译者 | 李睿
审校 | 重楼
RAG系统包含两个核心组件:检索器和生成器,本文将介绍如何评估这两个组件。
检索增强型生成(RAG)系统被设计用来提升大型语言模型(LLM)的响应质量。当用户提交查询时,RAG系统从向量数据库中提取相关信息,并将其作为场景传递给LLM。然后,LLM使用这个场景为用户生成响应。这一过程显著提高了LLM反应的质量,减少了“幻觉”。

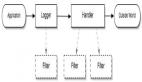
图1 RAG系统工作流程
在图1的工作流程中,RAG系统中有两个主要组件:
- 检索器:它利用相似度搜索的能力从向量数据库中识别出与用户查询最相关的信息。这一阶段是任何RAG系统中最关键的部分,因为它为最终输出的质量奠定了基础。检索器会在向量数据库中搜索与用户查询相关的文档。这包括将查询和文档编码为向量,并使用相似性度量来查找最接近的匹配。
- 响应生成器:一旦检索到相关文档,用户查询和检索到的文档将被传递给LLM模型,以生成连贯的、相关的和信息丰富的响应。生成器(LLM)使用检索器提供的场景和原始查询来生成准确的响应。
任何RAG系统的有效性和性能在很大程度上取决于这两个核心组件:检索器和生成器。检索器必须有效地识别和检索最相关的文档,而生成器应该使用检索到的信息生成连贯、相关和准确的响应。在部署之前,对这些组件进行严格的评估对于确保RAG模型的最佳性能和可靠性至关重要。
一、评估RAG
为了评估RAG系统,通常使用两种评估方法:
- 检索评估
- 响应评估
与传统的机器学习技术不同,RAG系统的评估更为复杂,具有明确的定量指标(例如基尼系数、R平方、AIC、BIC、混淆矩阵等)。出现这种复杂性是因为RAG系统生成的响应是非结构化文本,需要定性和定量指标的结合来准确评估它们的性能。
TRIAD框架
为了有效地评估RAG系统,通常遵循TRIAD框架。该框架由三个主要部分组成:
- 场景相关性:该组件评估RAG系统的检索部分。它评估从大型数据集检索文档的准确性。这里使用精确率、召回率、MRR和MAP等指标。
- 忠诚度(具有依据):该部分属于响应评估范畴。它检查生成的响应是否真实准确,是否以检索到的文档为依据。评估忠诚度可以采用人工评估、自动化事实核查工具和一致性检查等方法。
- 答案相关性:这也是响应评估的一部分。它衡量生成的响应如何处理用户的查询并提供有用的信息。使用了BLEU、ROUGE、METEOR和基于嵌入的评估等指标。

图2 RAG TRIAD
二、检索评估
检索评估应用于RAG系统的检索组件,该系统通常使用向量数据库。这些评估衡量检索器在响应用户查询时识别相关文档并对其进行排序的有效性。检索评估的主要目标是评估场景相关性,即检索到的文档与用户查询的一致程度。它确保提供给生成组件的场景是相关的和准确的。

图3 场景相关性
每个指标都对检索到的文档的质量提供了独特的视角,并有助于对场景相关性的全面理解。
精确率
精确率衡量检索到的文档的准确性。它是检索到的相关文档的数量与检索到的文档总数的比率。其定义是:

图4 精确率公式
这意味着精确率评估系统检索的文档中有多少实际上与用户的查询相关。例如,如果检索器检索10个文档,其中7个是相关的,则精确率为0.7或70%。
精确率评估的是,“在系统检索的所有文档中,有多少是实际相关的?”
当呈现不相关的信息可能产生负面后果时,准确性尤为重要。例如,医疗信息检索系统的高精度是至关重要的,因为提供无关的医疗文件可能会导致错误信息和潜在的有害结果。
召回率
召回率衡量检索文档的全面性。它是针对给定查询检索到的相关文档的数量与数据库中相关文档的总数之比。其定义是:

图5 召回率公式
这意味着召回率评估系统成功检索到数据库中存在的相关文档的数量。
召回率评估的是,“在数据库中存在的所有相关文档中,系统设法检索了多少个?”
在错过相关信息可能代价高昂的情况下,召回率至关重要。例如,在法律信息检索系统中,召回率高至关重要,因为未能检索到相关法律文件可能会导致案例研究不完整,并可能影响法律诉讼的结果。
精确率和召回率之间的平衡
精确率和召回率的平衡通常是必要的,因为提高其中一个有时会降低另一个指标。目标是找到适合应用程序特定需求的最佳平衡。这种平衡有时用F1评分来量化,这是精确率和召回率的调和平均值:

图6 F1评分公式
平均倒数排名(MRR)
平均倒数排名(MRR)是一种通过考虑第一个相关文档的排名位置来评估检索系统有效性的度量。当只对第一个相关文件感兴趣时,它特别有用。倒数排名是第一个相关文档被找到的排名的倒数。MRR是在多个查询中这些相互排名的平均值。MRR的公式为:

图7 MRR公式
其中Q是查询的数量,是第Q个查询的第一个相关文档的排名位置。
MRR评估的是,“平均而言,响应用户查询检索第一个相关文档的速度有多快?”
例如,在基于RAG的问答系统中,MRR至关重要,因为它反映了系统向用户呈现正确答案的速度。如果正确答案出现在列表顶部的频率越高,则MRR值越高,表明检索系统更有效。
平均精度(MAP)
平均精度(MAP)是一个衡量多个查询检索精度的指标。它同时考虑了检索的精度和检索文档的顺序。MAP被定义为一组查询的平均精度得分的平均值。为了计算单个查询的平均精度,在检索到的文档排名列表中的每个位置计算精度,仅考虑前K个检索到的文件,其中每个精度都根据文件是否相关进行加权。跨多个查询的MAP公式为:

图8 MAP公式
其中(Q)为查询数量,是查询(Q)的平均精度。
MAP评估的是,“平均而言,系统在多个查询中检索到的排名靠前的文档有多精确?”
例如,在基于RAG的搜索引擎中,MAP至关重要,因为它考虑了不同级别的检索精度,确保相关文档在搜索结果中出现在更高的位置,从而通过首先呈现最相关的信息来增强用户体验。
检索评估综述
- 精确率:检索结果的质量
- 召回率:检索结果的完整性
- MRR:检索第一个相关文档的速度
- MAP:结合相关文件的精度和排名的综合评估
三、响应评估
响应评估应用于系统的生成组件。这些评估衡量系统基于检索文档提供的场景生成响应的效率。将响应评估分为两类:
- 忠诚度(具有依据)
- 答案相关性
忠诚度(具有依据)
忠诚度评估生成的响应是否准确、是否基于检索到的文档,它确保反应不包含幻觉或不正确的信息。这个指标是至关重要的,因为它将生成的响应追溯到其来源,确保信息基于可验证的基本事实。忠诚度有助于防止“幻觉”,即系统产生听起来似乎合理但实际上不正确的反应。
为了衡量忠诚度,常用的方法有以下几种:
- 人工评估:专家人工评估生成的响应是否准确,是否正确地引用了检索到的文档。该过程包括对照源文件检查每个回复,以确保所有声明都得到证实。
- 自动事实检查工具:这些工具将生成的响应与经过验证的事实数据库进行比较,以识别不准确之处。它们提供了一种无需人工干预即可自动检查信息有效性的方法。
- 一致性检查:这些检查评估模型是否在不同查询中一致地提供相同的事实信息。这确保了模型的可靠性,并且不会产生相互矛盾的信息。
答案相关性
答案相关性衡量生成的响应在多大程度上解决了用户的查询并提供了有用的信息。
(1)BLEU(双语评估替补)
BLEU衡量生成的响应和一组参考响应之间的重叠,重点关注n元语法(n-gram)的精度。它是通过衡量生成的响应和参考响应之间的n-gram(n个单词的连续序列)的重叠来计算的。BLEU评分公式为:

图9 BLEU公式
其中(BP)是简短性惩罚,用于惩罚过短的回答,(P_n)是n-gram的精度,(w_n)是每个n-gram级别的权重。BLEU从数量上衡量生成的响应与参考响应的匹配程度。
(2)ROUGE(基于召回的Gisting评估研究)
ROUGE衡量生成响应和参考响应之间n-gram、单词序列和单词对的重叠,同时考虑召回率和精确率。最常见的变体ROUGE-N衡量生成响应和参考响应之间n-grams的重叠。ROUGE-N的公式为:

图10 MAP公式
ROUGE评估精确度和召回率,提供一个平衡的衡量标准,衡量生成的响应中引用的相关内容有多少。
(3)METEOR(带有显式排序的翻译评价度量)
METEOR考虑同义词、词干和词序来评估生成的响应和参考响应之间的相似性。METEOR分数的公式为:

图11 METEOR公式
其中$F_{\text{mean}}$是精确率和召回率的调和均值,是对不正确的词序和其他错误的惩罚。METEOR通过考虑同义词和词干,提供了比BLEU或ROUGE更细致的评估。
(4)基于嵌入的评估
该方法使用词的向量表示(嵌入)来衡量生成响应和参考响应之间的语义相似度。余弦相似度等技术用于比较嵌入,根据单词的含义而不是它们的精确匹配提供评估。
四、优化RAG系统的提示和技巧
可以使用一些基本提示和技巧来优化RAG系统:
使用重新排序技术
重新排序是优化任何RAG系统性能的最广泛使用的技术。它获取最初的检索文档集,并根据它们的相似性进一步对最相关的文档进行排序。可以使用交叉编码器和基于BERT的重新排序器等技术更准确地评估文档相关性。这确保提供给生成器的文档场景丰富且高度相关,从而得到更好的响应。
调整超参数
定期调整块大小、重叠和顶级检索文档的数量等超参数可以优化检索组件的性能。尝试不同的设置并评估它们对检索质量的影响可以提高RAG系统的整体性能。
嵌入模型
选择合适的嵌入模型对于优化RAG系统的检索组件至关重要。正确的模型,无论是通用的还是特定领域的,都可以显著增强系统准确表示和检索相关信息的能力。通过选择与特定用例相一致的模型,可以提高相似性搜索的精度和RAG系统的整体性能。在做出选择时,考虑模型的训练数据、维度和性能指标等因素。
分块策略
通过为LLM捕获更多相关信息,定制块大小和重叠可以显著地提高RAG系统的性能。例如,LangChain的语义分块基于语义拆分文档,确保每个块在场景上是一致的。根据文档类型(例如PDF、表格和图像)而变化的自适应分块策略可以帮助保留更适合场景的信息。
向量数据库在RAG系统中的作用
向量数据库是RAG系统性能的主要组成部分。当用户提交查询时,RAG系统的检索器组件利用向量数据库根据向量相似性找到最相关的文档。这个过程对于为语言模型提供正确的场景以生成准确和相关的响应至关重要。强大的向量数据库可确保快速准确的检索,直接影响RAG系统的整体有效性和响应性。
结论
开发RAG系统本身并不困难,但评估RAG系统对于衡量性能、实现持续改进、与业务目标保持一致、平衡成本、确保可靠性和适应新方法至关重要。这种全面的评估过程有助于构建健壮、高效和以用户为中心的RAG系统。
通过解决这些关键方面的问题,向量数据库成为高性能RAG系统的基础,使它们能够在有效管理大规模复杂数据的同时提供准确、相关和及时的响应。
原文标题:The Ultimate Guide To Evaluate RAG System Components: What You Need To Know,作者:Usama Jamil