作者 | 汪昊
审校 | 重楼
推荐系统领域是一个子领域繁多,覆盖技术面广博的技术领域。因为推荐系统能给网站带来低成本流量从而极大的推动网站的发展,因此被各大互联网公司青睐。推荐系统团队和产品的维护费用,与推荐系统带来的经济收益相比,对大公司而言是微不足道的,因此几乎所有的大型互联网公司都给自己配备了推荐系统团队。

所有的推荐系统工程师在设计和搭建推荐系统的过程中,都会碰到冷启动问题。也就是当一个新用户或者新物品进入我们系统的时候,因为缺乏相关历史数据,所以没有办法给用户进行推荐。最简单的解决办法是推荐热门商品。近几年来流行的迁移学习和元学习算法,也是常见的解决冷启动问题的方式。
2021 年,ZeroMat 算法被中国科学家发明,这是人工智能历史上第一个非启发式,不利用迁移学习/元学习的零样本学习算法。该算法可以很好的解决推荐系统冷启动问题。随后DotMat、PoissonMat、RankMat、PowerMat 和 LogitMat 等一系列不需要数据就能进行推荐的零样本算法被相继提出。在 2024 年结束的国际学术会议 ICCAI 2024 上,中国科学家提出了零样本全序列排序学习算法。本文将带领读者学习该算法的细节,从而对该技术一探究竟。
作者首先回顾了全序列 Order Statistics 的公式。全序列的 Order Statistics 公式没有大多数人想象的那么复杂,它其实就是全概率公式乘以变量数的阶乘。而推荐系统的输入数据中,评分越高的物品,打分人数就越多,因此作者在这里用评分本身来代替评分的分布。比如,我们认为得分为 5 的电影的打分观众人数是得分为 1 的观众的 5 倍。而得分为 5 的电影,在评分数据集合中出现的次数也是得分为 1 的电影的 5 倍。作者用矩阵分解的方式近似用户物品评分。由此,我们得到下列损失函数:
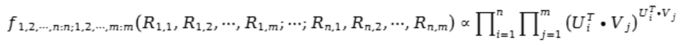
为了求解最大似然函数的参数,作者采用了随机梯度下降算法,因此得到了下列公式:
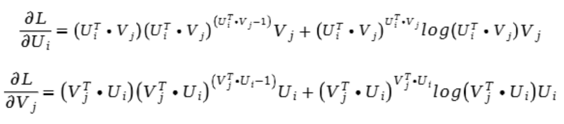
我们发现在上述公式中,没有出现历史数据,因此该算法是真正意义上的零样本学习算法。作者随后在 MovieLens 1 Million Dataset 和 LDOS-CoMoDa Dataset 两个数据集合上测试了算法的效果:
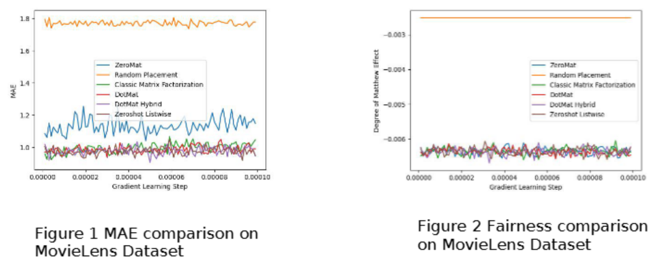
图 1 和 图 2 显示在 MovieLens 数据集合上,该算法性能优越,超过了经典的矩阵分解算法和其他零样本学习算法。
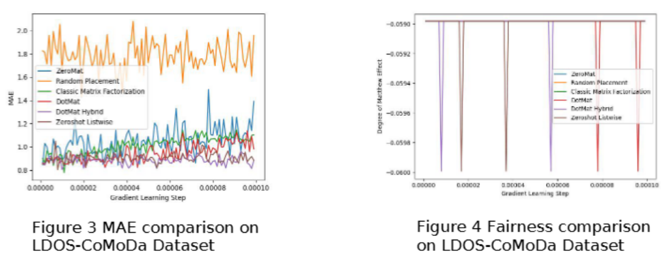
图 3 和 图 4 显示在 LDOS-CoMoDa 数据集合上,该算法性能优越,超过了经典的矩阵分解算法和其他零样本学习算法。
综上所述,我们发现该算法不仅实现简单,并且性能优越。值得每一个推荐系统从业者认真学习和积极关注。
论文名称:Zeroshot Listwise Learning to Rank Algorithm for Recommendation
论文下载地址:https://www.researchgate.net/publication/383585074_Zeroshot_Listwise_Learning_to_Rank_Algorithm_for_Recommendation
作者简介
汪昊,达评奇智董事长兼创始人。前 Funplus 人工智能实验室负责人。在 ThoughtWorks、豆瓣、百度、新浪、网易等公司有超过 13 年的技术和技术管理经验。精通推荐系统、风控反欺诈、聊天机器人和爬虫等领域。在国际学术会议和期刊发表论文 44 篇。5 次获得最佳论文奖/最佳论文报告奖。2006 年 ACM/ICPC 北美落基山区域赛金牌。