












最近,出现了更新的YOLO模型,还有RT-DETR模型,这是一个声称能击败YOLO模型的变换器模型,我想将这些模型导出并进行比较,并将它们添加到我的库中。在这篇文章中,我将带你了解如何将这些模型导出到ONNX并运行它们,然后最终比较这些模型的速度。

将RT-DETR模型导出到ONNX

这是从模型的GitHub页面获取的模型示例输出
为了导出模型,我们需要从模型的GitHub仓库克隆代码(https://github.com/lyuwenyu/RT-DETR)。我将向你展示如何导出模型的第二个版本。如果你想使用第一个版本,导出步骤应该是类似的。
git clone https://github.com/lyuwenyu/RT-DETR.git
cd RT-DETR/rtdetrv2_pytorch然后我们需要创建一个Python虚拟环境来运行代码。如果你已经有一个工作的环境,那么你可以跳过这一步。
python -m venv rtdetrv2-env
source rtdetrv2-env/bin/activate
pip install -r requirements.txt
pip install scipy代码需要scipy库,但它不在需求文件中,你需要手动安装。然后我们需要下载coco数据集的YAML配置文件和模型。我们将在这里下载的模型是中等大小的模型。你可以在这里找到其他模型的链接。
mkdir models
cd models
wget -c https://github.com/lyuwenyu/storage/releases/download/v0.1/rtdetrv2_r34vd_120e_coco_ema.pth
wget -O dataset/coco_detection.yml https://raw.githubusercontent.com/ultralytics/ultralytics/main/ultralytics/cfg/datasets/coco.yaml现在我们可以导出模型了。请注意,如果你改变了模型大小,那么你需要更改下面的配置文件路径以匹配模型。
python tools/export_onnx.py -c configs/rtdetrv2/rtdetrv2_r34vd_120e_coco.yml -r models/rtdetrv2_r34vd_120e_coco_ema.pth --check现在你有了你的模型(在rtdetrv2_pytorch目录中的model.onnx文件)。你可以进入运行模型部分。
将YOLO-NAS导出到ONNX
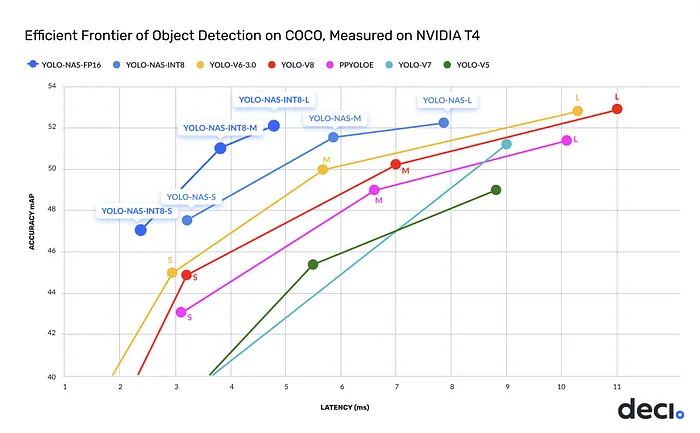
与模型的GitHub页面上的其他模型相比,YOLO-NAS模型
为了导出YOLO-NAS模型,你需要安装super_gradients库,然后运行以下Python代码。模型变体是YOLO_NAS_S、YOLO_NAS_M、YOLO_NAS_L。
from super_gradients.training import models
from super_gradients.common.object_names import Models
model = models.get(Models.YOLO_NAS_S, pretrained_weights="coco")
model.eval()
model.prep_model_for_conversion(input_size=[1, 3, 640, 640])
model.export("yolo_nas_s.onnx", postprocessing=None, preprocessing=None)现在你有了你的模型(yolo_nas_s.onnx文件)。你可以进入运行模型部分。
将YOLOv10导出到ONNX
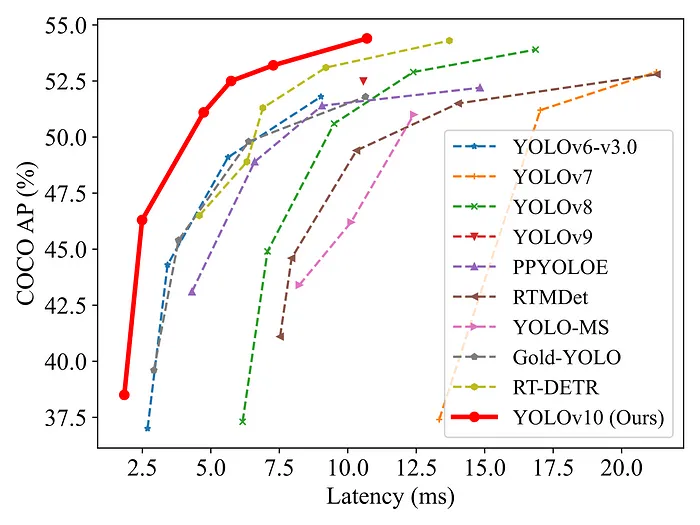
与模型的GitHub页面上的其他模型相比,YOLOv10模型的延迟
我们需要克隆GitHub仓库(https://github.com/THU-MIG/yolov10)并创建一个Conda环境来运行导出代码。
git clone https://github.com/THU-MIG/yolov10.git
cd yolov10
conda create -n yolov10-env python=3.9
conda activate yolov10-env
pip install -r requirements.txt
pip install -e .现在我们需要导出模型。模型的前缀是jameslahm/,支持的模型有yolov10n、yolov10s、yolov10m、yolov10b、yolov10l、yolov10x。
yolo export model=jameslahm/yolov10m format=onnx opset=13 simplify现在你有了你的模型(yolov10目录中的yolov10m.onnx文件)。你可以进入运行模型部分。
将YOLOv9导出到ONNX
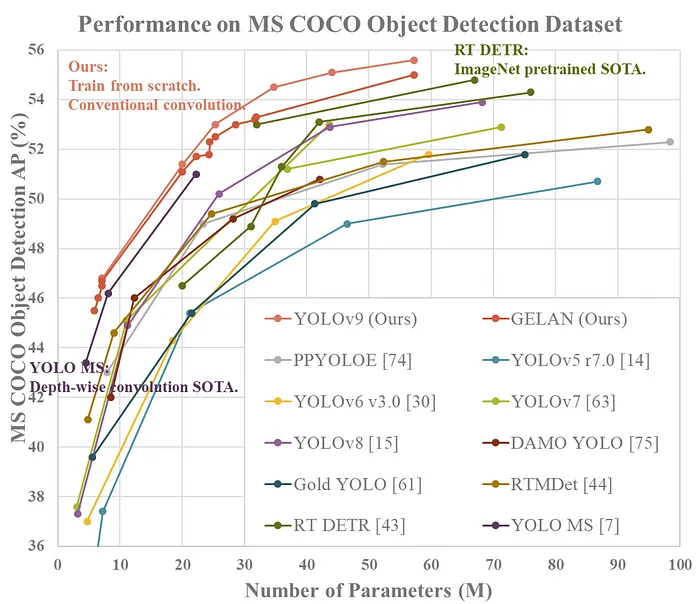
与模型的GitHub页面上的其他模型相比,YOLOv9模型的参数数量
为了导出YOLOv9,你需要有一个工作的正常安装的docker。你可以启动一个容器并导出模型。你可以在这里找到模型文件。
# Create an empty directory and cd into it
git clone https://github.com/WongKinYiu/yolov9.git
# Now we have yolov9 folder in out current directory. Then we run the following line:
docker run --name yolov9 -it -v `pwd`:`pwd` -w `pwd` --shm-size=64g nvcr.io/nvidia/pytorch:21.11-py3
# Install dependencies
apt update
apt install -y zip htop screen libgl1-mesa-glx
pip install seaborn thop
cd yolov9
# Download the model
wget https://github.com/WongKinYiu/yolov9/releases/download/v0.1/yolov9-s.pt
# Export the model
python export.py --weights yolov9-s.pt --include onnx现在你有了你的模型(yolov9目录中的yolov9-s.onnx文件)。你可以进入运行模型部分。
将YOLOv8导出到ONNX
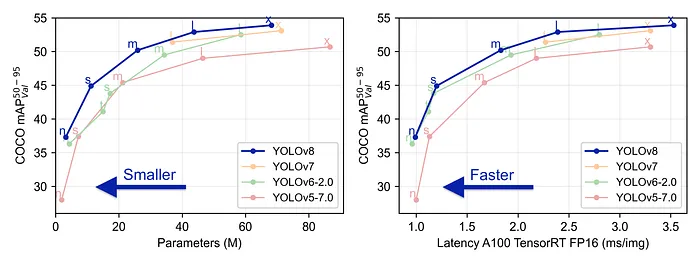
与模型的GitHub页面上的其他模型相比,YOLOv8模型
将YOLOv8导出比其他模型更容易。你只需要安装ultralytics并导出模型。支持的模型有yolov8n、yolov8s、yolov8m、yolov8l和yolov8x。如果你想的话,你可以创建一个虚拟环境来隔离安装。
pip install ultralytics
wget https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n.pt
yolo export model=yolov8n.pt format=onnx现在你有了模型(yolov8n.onnx文件),可以进入运行模型部分。
运行模型
现在你有了你想要导出的ONNX模型,你可以使用我编写的库来运行这些模型。你可以在这里找到这个库。库的README文件解释了如何链接到库。以下是如何使用库中的RT-DETR模型的示例。
#include <objdetex/objdetex.h>
int main()
{
using namespace ObjDetEx;
Detector detector(Detector::RT_DETR, "<path/to/onnx/model>");
Size batchSize = 1;
double detectionThreshold = .6;
// Fill this with batchSizex3x640x640 image data
float *imagePtr = nullptr;
// Fill this with batchSizex2 dimension data, not needed for YOLO models
// NOTE: 2 is width and height of the original images before resizing to 640x640
int64_t *dimensionPtr = nullptr;
auto detections = detector(Tensor(imagePtr, {batchSize, 3, 640, 640}), //
Tensor(dimensionPtr, {batchSize, 2}), detectionThreshold);
// Use the detections
return 0;
}





























