在日常的工作中,无论是数据处理、日志分析,还是格式化输出,AWK命令都是不可或缺的利器。AWK是一种强大的文本处理工具,能让你轻松处理复杂的数据,提升工作效率。本文将为你介绍AWK的基本功能及一些实用场景,帮助你快速掌握这门工具。

awk选项
awk 命令的使用方式如下:
awk options program fileawk 可以采用以下选项:
- -F:fs指定文件分隔符。
- -f:文件指定包含 awk 脚本的文件。
- -v:var=值声明变量。
我们将了解如何使用awk处理文件和打印结果。
读取AWK脚本
要定义awk脚本,请使用用单引号括起来的大括号,如下所示:
awk '{print "Welcome to awk command tutorial "}'如果您键入任何内容,它将返回我们提供的相同欢迎字符串。如下图所示:

要终止程序,请按Ctrl+D。看起来很棘手,不要惊慌,最好的还没有到来。
使用变量
使用awk,可以处理文本文件。Awk为找到的每个数据字段分配一些变量:
- $0:是输出整行的内容。
- $1:是输出第一个字段。
- $2:是输出第二个字段。
- $n:表示第n个字段。
在awk中,空格或制表符等空白字符是字段之间的默认分隔符。看看这个例子,看看awk是如何处理它的:

上面的示例打印了每行的第一个单词。
有时某些文件中的分隔符不是空格或tab,而是其他内容。您可以使用–F选项指定它:
awk -F ':' '{print $1}' /etc/passwd
此命令将打印passwd文件中的第一个字段。我们使用冒号作为分隔符,因为passwd文件使用它。
使用多个命令
要运行多个命令,请用分号分隔它们,如下所示:
root@didiplus:~# echo "Hello Tom" | awk '{$2="Adam"; print $0}'
Hello Adam第一个命令使 $2字段等于Adam。第二个命令打印整行。
从文件中读取脚本
您可以在文件中键入awk脚本,并使用 -f 选项指定该文件。我们的文件包含以下脚本:
{print $1 " home at " $6} awk -F: -f testfile /etc/passwd
在这里,我们从 /etc/passwd打印用户名和他的主路径,当然分隔符是用大写的-F指定的,即冒号。
你可以像这样awk脚本文件:
{
text = $1 " home at " $6
print tawk预处理
如果您需要为结果创建标题或表头等。您可以使用BEGIN关键字来实现此目的。它在处理数据之前运行:
awk 'BEGIN {print "this Title"} {print $0}' myfile执行上述代码输入如下图的结果:

awk后处理
要在处理数据后运行脚本,请使用END关键字:
awk 'BEGIN {print "this Title"} {print $0} END {print "this footer"}' myfile执行上述代码输出如下图的结果:

这很有用,例如,您可以使用它来添加页脚。让我们将它们组合到一个脚本文件中:
BEGIN {
print "Users and thier corresponding home"
print " UserName \t HomePath"
print "___________ \t __________"
FS=":"
}
{
print $1 " \t " $6
}
END {
print "The end"首先,使用BEGIN关键字创建顶部部分。然后我们定义FS并在末尾打印页脚。
awk -f myscript /etc/passwd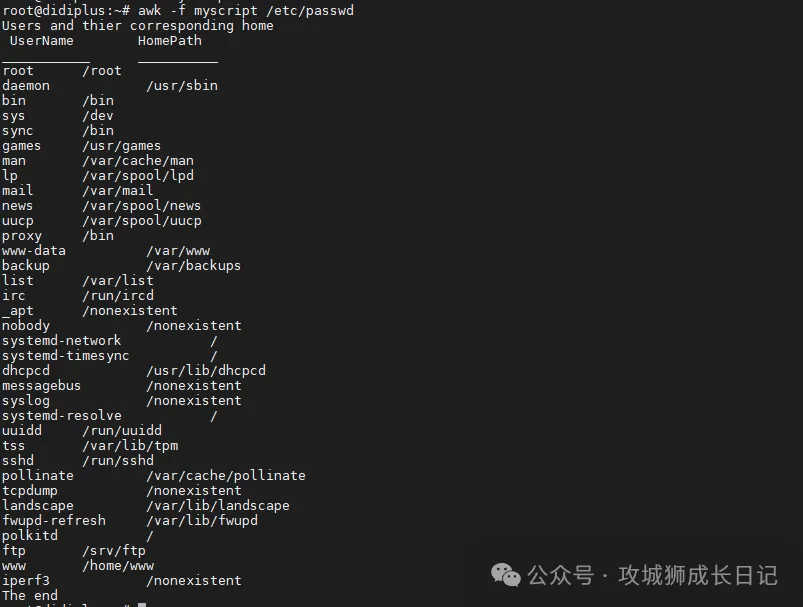
内置变量
我们看到数据字段变量$1,$2,$3等用于提取数据字段,我们还处理字段分隔符FS。
但这些并不是唯一的变量,还有更多的内置变量。
下面列出了一些内置变量:
- FIELDWIDTHS:指定字段宽度。
- RS:指定记录分隔符。
- FS:指定字段分隔符。
- OFS:输出分隔符。
- ORS:输出分隔符。
默认情况下,OFS变量是空格,你可以设置OFS变量来指定你需要的分隔符:
awk 'BEGIN {FS=":";OFS="---"} {print $1,$6,$7}' /etc/passwd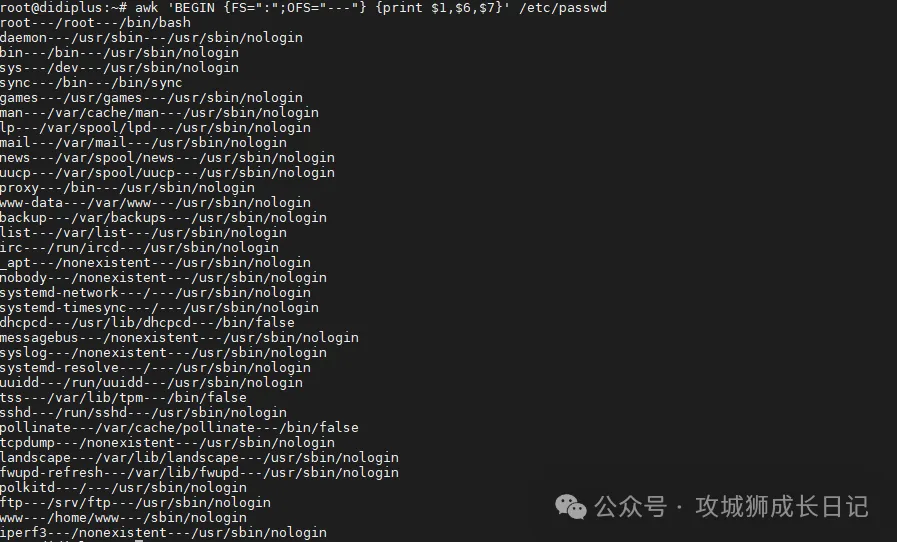
有时,字段的分布没有固定的分隔符。在这些情况下,FIELDWIDTHS 变量可以解决问题。
假设我们有以下内容:
1235.96521
927-8.3652
36257.8157awk 'BEGIN{FIELDWIDTHS="3 4 3"}{print $1,$2,$3}' testfile查看输出。输出字段为每行3个,每个字段长度都基于我们由FIELDWIDTH分配的字段。

更多的变量
还有一些其他变量可以帮助你获取更多信息:
- ARGC:获取传递的参数数量。
- ARGV:获取命令行参数。
- ENVIRON :shell环境变量及其对应值的数组
- FILENAME:awk处理的文件名。
- NF :Fields正在处理的行数。
- NR:检索处理过的记录总数。
- FNR:被处理的记录。
IGNORECASE:忽略字符的大小写。
让我们测试一下。
root@didiplus:~# awk 'BEGIN{print ARGC,ARGV[1]}' myfile
2 myfileENVIRON变量检索shell环境变量,如下所示:
root@didiplus:~# awk 'BEGIN {print ENVIRON["PATH"]}'
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin您可以使用不带ENVIRON变量的 bash 变量,如下所示:
root@didiplus:~# echo | awk -v home=$HOME '{print "My home is" home}'
My home is/rootNF变量指定记录中的最后一个字段,但不知道其位置:
awk 'BEGIN{FS=":"; OFS=":"} {print $1,$NF}' /etc/passwd
如果像这样键入NF变量,则可以将其用作数据字段变量:$NF。
让我们看一下这两个例子来了解FNR和NR变量之间的区别:
awk 'BEGIN{FS=","}{print $1,"FNR="FNR}' myfile myfile
在此示例中,awk命令定义两个输入文件。相同的文件,但处理了两次。输出是第一个字段值和FNR变量。
现在,检查NR变量并查看差异:
$ awk '
BEGIN {FS=","}
{print $1,"FNR="FNR,"NR="NR}
END{print "Total",NR,"processed lines"}' myfile myfile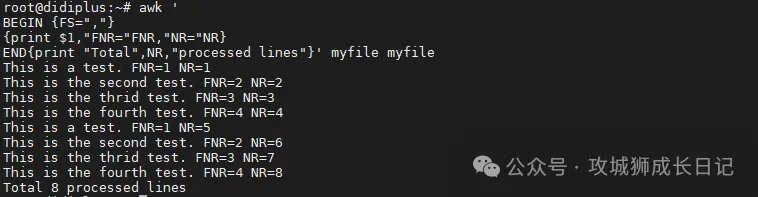
当涉及到第二个文件时,FNR变量变为1,但NR变量保留其值。
用户自定义变量
变量名称可以是任何内容,但不能以数字开头。您可以像在shell脚本中一样分配变量,如下所示:
awk '
BEGIN{
test="Welcome to LikeGeeks website"
print test
}'执行上述命令后,输出如下结果:

结构化命令
1.if循环
awk脚本语言支持if条件语句。testfile包含以下内容:
10
15
6
33
45root@didiplus:~# awk '{if ($1 > 30) print $1}' testfile
33
45如果要运行多个语句,则应使用大括号:
root@didiplus:~# awk '{
if ($1 > 30)
{
x = $1 * 3
print x
}
}' testfile
99您可以使用如下所示的else语句:
root@didiplus:~# awk '{
if ($1 > 30)
{
x = $1 * 3
print x
} else
{
x = $1 / 2
print x
}}' testfile
5
7.5
3
99
135或者在同一行中键入它们,并用分号分隔 if 语句,如下所示:
root@didiplus:~# awk '{ if ($1>20) print $1*2;else print $1/2}' testfile
5
7.5
3
66
902.while循环
您可以使用while循环遍历具有条件的数据。
awk '{
sum = 0
i = 1
while (i < 5)
{
sum += $i
i++
}
average = sum / 3
print "Average:",average
}' testfile- $i:是取到testfile的每一列的值
- while循环运行,每次它都会向sum变量加$i的值,直到 i 变量变为 4。

您可以使用break命令退出循环,如下所示:
awk '{
sum = 0
i = 1
while (i < 5)
{
sum += $i
if (i == 3)
break
i++
}
average = sum / 3
print "Average:",average
}' testfile结果还是和上面的输出的一样。
3.for循环
awk脚本语言支持for循环:
awk '{
total = 0
for (var = 1; var < 5; var++)
{
total += $var
}
avg = total / 3
print "Average:",avg
}' testfile格式化打印
awk中的printf命令允许你使用格式说明符打印出格式化的输出。
格式说明符如下所示:
%[modifier]control-letter下面列出了可用于printf的格式说明符:
- c:以字符串的形式打印数值输出。
- d:打印一个整数值。
- e:打印科学数字。
- f:打印浮点数。
- o:打印一个八进制值。
- s:打印文本字符串。
这里我们使用printf来格式化输出:
awk 'BEGIN{
x = 100 * 100
printf "The result is: %e\n", x
}'
内置函数
Awk提供了几个内置函数,例如:
1.数学函数
如果你喜欢数学,你可以在awk脚本中使用这些函数:
- sin(x)
- cos(x)
- sqrt(x)
- exp(x)
- log(x)
- rand()
而且它们可以正常使用:
root@didiplus:~# awk 'BEGIN{x=exp(5); print x}'
148.4132.字符串函数
有很多字符串函数,你可以查看列表,但我们将其中一个作为示例来研究,其余的都是一样的:
root@didiplus:~# awk 'BEGIN{x = "likegeeks"; print toupper(x)}'
LIKEGEEKS函数 toupper将传递的字符串的字符大小写转换为大写。
3.用户自定义函数
您可以定义您的函数并像这样使用它们:
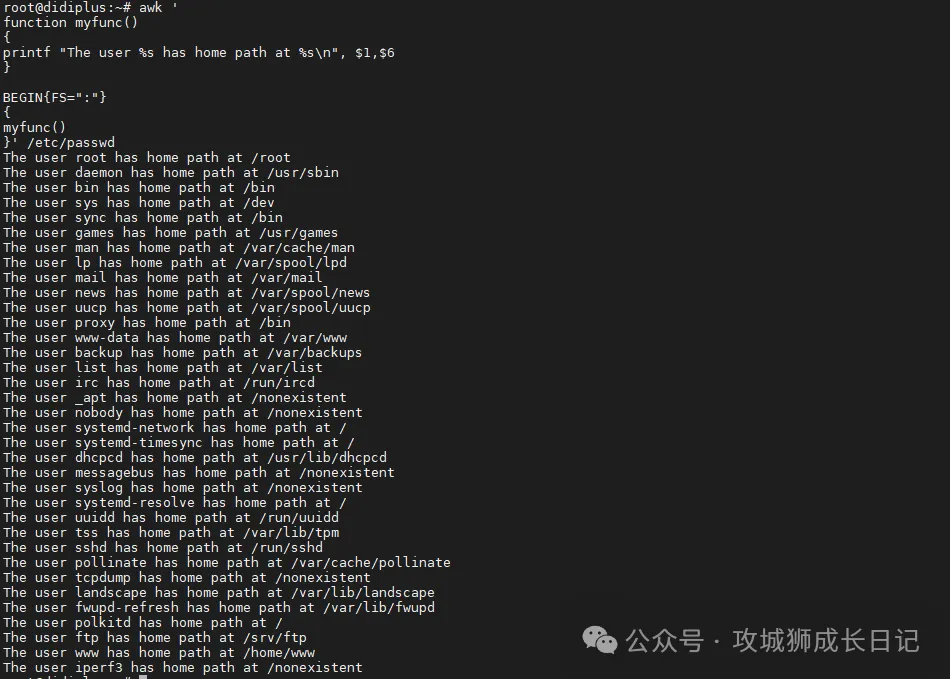
awk '
function myfunc()
{
printf "The user %s has home path at %s\n", $1,$6
}
BEGIN{FS=":"}
{
myfunc()
}' /etc/passwd在这里,我们定义了一个名为myprint的函数,然后在脚本中使用它通过printf函数打印输出。
总结
AWK是一款功能强大的数据处理工具,它能够高效地处理复杂的文本文件和数据集。无论你是需要处理日志、统计数据,还是生成格式化的报表,AWK都能轻松胜任。通过熟练掌握AWK命令,你可以极大提升工作效率,轻松应对各种数据处理任务。