












大语言模型LLM因其庞大的参数规模,往往难以在消费级硬件上直接运行。这些模型的参数量可能达到数十亿级别(主要是权重),这些参数不仅存储成本高,推理阶段的计算量也很大。通常需要显存较大的GPU来加速推理过程。
因此,越来越多的研究开始关注如何缩小模型,比如改进训练方法或引入适配器模块。其中一项关键技术便是量化(quantization)。
本文将深入探讨量化的基本原理,介绍LLM.int8()大模型量化方法,并通过具体的代码实战来展示如何实现模型的量化,以便在各种设备上高效运行这些模型。

基础知识
1.数值表示
模型推理过程中,激活值是输入和权重之积,因此权重数量越多,激活值也会越大。

因此,我们需要尽可能高效表示数十亿个值,从而尽可能减少存储参数所需的空间。
大语言模型中参数数值,通常被表示为浮点数。浮点数(floating-point numbers,简称 floats)是一种用于表示带有小数点的正数或负数的数据类型。
在计算机科学中,浮点数通常遵循IEEE-754标准进行存储。这一标准定义了浮点数的结构,包括符号位、指数位和尾数位三个组成部分。其中,
- 符号位(Sign Bit):决定了浮点数的正负。
- 指数位(Exponent Bits):表示浮点数的指数部分。
- 尾数位(Fraction Bits):表示小数点后的数值部分。

三部分结合起来,即可根据一组bit值计算出所表示的数值。使用的位数越多,表示的数值值通常越精确。
- 半精度浮点数(Half-Precision Floats, FP16):使用16位来表示一个浮点数,其中包括1位符号位、5位指数位和10位尾数位。
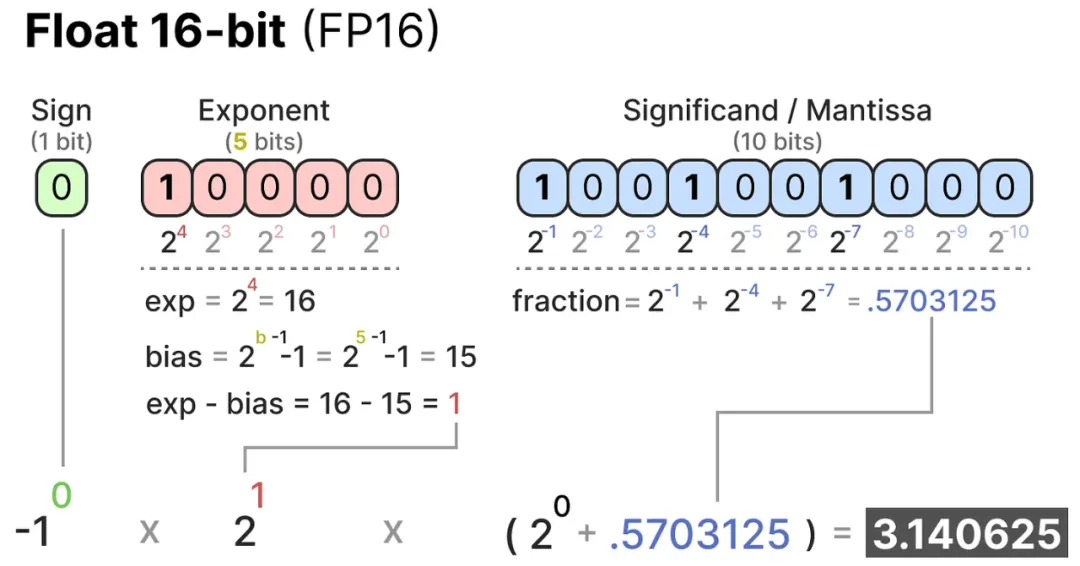
- 单精度浮点数(Single-Precision Floats, FP32):使用32位来表示一个浮点数,其中包括1位符号位、8位指数位和23位尾数位。

2.动态范围与精度
动态范围(Dynamic Range):指的是可表示的最大值与最小值之间的范围。可用的位数越多,动态范围也就越广。
精度(Precision):指两个相邻可表示值之间的差距。可用的位数越多,精度也就越高。

对于给定的浮点数表示形式,我们可以计算出存储特定数值所需的内存大小。例如,对于32位浮点数(FP32),每个数值占用4字节(8位/字节),而对于16位浮点数(FP16),每个数值占用2字节。
假设模型有N个参数,每个参数使用B位表示,则模型的内存需求(以字节为单位)可以用以下公式计算:
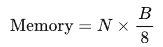
在实际应用中,除了模型本身的参数外,推理过程中的内存/显存需求还受到其他因素的影响,例如:
- 上下文大小:对于序列模型而言,处理的序列长度会影响内存需求。
- 模型架构:不同的模型架构可能会有不同的内存使用模式。
对于一个包含700亿参数的模型,如果使用32位浮点数表示,所需的内存为:
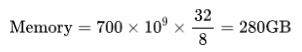
如果改为使用16位浮点数表示,所需的内存将减少一半:

由此可见,将模型参数的表示位数最小化,即量化(不仅是推理,还有训练过程)能够显著减少内存需求,但这也意味着精度的降低,可能会对模型的准确性产生负面影响。
「因此,量化技术的目标是在保持模型准确性的同时尽可能减少表示数值所需的位数。」
二、什么是模型量化?
所谓模型量化,其实就是将模型参数的精度从较高位宽(如FP16、FP32、BF16,一般是浮点运算)转换为较低位宽(如Int8、Int4,一般是整数运算),从而降低模型存储大小及显存占用、提升推理性能。

三、量化分类
模型量化可从以下几方面分类:
(1) 根据量化时机
- 训练时量化(Quantization-Aware Training, QAT),需要模型重新训练。
- 训练后量化(Post Training Quantization,PTQ),可以量化预训练好的模型。不需要重新训练。
(2) 根据映射函数是否为线性
- 线性量化
- 非线性量化
(3) 根据量化的粒度(共享量化参数的范围)
- Tensor粒度(per-tensor):整个矩阵一起量化。
- Token粒度(per-token)和Channel粒度(per-channel):每行/每列单独量化,X的每一行代表一个Token,W的每一列代表一个Channel。
- Group粒度(per-group):两者的折衷,多行/多列分为一组,每组分别量化。
(4) 根据量化范围
- 只量化权重(Weight Only):只量化模型权重,推理时是INT乘FLOAT。
- 权重与激活同时量化(Weight and Activation):这里的激活实际是就是每一层的输入,对于矩阵乘法Y = WX,同时量化W和X,推理时是INT乘INT。
目前Weight and Activation可以做到Int8(或者叫W8A8,Weight 8bit Activition 8bit)与FP16水平相当,而Weight Only方向INT4(W4A16)已经可以做到与FP16相差无几,INT3(W3A16)也很接近了。实际上,这两个方向并不是互斥的,我们完全可以同时应用两种方式,只是工程比较复杂,暂时还没有成熟的框架。
❞
(5) 根据存储一个权重元素所需的位数
- 8bit量化
- 4bit量化
- 2bit量化
- 1bit量化
四、量化方案
1.LLM.int8()
(1) LLM.int8()量化算法
INT8量化的基本思想是将浮点数 通过缩放因子scale映射到范围在[-128, 127]内的8位整数表示
通过缩放因子scale映射到范围在[-128, 127]内的8位整数表示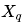 。
。
量化公式如下:

其中:
- Xq表示量化后的整数。
- Xf表示量化前的浮点数。
- scale表示缩放因子。
- Round 表示四舍五入为整数。
- Clip表示将结果截断到[-128, 127]范围内。
缩放因子scale的计算公式:
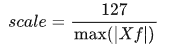
其中, 表示浮点数最大绝对值。
表示浮点数最大绝对值。
反量化的过程为:

如下图所示为通过该方式实现量化-反量化的示例。假设使用absmax quantization技术对向量[1.2, -0.5, -4.3, 1.2, -3.1, 0.8, 2.4, 5.4]进行量化。首先找到绝对值最大值5.4。Int8的取值范围是[-127, 127],所以量化因子为127/5.4=23.5。因此向量会被量化成[28, -12, -101, 28, -73, 19, 56, 127]。

为了还原原始值,可以使用全精度的int8数值除以量化因子23.5。但是它们在量化过程中是四舍五入取整过的,会损失一些精度。
为了不区分int8格式的正负符号,我们需要减去最小值,然后再使用最大值作为量化因子。具体实现如下:
对于给定的向量或矩阵,首先找到最小值 ,并减去最小值:
,并减去最小值:

找到X'的绝对最大值 ,使用绝对最大值作为量化因子:
,使用绝对最大值作为量化因子:

这类似于zero-point量化,但不同之处在于,zero-point量化会确保全精度数值0仍然转换为整数0,从而在数值0处保证不会有量化损失。
LLM.int8()算法的具体步骤:
- 从矩阵隐藏层中,以列为单位,抽取值大于确定阈值的异常值(outliers)。
- 分别通过FP16精度对outliers的部分做矩阵乘法,通过量化int8精度对其他的做矩阵乘法。
- 将量化的部分恢复成FP16,然后将两部分合在一起。

「为什么要单独抽出异常值(outliers)?」
在大规模模型中,数值超出全局阈值范围的被称为outliers。8位精度的数据是压缩的,因此量化一个含有几个大数值的向量会导致大量错误的结果。例如,如果一个向量中有几个数值远大于其他数值,那么量化这些数值会导致其他数值被压缩到零,从而产生较大的误差。
Transformer 架构的模型会将所有的内置特征连接组合在一起。因此,这些量化错误会在多层网络的传播中逐步混合在一起,导致整体性能的下降。
为了解决这些问题,混合精度量化技术应运而生。这种技术将大数值的特征拆分出来,进行更有效的量化和混合精度计算。
(2) LLM.int8()量化实现
如下是在Transformers库中集成nuances库,利用bitsandbytes库提供的8位量化功能,将模型转换为int8精度。
第一步:导入库
import torch
import torch.nn as nn
import bitsandbytes as bnb
from bnb.nn import Linear8bitLt在自己的数据集和任务上训练模型了,最后保存模型定义自己的模型。可以从任何精度(FP16,BF16,FP32)转换至int8。但模型的输入需要是FP16精度。所以下面为FP16精度的模型。
fp16_model = nn.Sequential(
nn.Linear(64, 64),
nn.Linear(64, 64)
)第三步:在自己的数据集和任务上训练模型,最后保存模型
# 训练模型
[... train the model ...]
# 保存模型
torch.save(fp16_model.state_dict(), "model.pt")第四步:定义一个int8精度的模型。
int8_model = nn.Sequential(
Linear8bitLt(64, 64, has_fp16_weights=False),
Linear8bitLt(64, 64, has_fp16_weights=False)
)这里加入has_fp16_weights的参数是很重要的。因为它默认会被设置为True,这意味着它会被作为Int8/FP16混合精度训练。然而,我们关心的是use has_fp16_weights=False时的计算内存占用。
第五步:加载模型并量化至int8精度。
int8_model.load_state_dict(torch.load("model.pt"))
int8_model = int8_model.to(0) # 量化int8_model = int8_model.to(0) 将模型存入显卡,会执行量化。
如果在其之前打印int8_model[0]的权重,可得到FP16的精度值。
print("Before quantization:")
print(int8_model[0].weight)
Parameter containing:
tensor([[ 0.0031, -0.0438, 0.0494, ..., -0.0046, -0.0410, 0.0436],
[-0.1013, 0.0394, 0.0787, ..., 0.0986, 0.0595, 0.0162],
[-0.0859, -0.1227, -0.1209, ..., 0.1158, 0.0186, -0.0530],
...,
[ 0.0804, 0.0725, 0.0638, ..., -0.0487, -0.0524, -0.1076],
[-0.0200, -0.0406, 0.0663, ..., 0.0123, 0.0551, -0.0121],
[-0.0041, 0.0865, -0.0013, ..., -0.0427, -0.0764, 0.1189]],
dtype=torch.float16)如果在其之后打印int8_model[0]的权重,可得到INT8的精度值。
print("After quantization:")
print(int8_model[0].weight)
Parameter containing:
tensor([[ 3, -47, 54, ..., -5, -44, 47],
[-104, 40, 81, ..., 101, 61, 17],
[ -89, -127, -125, ..., 120, 19, -55],
...,
[ 82, 74, 65, ..., -49, -53, -109],
[ -21, -42, 68, ..., 13, 57, -12],
[ -4, 88, -1, ..., -43, -78, 121]],
device='cuda:0', dtype=torch.int8, requires_grad=True)由此可见,权重值被压缩了,分布在[-127,127]之间。
如需恢复FP16精度,则:
print("Restored FP16 precision:")
print((int8_model[0].weight.CB * int8_model[0].weight.SCB) / 127)然后得到:
tensor([[ 0.0028, -0.0459, 0.0522, ..., -0.0049, -0.0428, 0.0462],
[-0.0960, 0.0391, 0.0782, ..., 0.0994, 0.0593, 0.0167],
[-0.0822, -0.1240, -0.1207, ..., 0.1181, 0.0185, -0.0541],
...,
[ 0.0757, 0.0723, 0.0628, ..., -0.0482, -0.0516, -0.1072],
[-0.0194, -0.0410, 0.0657, ..., 0.0128, 0.0554, -0.0118],
[-0.0037, 0.0859, -0.0010, ..., -0.0423, -0.0759, 0.1190]],
device='cuda:0')这和原始的FP16精度权重非常接近。
第六步:在同一个显卡上用FP16精度计算模型。
input_ = torch.randn(64, dtype=torch.float16)
hidden_states = int8_model(input_.to(torch.device('cuda', 0)))第七步:集成到Transformer库。
使用accelerate库初始化模型。当处理大型模型时,accelerate库提供了很多便利,特别是在内存管理和模型初始化方面。init_empty_weights方法可以帮助任何模型在初始化时不占用任何内存。
import torch.nn as nn
from accelerate import init_empty_weights
with init_empty_weights():
model = nn.Sequential([nn.Linear(100000, 100000) for _ in range(1000)]) # This will take ~0 RAM!修改.from_pretrained。当调用函数.from_pretrained时,会内置将所有参数调用torch.nn.Parameter,这不符合功能模块Linear8bitLt。因此,将Actor生成的
module._parameters[name] = nn.Parameter(module._parameters[name].to(torch.device("meta")))修改为:
param_cls = type(module._parameters[name])
kwargs = module._parameters[name].__dict__
module._parameters[name] = param_cls(module._parameters[name].to(torch.device("meta")), **kwargs)替换 nn.Linear 层为 Linear8bitLt 层
def replace_8bit_linear(model, threshold=6.0, module_to_not_convert="lm_head"):
for name, module in model.named_children():
if len(list(module.children())) > 0:
replace_8bit_linear(module, threshold, module_to_not_convert)
if isinstance(module, nn.Linear) and name != module_to_not_convert:
with init_empty_weights():
model._modules[name] = bnb.nn.Linear8bitLt(
module.in_features,
module.out_features,
module.bias is not None,
# 参数has_fp16_weights需要被设置为False,从而直接加载模型权重为int8精度。
has_fp16_weights=False,
threshold=threshold
)
return modelmodel = replace_8bit_linear(model, threshold=6.0)




























