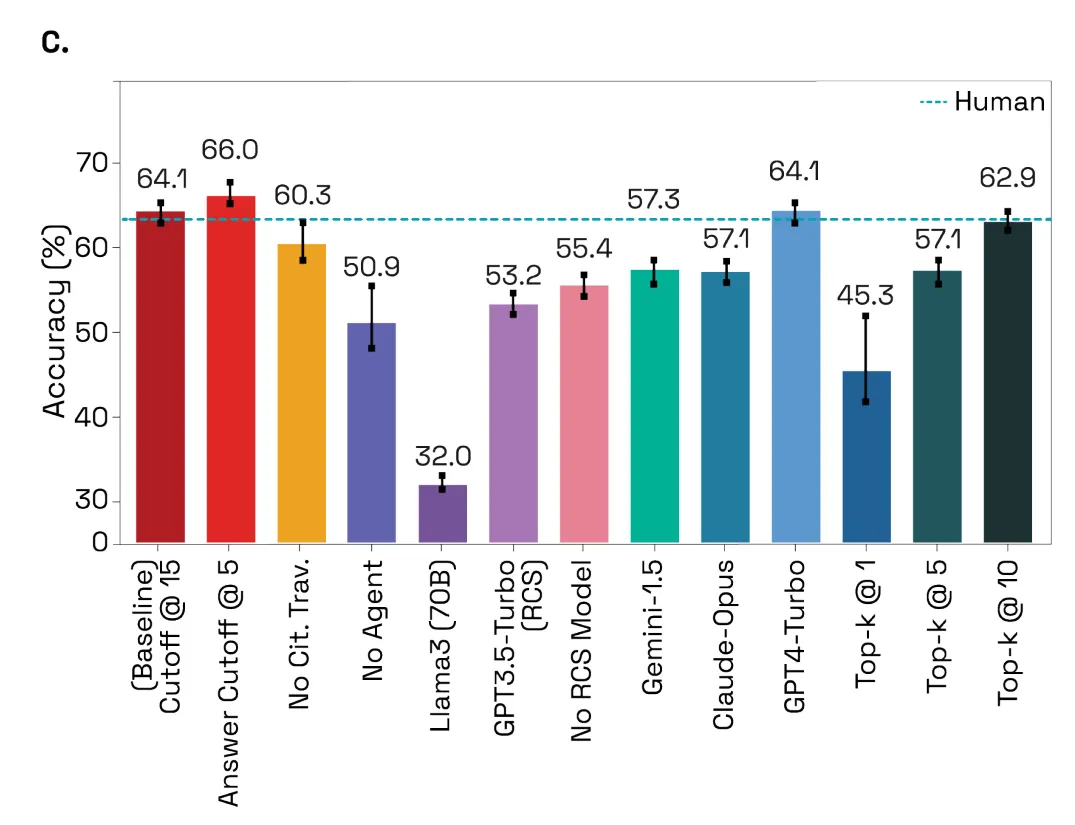
为了改进相关块检索,研究者假设,找到的论文对于现有相关块的引用者或被引用者而言将是一种有效的分层索引形式。通过去除「引用遍历」工具验证了这一点,该工具显示准确率有所提高(t (2.55) = 2.14,p= 0.069),DOI 召回率显著提高(t (3) = 3.4,p = 0.022),并在 PaperQA2 流程的所有阶段都是如此。该工具的流程反映了科学家与文献互动的方式。
研究者曾假设解析质量会影响准确度,但 Grobid 解析和更大的块并没有显著提高 LitQA2 的精度、准确度或召回率(下图 6)。

总结科学主题
为了评估 PaperQA2 的摘要功能,研究者设计了一个名为 WikiCrow 的系统。该系统通过结合多个 PaperQA2 调用来生成有关人类蛋白质编码基因的维基百科风格文章,而这些调用涉及基因的结构、功能、相互作用和临床意义等主题。
研究者使用 WikiCrow 生成了 240 篇有关基因的文章,这些文章已经有非存根维基百科文章进行匹配比较。WikiCrow 文章平均为 1219.0 ± 275.0 个字(平均值 ± SD,N = 240),比相应的维基百科文章(889.6 ± 715.3 个字)长。平均文章生成时间为 491.5 ± 324.0 秒,平均每篇文章成本为 4.48 ± 1.02 美元(包括搜索和 LLM API 的费用)。

同时,「引用但不受支持」评估类别包括不准确的陈述(例如真实幻觉或推理错误)和准确但引用不当的声明。
为了进一步调查维基百科和 WikiCrow 中的错误性质,研究者手动检查了所有报告的错误,并尝试将问题分类为以下几类:
- 推理问题,即书面信息自相矛盾、过度推断或不受任何引用支持;
- 归因问题,即信息可能得到另一个包含的来源支持,但该声明在本地没有包含正确的引用或来源太宽泛(例如数据库门户链接);
- 琐碎的声明,这些声明虽是真实的段落,但过于迂腐或没有必要。

检测文献中的矛盾
由于 PaperQA2 可以比人类科学家探索吞吐量高得多的科学文献,因此研究者推测可以部署它来系统地、大规模地识别文献中矛盾和不一致的地方。矛盾检测是一个「一对多」问题,原则上涉及将一篇论文中的观点或声明与文献中所有其他观点或声明进行比较。在规模上,矛盾检测变成了「多对多」问题,对人类来说失去了可行性。
因此,研究者利用 PaperQA2 构建了一个名为 ContraCrow 的系统,可以自动检测文献中的矛盾(下图 A)。

ContraCrow 首先使用一系列 LLM completion 调用从提供的论文中提取声明,然后将这些声明输入到 PaperQA2 中,并附带矛盾检测提示。该提示指示系统评估文献中是否存在与提供的声明相矛盾的内容,并提供答案和 11-point 李克特量表的选择。使用李克特量表可让系统在提供排名时给出更可靠、更易于解释的分数。

接下来,研究者评估了 ContraCrow 检测 ContraDetect 中矛盾的能力。通过将李克特量表输出转换为整数,他们能够调整检测阈值并获得 AUC 为 0.842 的 ROC 曲线。将阈值设置为 8(矛盾),ContraCrow 实现了 73% 的准确率、88% 的精度和仅为 7% 的假阳性率(下图 C)。

研究者将 ContraCrow 应用于从数据库中随机选择的 93 篇生物学相关论文,平均每篇论文识别出 35.16 ± 21.72(平均值 ± SD,N = 93)个声明。在对 93 篇论文分析出的 3180 个声明中,ContraCrow 认为 6.85% 与文献相矛盾,其中分别有 2.89%、3.77% 和 0.19% 的声明被打了 8 分、9 分和 10 分(下图 D)。

此外,当将李克特量表阈值设定为 8,研究者发现平均每篇论文有 2.34 ± 1.99 个矛盾(平均值 ± SD)(下图 E)。

更多任务细节和测试结果请参阅原论文。


















