本文作者来自于清华大学电子工程系,北京大学人工智能研究院、第四范式、腾讯和清华-伯克利深圳学院。其中第一作者张瑞泽为清华大学硕士,主要研究方向为博弈算法。通讯作者为清华大学电子工程系汪玉教授、于超博后和第四范式研究员黄世宇博士。
自博弈(self-play)指的是智能体通过与自身副本或历史版本进行博弈而进行演化的方法,近年来在强化学习领域受到广泛重视。这篇综述首先梳理了自博弈的基本背景,包括多智能体强化学习框架和博弈论的基础知识。随后,提出了一个统一的自博弈算法框架,并在此框架下对现有的自博弈算法进行了分类和对比。此外,通过展示自博弈在多种场景下的应用,架起了理论与实践之间的桥梁。文章最后总结了自博弈面临的开放性挑战,并探讨了未来研究方向。

- 论文题目:A Survey on Self-play Methods in Reinforcement Learning
- 研究机构:清华大学电子工程系、北京大学人工智能研究院、第四范式、腾讯、清华-伯克利深圳学院
- 论文链接:https://arxiv.org/abs/2408.01072
引言
强化学习(Reinforcement Learning,RL)是机器学习中的一个重要范式,旨在通过与环境的交互不断优化策略。基本问题建模是基于马尔可夫决策过程(Markov decision process,MDP),智能体通过观察状态、根据策略执行动作、接收相应的奖励并转换到下一个状态。最终目标是找到能最大化期望累计奖励的最优策略。
自博弈(self-play)通过与自身副本或过去版本进行交互,从而实现更加稳定的策略学习过程。自博弈在围棋、国际象棋、扑克以及游戏等领域都取得了一系列的成功应用。在这些场景中,通过自博弈训练得到了超越人类专家的策略。尽管自博弈应用广泛,但它也伴随着一些局限性,例如可能收敛到次优策略以及显著的计算资源需求等。
本综述组织架构如下:首先,背景部分介绍了强化学习框架和基础的博弈论概念。其次,在算法部分提出了一个统一的框架,并根据该框架将现有的自博弈算法分为四类,进行系统的比较和分析。在之后的应用部分中,展示自博弈具体如何应用到具体的复杂博弈场景。最后,进一步讨论了自博弈中的开放问题和未来的研究方向,并进行总结。
背景
该部分分别介绍了强化学习框架以及博弈论基本知识。强化学习框架我们考虑最一般的形式:部分可观察的马尔可夫博弈(partially observable Markov game, POMGs),即多智能体场景,且其中每个智能体无法完全获取环境的全部状态。
博弈论基础知识介绍了博弈具体类型,包括(非)完美信息博弈和(非)完全信息博弈、标准型博弈和扩展型博弈、传递性博弈和非传递性博弈、阶段博弈和重复博弈、团队博弈等。同样也介绍了博弈论框架重要概念包括最佳回应(Best responce, BR)和纳什均衡 (Nash equilibrium, NE)等。
复杂的博弈场景分析通常采用更高层次的抽象,即元博弈(meta-game)。元博弈关注的不再是单独的动作,而是更高层的复杂策略。在这种高层次抽象下,复杂博弈场景可以看作是特殊的标准型博弈,策略集合由复杂策略组成。元策略(meta-strategies)是对策略集合中的复杂策略进行概率分配的混合策略。
在该部分最后,我们介绍了多种常用的自博弈评估指标,包括 Nash convergence(NASHCONV)、Elo、Glicko、Whole-History Rating(WHR) 和 TrueSkill。
算法
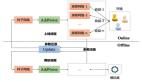
我们定义了一个统一的自博弈框架,并将自博弈算法分为四大类:传统自博弈算法、PSRO 系列算法、基于持续训练的系列算法和后悔最小化系列算法。
算法框架

首先,该框架(算法1)的输入定义如下:
● : 在策略集合 中,每个策略 都取决于一个策略条件函数 。
● : 策略集合的交互矩阵。 描述了如何为策略 采样对手。例如, 可以用每个对手策略采样概率表示(此时 如下图所示)。

● : 元策略求解器(Meta Strategy Solver,MSS)。输入是表现矩阵 ,并生成一个新的交互矩阵 作为输出。 表示策略 的表现水平。
该框架(算法1)的核心步骤说明:
● 算法1伪代码第1行: 表示整个策略集合的总训练轮数,也即策略池中每个策略的更新次数。
● 算法1伪代码第3行:各个策略初始化可以选择随机初始化、预训练模型初始化或者是继承之前训练完成的策略进行初始化。
● 算法1伪代码第4行:可以选用不同的 ORACLE 算法得到训练策略,最直接的方式是计算 BR 。但是由于对于复杂任务来说,直接计算 BR 难度高,因此通常选择训练近似BR来训练策略,可以采用强化学习(算法2),进化算法(算法3),后悔最小化(算法4)等方法。



类型一:传统自博弈算法
传统自博弈算法从单一策略开始,逐步扩展策略池,包括Vanilla self-play(训练时每次对手都选择最新生成的策略),Fictitious self-play(训练时每次对手都在现有训练完的策略中均匀采样),δ-uniform self-play(训练时每次对手都在现有训练完的最近的百分之δ策略中均匀采样),Prioritized Fictitious Self-play(根据优先级函数计算当前训练完的策略的优先级,训练时每次对手都根据这个优先级进行采样),Independent RL(训练时双方策略都会改变,对手策略不再固定)。
类型二:PSRO 系列算法
类似于传统自博弈算法,Policy-Space Response Oracle(PSRO)系列算法同样从单一策略开始,通过计算 ORACLE 逐步扩展策略池,这些新加入的策略是对当前元策略的近似 BR 。PSRO 系列与传统自博弈算法的主要区别在于,PSRO 系列采用了更复杂的MSS,旨在处理更复杂的任务。例如,α-PSRO 使用了基于 α-rank 的 MSS 来应对多玩家的复杂博弈。
类型三:持续训练系列算法
PSRO 系列算法中存在的两个主要挑战:首先,由于训练成本大,通常在每次迭代中截断近似BR计算,会将训练不充分的策略添加到策略池;其次,在每次迭代中会重复学习基本技能,导致效率较低。为了解决这些挑战,基于持续训练系列的算法提倡反复训练所有策略。与前面提到的两类最大区别是,持续训练系列算法同时训练整个策略池策略。这类算法采用多个训练周期,并在每个训练周期内依次训练策略池所有策略,而不再是通过逐步扩展策略池进行训练。
类型四:后悔最小化系列算法
另一类自博弈算法是基于后悔最小化的算法。基于后悔最小化的算法与其他类别的主要区别在于,它们优先考虑累积的长期收益,而不仅仅关注单次回合的表现。这种方法可以训练得到更具攻击性和适应性的策略,避免随着时间的推移被对手利用。这些算法要求玩家在多轮中推测并适应对手的策略。这种情况通常在重复博弈中观察到,而不是单回合游戏中。例如,在德州扑克或狼人游戏中,玩家必须使用欺骗、隐瞒和虚张声势的策略,以争取整体胜利,而不仅仅是赢得一局。
各类型算法比较与总结图

应用
在本节中,我们通过将三类经典场景来介绍自博弈的经典应用:棋类游戏,通常涉及完全信息;牌类游戏(包括麻将),通常涉及不完全信息;以及电子游戏,具有实时动作而非简单回合制游戏。
场景一:棋类游戏
棋类游戏领域,绝大多数是完全信息游戏,曾因引入两项关键技术而发生革命性变化:位置评估和蒙特卡罗树搜索。这两项技术在象棋、西洋跳棋、黑白棋、西洋双陆棋等棋盘游戏方面展现了超越人类的效果。相比之下,当这些技术应用于围棋时,由于围棋棋盘布局种类远超于上述提到的棋类游戏,因此仅能达到业余水平的表现。直到 DeepMind 推出了 AlphaGo 系列而发生了革命性的变化,AlphaGo 系列算法利用自博弈的强大功能显著提升了性能,为围棋领域设立了新的基准。
除了围棋,还有一种难度较高的棋类游戏是“军棋”(Stratego)。与大多数完全信息的棋类游戏不同,“军棋”是一个两人参与的不完全信息棋盘游戏。游戏分为两个阶段:部署阶段,玩家秘密安排他们的单位,为战略深度奠定基础;以及游戏阶段,目标是推断对手的布局并夺取他们的旗帜。DeepNash 采用基于进化的自博弈算法 R-NaD 达到了世界第三的人类水平。
场景二:牌类游戏
德州扑克(Texas Hold’em)是一种欧美流行的扑克游戏,适合 2 到 10 名玩家,当玩家数量增加,游戏变得更加复杂。此外,有三种下注形式:无限注、固定注和底池限注。每种形式在具有不同的游戏复杂度。在牌类游戏中,游戏抽象对于简化游戏复杂程度至关重要,可以将游戏的庞大状态空间减少到更容易处理的数量。Cepheus 采用后悔最小化系列算法 CFR+ 解决了最容易的双人有限注德州扑克。对于更复杂的双人无限注德州扑克,DeepStack 和 Libratus 采用子博弈重新计算的方式来实时做出决策,击败职业德州扑克选手。Pluribus 在 Libratus 基础上更进一步解决了六人无限注德州扑克。
斗地主需要同时考虑农民之间的合作和农民地主之间的竞争。斗地主同样是不完全信息博弈,这为游戏增加了不确定性和策略深度。DeltaDou 是基于 AlphaZero 开发的首个实现专家级斗地主表现的算法。之后的 DouZero 通过选择采样方法而非树搜索方法来降低训练成本,采用自博弈获取训练数据。
麻将同样基于不完全信息做出决策,此外,麻将的牌数更多,获胜牌型也更为复杂,对 AI 更具挑战性。Suphx 通过监督学习和自我博弈强化学习成为首个达到与人类专家水平的算法。NAGA 和腾讯设计的 LuckyJ 同样也在在线平台上达到了人类专家水平。
场景三:电子游戏
与传统棋类游戏和牌类游戏不同,电子游戏通常具有实时操作、更长的动作序列以及更广泛的动作空间和观察空间。在星际争霸(StarCraft)中,玩家需要收集资源、建设基地并组建军队,通过精心的计划和战术执行,使对方玩家失去所有建筑物,来取得胜利。AlphaStar 使用监督学习、端到端的强化学习和分层自博弈训练策略,在星际争霸II的 1v1 模式比赛中击败了职业玩家。
MOBA游戏要求两支玩家队伍各自操控他们独特的英雄,互相竞争以摧毁对方的基地。每个英雄都有独特的技能,并在队伍中扮演特定的角色,也无法观测全部地图。OpenAI Five 在简化版本的 Dota 2 中击败了世界冠军队,其训练过程使用混合类型自博弈,有 80% 的概率进行 Naive self-play,20% 的概率使用 Prioritized self-play。腾讯同样采用自博弈训练在王者荣耀游戏 1v1 和 5v5 模式中都击败了职业选手。
Google Research Football(GRF)是一个开源的足球模拟器,输入是高层次的动作,需要考虑队友之间的合作和两个队伍之间的竞争,且每队有 11 人。TiKick 通过 WeKick 的自博弈数据进行模仿学习,再利用分布式离线强化学习开发了一个多智能体AI。TiZero将课程学习与自博弈结合,无需专家数据,达到了比TiKick更高的TrueSkill评分。
各场景类型比较与总结图

讨论
自博弈方法因其独特的迭代学习过程和适应复杂环境的能力而表现出卓越的性能,然而,仍有不少方向值得进一步研究。
虽然许多算法在博弈论理论基础上提出,但在将这些算法应用于复杂的现实场景时,往往存在理论与现实应用的差距。例如,尽管 AlphaGo、AlphaStar 和 OpenAI Five 在实证上取得了成功,但它们的有效性缺乏正式的博弈论证明。
随着团队数量和团队内玩家数量的增加,自博弈方法的可扩展性面临显著挑战。例如,在 OpenAI Five 中,英雄池的大小被限制在仅17个英雄。根本上是由于自博弈方法在计算和存储两个方面训练效率有限:由于自博弈的迭代特性,智能体反复与自身或过去的版本对战,因而计算效率较低;自博弈需要维护一个策略池,因而对存储资源需求较高。
凭借卓越的能力和广泛的泛化性,大型语言模型(LLM)被认为是实现人类水平智能的潜在基础。为了减少对人工标注数据的依赖,自博弈方法被利用到微调LLM来增强LLM的推理性能。自博弈方法还在构建具有强大战略能力的基于 LLM 的代理方面做出了贡献,在”外交“游戏中达到了人类水平的表现。尽管近期取得了一些进展,将自博弈应用于 LLM 仍处于探索阶段。
自我博弈面另一个挑战是其在现实具身场景中无法直接应用。其迭代特性需要大量的试验和错误,很难直接在真实环境中完成。因此,通常只能在仿真器中进行自博弈训练,再将自博弈有效部署到现实具身场景中,关键问题仍在于克服 Sim2Real 差距。