一、背景
对于水印,相信大家都不陌生。在很多内部平台、对数据信息较为敏感的中后台系统当中,我们基本上都会在系统关键数据展示区域中,加上一个半透明的文字水印(通常是用户名或用户id等能够唯一识别用户的标识),以防止使用者通过截图、拍照等方式将目标页面的数据泄露出去。即使是泄露出去之后,也可以根据水印中的用户标识能够迅速定位到“始作俑者”,并采取一些必要的手段将泄密损失降到最低。
上述场景是水印最为常用的一个场景,但不代表水印只能用于这种场景,今天我们从水印技术的前世今生,一步步展开暗水印显隐术的神秘面纱,揭秘暗水印显隐术与 OCR的邂逅,如何提升测试、生产排障效率的。
二、水印技术演进简史
 图片
图片
水印从刚开始如同旧社会的窗纸一般一戳就破的毫无防护状态,通过不断的演进与优化,逐步增加水印的安全性,为水印功能增加了防删除、防隐身、防覆盖、防感知的能力,如同为窗户披上了一层又一层的合金防爆装甲,牢牢地守护着企业的核心数据安全。
演进实现演示
原始版水印:V1
 图片
图片
上述代码比较简单,原理就是用 canvas 绘制水印内容生成图片,然后以平铺的背景图的方式插入到页面当中,这边就不再赘述,上述代码的效果:
 图片
图片
防删除水印:V2
上面实现的基础版水印,有个很明显的漏洞,那就是只要我们打开控制台,找到展示水印的那个 div 元素,然后直接删除,页面上的水印就消失了。
由此可见我们实现的基础版本的弱鸡属性。
那么,我们要如何防止用户删除元素呢?
既然用户有可能通过删除节点来去掉水印,那么,我们是否能够监听节点的变化,一旦用户删除目标节点时,我们就将删除的节点重新加回去,这样不就可以解决问题了吗?
说干就干,我们先来看看要如何监听节点的变化。
经过查阅文档后,找到了 MutationObserver 这个API,可以帮助我们监听目标元素的相关变化,话不多说,我们来看看效果如何。
 图片
图片
上述示例运行后的效果是这样的:
防隐身水印:V3
那么,这种操作我们要怎么防止呢?其实也很简单,依然还是使用 MutationObserver ,它不仅可以帮我们监听子节点的变化,还能监听属性的变化。既然用户想用样式style让我们的水印隐身,那么我们就在用户改变水印的样式时,重置它的样式即可。
 图片
图片
我们来看看效果如何:

看起来已经有了点狗皮膏药的意思了,甩也甩不掉,改也改不了。
但是,这样就算完了吗?不!还没完!
防覆盖水印:V4
别以为这样就完了,既然动不了水印元素,那咱还可以曲线救国嘛,通过修改我们想要看的那个元素的样式,让它覆盖在水印元素之上,这样不是也可以达到我们的目的吗?
这个问题其实是很多水印 SDK 和项目实现水印时忽略的问题,比如说我们工作中最常使用的飞书文档,它的水印也做到了防删除和防隐身,但却没有做到防覆盖,导致我们只需要修改内容区层级,就可以绕过水印了。
确实,通过修改内容区的z-index也能达到绕过我们的水印直接截图的目的,但这也难不倒聪明的前端工程师们。既然我们可以监听水印元素的属性变化,监听内容元素属性变化也是如出一辙。我们只需要监听到调整z-index的变化时,始终确保水印元素的层级是最高的即可。
由于z-index属性除了auto外,只能传入整型,所以,它的最大值也就是整型的最大值,那么,我们可以调整一下我们水印的层级,让它就等于整型的最大值。然后监听内容区所有元素的属性变化,只要修改了层级,并且层级大于或等于整型最大值的,就让它的层级变成最大值减一即可。
 图片
图片
Nice!这样一来,无论你是改水印元素还是该内容元素,水印都已经死死地贴在了内容上面了,怎么甩都甩不掉了。
防感知水印:V5
通过上述一顿操作,其实我们的水印已经算是相对安全了,但我们上面使用的水印,用户还是能够看的见的,有时还可能影响用户查看一些内容,我们有没有办法可以利用技术手段,让我们肉眼看不出来这个水印,但一旦出现数据泄密,我们拿到截图后,又能够迅速定位泄密者呢?
这就可以利用到「暗水印」技术了。暗水印是相对于「明水印」而言的说法,我们上面使用的就是明水印。所谓的暗水印,其实就是将我们的水印的透明度调到极低,让用户肉眼基本无法看到,这样,用户看不到水印,自然也不会想办法破解,也为我们的水印再披上了一层隐身衣。但当我们需要的时候,又可以一些方式,让他们显现出原型。举个例子,利用RGBA通道的特性,将R、G、B三个通道中的两个通道设置清空掉(设置为 0 或 255),仅保留一个通道,这样就可以将我们想要的信息提取出来。
 图片
图片
上述代码当中,我们的test.png是长这样的:
 图片
图片
看起来是不是就是一个无比正常并且没有加水印的页面呢?别急,我们把这张截图使用decodeWatermark方法解密一下看看。
 图片
图片
二、暗水印显隐术与OCR的邂逅
上面,我们通过简单的代码示例,一步一步的对我们水印的安全性进行提升,可以说已经是:“经拉又经拽,经蹬又经踹”了。就像前文所说的,水印最常使用的场景是数据安全与防护,但绝不是只能用于这个场景。
由于暗水印的优势在于,对于用户来说全无感知,无论是B端应用,还是C端应用,都可以通过暗水印技术在在页面上打印一些关键信息,例如在B端可以打印用户id、当前页面路由信息等,在C端可以打印当前用户的id、设备关键信息、网络状况等可以辅助我们排查用户遇到问题的一些信息。用户反馈时,只需要提供页面的截图,而不需要用户提交一堆跟技术相关的信息,我们就可以通过将暗水印解码出来并获取到这些信息,辅助我们快速定位用户问题,提升用户反馈体验。
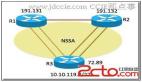
功能设计与架构
结合目前我们负责的会场搭建器的一些应用场景,想要在项目中利用「暗水印」技术为搭建器(一个用于快速搭建页面的无代码平台)打上特定的标识,而这些标识,能够帮我们迅速的定位目标会场(即页面,后文如无特殊说明,会场均代表页面)。我们的实际应用场景是这样的:用户在搭建会场的时候出现了某些问题,对会场搭建页面的部分页面进行截图反馈,而相关开发人员可以仅通过用户提供的截图,通过将截图中的暗水印显示出来,我们的开发人员就可以通过暗水印中的会场相关信息,快速定位相关会场,排查问题。
当然,如果更进一步,我们还可以通过用户上传的截图,在解码出暗水印之后,使用「光学字符识别技术(OCR)」提取出我们关注的会场信息,进行自动搜索目标会场的操作。
 图片
图片
方案分析与选择
暗水印解码方案
目前市面上针对暗水印的解码方案大概有以下几种:
- 利用【颜色通道屏蔽】的方式实现解码(上面示例使用的就是这个方法)
 图片
图片
- 利用【图片二极化】的方式实现解码,解码出来的图片只有黑白两色
 图片
图片
- 利用【混合模式叠加图层蒙版】的方式实现解码
 图片
图片
从上面的截图来看,好像三种方案都能达到暗水印解码的目的,但实际上,前两种情况太容易因为背景噪音而产生干扰了,如果所在页面的背景颜色比较复杂,很容易影响暗水印识别的准确性。因此,我们最终选择使用上述的第三种方案,即:利用【混合模式叠加图层蒙版】的方式实现解码。后文中也会对这个方案做详细的介绍。
光学字符识别(OCR)方案
如果只有暗水印的话,每次我们都需要通过肉眼识别,如果字符不多还好,如果字符多了直接眼瞎,例如水印内容是页面 id 的场景。因此,我们我们还需要研究一下应该如何根据图片提取相关的文字信息。
很多办公、社交软件,如:微信、QQ、飞书、钉钉等,都有提取聊天内容中的图片中的文本内容的功能。由于我们公司使用飞书作为办公平台,因此,我第一时间就在想:“飞书会不会有提供相关的开放API给我们调用呢?”
- 一些开放的光学字符识别接口,如:飞书开放平台的光学字符识别接口
 图片
图片
 图片
图片
- 纯前端光学字符识别
开放接口虽好,但有各种限制,需要注册应用,还可能限流以及产生费用等。因此,我们期望能有接入更加方便且成本更低的方式实现。因此在 Github 社区上一顿搜索,最后找到一个社区活跃且功能非常强大的前端OCR库:tesseract.js 。
 图片
图片
至此,截图搜所依赖的的前置拼图都已经整理出来了,接下来就是将这些拼图组合成完整的功能并对相应场景进行针对性的优化。
四、OCR识别准确率提升
截图搜功能有两个核心模块,第一个就是「暗水印解析模块」,第二个就是「OCR 光学字符识别模块」,这两个模块的执行效果都会直接影响到我们最终识别结果的优劣。因此,如果需要提升OCR识别的准确率,我们就需要分别从这两个核心模块上下功夫。
暗水印解析模块
针对暗水印解析模块,我们优化提升的目标是在各种复杂的场景下,尽可能保证暗水印的清晰度,以此确保人眼识别和OCR识别的准确性。
首先,我们来看一下,我们之前的方案都有哪些问题:
- 在水印字体颜色与页面背景颜色接近时暗水印无法辨识
 图片
图片
- 原始页面背景复杂时对水印文案的影响太大
 图片
图片
以上两个问题,都会严重影响我们识别水印中内容的准确性,因此我们需要想办法解决。
更换暗水印解码方案
我们的原始方案采用的是:「图片二极化处理」的方案,经过大量的尝试,发现这种方案没办法适应各种复杂场景和与水印颜色接近的背景的场景,因此,我们不得不尝试探索其他的解决方案。
以下为这边探索和思考目标解决方案的心路历程:
1. 梳理要达成的目标:让暗水印凸显让背景淡化;
2. 记得曾经使用 PhotoShop 查看设计稿的时候,设计师们经常使用类似这样的一个技巧:在某些文字上面想要加入一些底纹和特效的时候,通常会在目标文字图层之外再建一个新图层,在这个图层绘制目标底纹和特效,然后通过图层蒙版的形式将这个底纹和特效附加到文字图层上。我们是不是也可以利用类似这样的思路,在我们用户提供的截图基础上,叠加一个新的图层,利用图层的一些特定的颜色或图案,让我们的文字凸显,让背景淡化呢?
 图片
图片
3. 尝试在搜索引擎和 GPT 中搜索浏览其中 js 可以使用的一些满足上面条件的 API,最后,在 MDN 文档中找到了以下文档参考:
- 组合 Compositing - Web API | MDN
- CanvasRenderingContext2D.globalCompositeOperation - Web API | MDN
4. 利用 canvas 对于混合模式的支持,似乎可以实现我们想要的效果,写个 demo 实验一下。
 图片
图片
5. 尝试一下上述代码的解码效果
 图片
图片
暗水印被完美解码出来了。至此,敲定使用这个方案替换原本的二极化解码方案。
原图色调选择
在尝试上面的混合模式方案时,有一点需要注意的。由于我们选择的混合模式是:overlay
 图片
图片
也就是让暗的更暗,亮的更亮。上面我们用的原始图片是偏亮色色调的,我们使用 #000 作为蒙层的色调可以让原本白色的水印更加凸显,但如果我们原本的图片本身是暗色色调的呢?我们使用 #000 会不会有问题呢?我们直接来试一下:
原图:
 图片
图片
解码图:
 图片
图片
上面的示例中,我们选择的模式是亮色背景的模式,但我们却传了一个暗色背景的图片,我们可以发现,完全看不见水印文字。这是因为此时,我们的水印文字已经由于跟蒙层背景融合的原因,导致跟背景色完全融合在一起了,所以我们看不见。
为了解决这个问题,我们可以在暗色背景是使用#fff作为蒙层的底纹色,这样,就可以让我们混合了蒙层颜色的水印凸显出来了:
 图片
图片
因此,我们需要改造一下上述的解码方法,让用户可以根据需要自行选择亮暗色调,以适应不同主色调的场景:
 图片
图片
当然,其实我们是有一些手段可以自动识别出当前图片的主色调的,利用自动识别的主色调进行自动匹配模式,就不需要用户自己选择了。不过目前因为我们C端页面大部分都是亮色的,实现这个功能必要性不大,暂且默认亮色,如果确实有需要自行切换模式即可。如果以后我们的页面支持暗色调页面,例如页面色调随系统变化时,我们就可以采用上述方案自动识别主色调。
自定义调节暗水印对比度
上面给出的代码中可以看到,我们在叠加蒙版的时候,这边使用了 for 循环叠加了4次,那么,究竟叠加多少次比较合适呢?一定要固定吗?
实则不然,我们其实可以让用户自行选择我们叠加的蒙版的层数,这样用户可以根据自己的需求通过调整叠加蒙版的层数来微调暗水印跟背景的对比度。
举个例子,当我们只选择叠加4层蒙版时,我们水印看起来非常淡,基本看不清楚(1~3的时候几乎看不怎么出来,这里就不演示了):
 图片
图片
而当我们将蒙层叠加数量调整到最高等级8时:
 图片
图片
水印的内容就已经相当明显了。
那么,是不是我们叠加蒙层的数量越多越好呢?其实也不是,如果我们的背景比较复杂的时候,如果蒙层叠加较多,可能会导致我们的水印文字与原图背景颜色过于接近而导致无法区分,因此,我们选择默认使用一个中间值,即默认叠加4层蒙版,如果实际效果觉得太淡,我们可以让使用者自行调整,这样就可以更好的适应各种情况了。
 图片
图片
优化至此,我们已经可以比较稳定的解析出无论是人眼还是OCR辨识度较高的包含暗水印的图片了。接下来,如果我们还想继续提升OCR模块识别的准确性,就要从OCR引擎上下功夫了。
OCR光学字符识别模块
同样的,在进行优化之前,我们首先要明确OCR模块的瓶颈究竟在哪里,我们才能针对瓶颈点进行针对性优化。
经过分析,总结出主要有以下三个瓶颈:
- 原始图片中的水印受到背景噪音干扰容易混淆(这个我们通过对暗水印解析模块的优化其实已经解决了绝大部分场景的问题了)。
- 图片中内容过多或体积过大,不仅会对识别准确性带来干扰,还影响OCR识别的速度。
- OCR针对相同的输入得到结果的准确性。
由于上述的第一个问题我们上面已经通过对暗水印解析模块的优化解决了,在此,我们就针对后两点聊一下应该如何优化。
选区识别解决背景噪音问题
既然问题是出在图片内容过多或体积过大上,那么我们就针对性的解决这个问题就可以了。那么,我们究竟应该选择如何减少图片内部的无关内容呢?
之前使用的二极化方案,可以将图片中很多复杂的像素点都变成纯粹的黑白色,从而减少一些干扰点,但也仅仅只是减少色调,如果图片中图形过于复杂,还是会造成极大的干扰,如:
 图片
图片
经过一番尝试,最终还是放弃了在二极化这条道路上一路走到黑的想法。而是选择了另一种方案,那就是参考飞书中的OCR功能,由人眼辨别图片当中那一块区域是干扰项最少的、最容易识别的区域,然后人工划定选取选择目标区域,而我们OCR识别的时候,也只需要识别选出来的选区中的内容即可,极大地降低了因图片背景噪音带来的识别准确率降低的可能性:
 图片
图片
决定了使用这个方案之后,又有一个问题让我犯难了,在一张图片中划定选取裁剪这个功能,说简单也简单,说复杂其实也挺复杂的,本着能不重复造轮子就不重复造轮子的思想,这边在网上一顿搜索,看是否有满足我需求的第三方库可以直接使用,最后,在npm上找到了:react-image-crop 这个库,试了一下,使用方便,而且完全可以满足我的需求,因此就直接安排上了。
 图片
图片
使用起来也简单,只需要用提供的React组件包裹待裁剪的组件即可:
 图片
图片
我们只需要在onComplete的回调当中,监听当前选中的区域和位置,然后将选中区域的图片裁剪下来:
 图片
图片
通过上面的代码处理,我们将会得到一个仅包含选区内容的图片base64,类似以下的图片:
 图片
图片
这样,就直接解决了图片过大和图片背景噪音过多造成的干扰了。
替换 OCR 识别方案
背景噪音问题解决之后,我们再来看一下,能否进一步的提升OCR的识别准确性,这边调研了三种方案:
- (上一版本采用此方案)使用 tesseract.js npm 包进行本地识别
优势
- 纯前端,不需要依赖外部服务
- 免费
- 接入简单
- 支持指定选取识别
劣势
整体体验下来识别精准度不高,肉眼几乎很明显的文字,容易识别错误
- 飞书的OCR API
识别准确率高
沟通成本比较大,需要联系公司商务跟飞书方谈
可能会产生一定的接口访问费用
接入比较麻烦,应该要注册飞书开发者平台获取 token
优势
劣势
- 公司算法中心的通用OCR服务
优势
- 公司内部接口,如果有定制化需求可以联系提供方定制开发
- 接入简单
- 在测试环境测试了一下,识别成功率挺高的,比npm包高
- 在支持了划定选取截图识别的情况下,由于图片体积整体比较小,识别速度反而比本地的npm包识别速度更快
劣势
目前测试环境接口好像不是很稳定,能识别出来的时候准确率很高,但有些时候,相同的输出,返回的结果却是空的。
由于使用本地npm识别准确率太低,而识别准确率最高的飞书API由于相关成本过高也只能无奈放弃,因此,这边最终选择主要使用第三个方案,即使用公司内部算法中心提供的通用OCR服务。
从测试接口看起来,这个服务的准确率还是可以的:
 图片
图片
因此,我们最终选择以内部OCR识别能力为主,tesseract.js 本地识别为辅的方案,尽可能的提供更加稳定且准确的OCR识别服务。
至此,我们本次针对OCR识别准确率的专项优化就算是完成了。
五、最后
到这里,我们本次针对截图搜功能的设计与识别准确率、体验优化就算是大功告成了,一个看似简单的水印功能,如果我们使用得当,研究深入,或许也能够在不同的应用场景当中产生不同的价值。个人认为,我们自己在开发过程中,别小瞧了某一些看似非常简单的功能,实际上它们或许是外表包着石皮的璞玉呢?在业务开发过程中,多一些对于技术的思考,对于业务的反思,或许能为我们展现出完全不一样的天地。