














对于推荐系统来说,会存在着“二八定律”,百分之二十的热门物料占据着百分之八十的用户交互,而推荐模型的目标是学习打分函数来预估用户对物料的偏好,并利用这个估计值进行排序。用户与物料的交互数据呈现长尾分布,而对观测数据做拟合的模型训练时会继承这个偏差,倾向于给热门物料更高的分数。如图所示,模型给用户推荐物料,用户在推荐列表上的行为作为训练数据用于模型的更新,形成了闭环。模型由此产生了流行度偏差(popular bias)。

流行度偏差
流行度偏差的存在并不完全对推荐系统有害,很多时候物料是因为自身高质量或者时下趋势而变得流行,盲目打击会破坏用户的体验。但是,如果偏差过强,不利于物料的分发和沉淀,也失去了推荐系统“千人千面”的定位。
我们在转转推荐中尝试结合因果推断来解决流行度偏差问题。本文首先讲解因果推断的基本概念,其次介绍因果推断在推荐系统中的一个代表性工作MACR,最后展示因果推断在转转场景下的探索。
1 因果推断简介
1.1 什么是因果
因果关系是一种普遍的关系,描述的是结果和产生这个结果的原因之间的关联。在因果关系中,因是导致事件发生的条件或行为,果则是这个原因导致的结果或变化。我们平时生活中到处都存在着因果问题,上大学是否会带来更多收入?直觉上我们认为高等教育会增加个人收入,但我们却很难说清楚没有上过大学的人如果上了大学会增加多少收入,同时我们也有看到没上过大学也能赚大钱的人。
我们常常会想,如果某一时刻做了另外的选择,是否生活会变得完全不一样呢。时光无法倒流,另一个选择的结果是永远不可知的,因果推断要做的事情就是去预估干预对结果的影响,判断一个“因”能导致多少“果”。
1.2 相关性不等于因果性
穿鞋睡觉和醒来头痛这两件事存在相关性,但是我们不能因此得出“穿鞋睡觉会导致醒来头痛”的结论,事实上,这两个事件都可能由第三个因素,即“睡前喝酒”导致的。这里“睡前喝酒”就是一个混杂因子,由此引起的关联被称为混杂关联,它会对同时出现的睡觉时穿鞋和头痛产生误导,让人误以为二者之间存在某种因果关系。

相关性不等于因果性
1.3 两种代表性的因果框架
1.3.1 结构因果模型
一般来说,结构因果模型(Structural causal model)将变量之间的因果关系抽象为因果图,建立结构函数,然后进行因果推理来评估交互效应或反事实条件的影响。
因果模型
因果模型涉及两个核心概念:因果图和结构函数。具体来说,因果图通过有向无环图(DAG)描述因果关系,其中节点代表变量,边代表因果关系。根据因果图,每个节点的值(准确说是内生节点)都可以通过一个关于其父节点的结构函数计算获得,从而知道干预某个节点对目标节点的影响。
三种典型的有向无环图

三种典型的有向无环图
如上图所示,因果图中有三种典型的结构:链式、叉式和对撞,我们针对每一种都以推荐系统为例进行解释。
在链式结构中,X通过Z间接影响Y。例如,在图(a)中,用户特征影响用户偏好,而用户偏好进一步影响用户的点击行为。
在叉式结构中,Z是一个混杂因子,影响X和Y。例如,在图(b)中,一个商品的质量可以影响其价格以及用户对其的偏好。在这种叉式结构中,Z被定义为混杂因子。粗略地忽略混杂因子Z可能导致X和Y在统计学上发生关联,产生伪相关性。质量好的商品通常更受欢迎,质量好的商品价格也更高,这不能证明价格高的商品更受欢迎。
在图(c)中,Z代表对撞,受X和Y影响。例如,用户的点击行为受用户偏好和商品流行度的影响。给定Y时,X和Z之间存在真相关性。也就是说,对于同样畅销的两个商品,用户是否点击只取决于他们的偏好。
干预

反事实

1.3.2 潜在结果框架
在进行因果推理时,除了前文提到的结构因果模型,还有一个被广泛使用的框架叫做“潜在结果框架”(Potential outcome framework)。潜在结果框架的特点是,它可以不依赖于因果图,直接估计某个变量(这里称为“干预变量”)对另一个变量(这里称为“结果变量”)的因果效应。
潜在结果

因果效应

2 MACR模型
2.1 背景
作者认为用户对某个物料的评分取决于三个方面,用户-物料匹配度(user-item matching)、物料流行度(item popularity)和用户从众度(user conformity)。现有的推荐模型主要关注用户-物料匹配度(图a),忽略了物料的流行度是如何影响交互概率的,假设两个物料对于一个用户有相同的匹配度,流行度较高的物料收集到反馈的更多,更有可能被用户所知(图b)。除此之外,有些用户更愿意跟随潮流,什么火就看什么,有些用户则不会,加入U->Y这条边能反应用户的流行敏感度偏差造成的估计偏差(图c)。

因果图1
文章提出了一个与模型无关的反事实推理框架(MACR),依据因果图训练推荐模型,并进行反事实推理,来消除推理阶段的流行度偏差(在训练时兼顾上面三种影响,预测时只考虑用户和物料的匹配度)。
2.2 反事实推理

因果图2

2.3 框架
理解了这三者的关系,我们来看文章提出的MACR框架,这个框架通过多任务学习进行训练,执行反事实推理进行无偏推荐。

MACR框架
这个框架遵循图c中的因果图,橙色部分表示传统的推荐系统,蓝色和绿色部分表示物料和商品的模块。框架可以用在任何现有的推荐模块中。


3 因果推断在转转场景下的实践
我们在首页默认tab进行了流行度偏差的debias实验,转转首页默认tab是一个多种物料共存的混合推荐场,其中商品维度上只有一个单独的点击率模型,便于我们观察实验效果。
3.1 实验一

因果图
一期方案我们的思路如因果图中的图一,商品的流行度不会对用户的偏好产生影响,这样流行度与用户的偏好对点击的影响就是线性的叠加。

实验一结构
我们采用了两阶段的训练方法,从使用的特征中选取了部分商品的静态属性特征(商品的类目、质检项等)作为bias特征,全部特征作为prefer特征。可以看到特征和网络结构都是完全独立的。
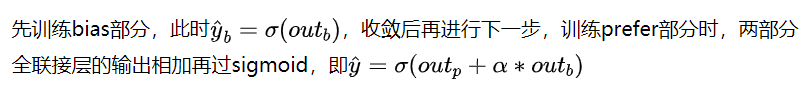
实验证明,该方案并无明显提升。
3.2 实验二
MACR模型因果图如图2所示,算法考虑了商品和用户两部分偏置对用户偏好带来的影响。参考MACR算法,我们考虑到二手平台用户行为的稀疏性,故暂时忽略用户偏置项,最终因果关系如图3所示。

实验二结构

AB实验在首页推荐整体取得了pctr+1.95%,uctr+0.70%的显著收益,同时缓解了商品的马太效应。
3.3 后续工作
- 使用因果推断进行曝光bias等多种bias的纠偏。
- 结合转转知识图谱和因果推断为具体业务提供指导。
参考文献
[1] Causal Inference in Recommender Systems: A Survey and Future Directions
[2] https://www.bradyneal.com/causal-inference-course
[3] Model-Agnostic Counterfactual Reasoning for Eliminating Popularity Bias in Recommender System
[4] 因果推断推荐系统工具箱 - MACR:https://www.jianshu.com/p/ffed9c9260e3
[5] 推荐系统流行度偏差专题:https://zhuanlan.zhihu.com/p/613111042






























