让我们讨论一下在训练过程中帮助你进行实验的技术。我将提供一些理论、代码片段和完整的流程示例。主要要点包括:
- 数据集分割
- 指标
- 可重复性
- 配置、日志记录和可视化

分割数据集
我喜欢有训练集、验证集和测试集的分割。这里没什么好说的;你可以使用随机分割,或者如果你有一个不平衡的数据集(就像在实际情况中经常发生的那样)——分层分割。
对于测试集,尝试手动挑选一个“黄金数据集”,包含你希望模型擅长的所有示例。测试集应该在实验之间保持不变。它应该只在你完成模型训练后使用。这将在部署到生产环境之前给你客观的指标。别忘了,你的数据集应该尽可能接近生产环境,这样才有代表性。
指标
为你的任务选择正确的指标至关重要。我最喜欢的错误使用指标的例子是 Kaggle 的“深空系外行星狩猎”数据集,在那里你可以找到很多笔记本,人们在大约有 5000 个负样本和 50 个正样本的严重不平衡的数据集上使用准确率。当然,他们得到了 99% 的准确率,并且总是预测负样本。那样的话,他们永远也找不到系外行星,所以让我们明智地选择指标。
深入讨论指标超出了本文的范围,但我将简要提及一些可靠的选项:
- F1 分数
- 精确度和召回率
- mAP(检测任务)
- IoU(分割任务)
- 准确率(对于平衡的数据集)
- ROC-AUC
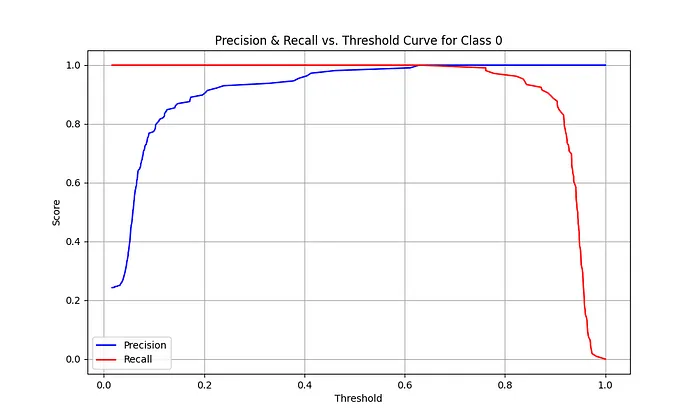
真实图像分类问题的分数示例:
为你的任务选择几个指标:
此外,绘制精确度-阈值和召回率-阈值曲线,以更好地选择置信度阈值。
可重复性
没有可靠的可重复性,我们就不能谈论实验。当你不改变任何东西时,你应该得到相同的结果。简单的例子,如果你使用 torch 和 Nvidia,如何冻结所有种子:
注意:cudnn_fixed 可能会影响性能。我在实验期间使用它,然后在选择参数后的最终训练阶段关闭它。
这是当你有 cudnn 固定并且不改变参数时会发生什么——训练完全一样。这就是我们希望从 cudnn_fixed 得到的结果。
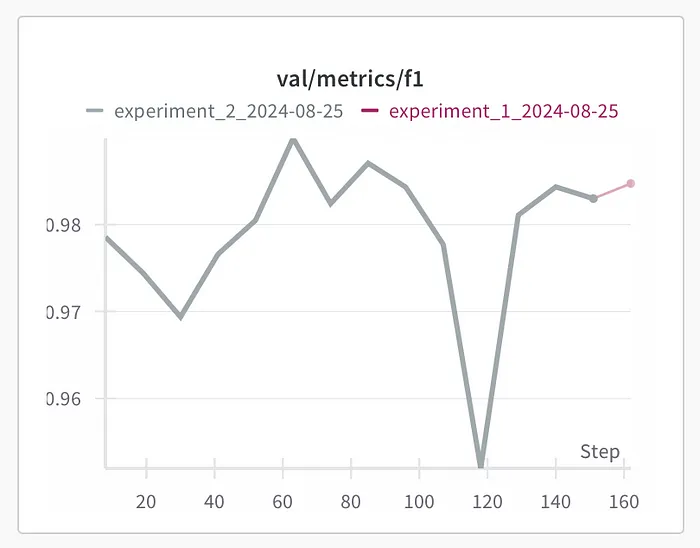
现在你可以处理参数,并确保结果的变化是因为参数的变化。
配置、日志记录和可视化
这是人们经常忘记的部分,但我发现它非常有用:
- 包含变量和超参数的配置文件
- 记录所有指标和配置的日志
- 指标的可视化
当你有一个包含很多模块的项目时,配置文件非常方便,你可以将变量放在一个配置文件中,并在所有模块中使用。你还应该在那里存储训练配置。这里有一个我使用的 Hydra 配置的例子:
每次训练会议的配置文件和指标都应该被记录。通过 wandb(或类似的东西)集成,每次训练会议都被记录和可视化。
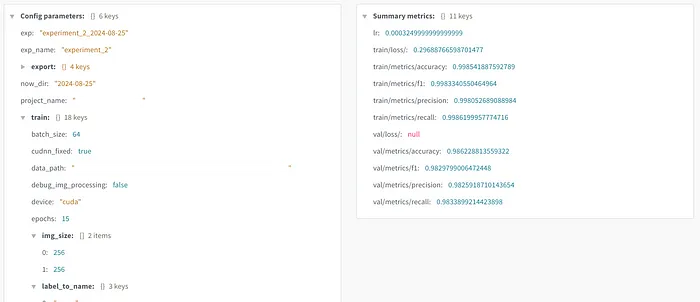
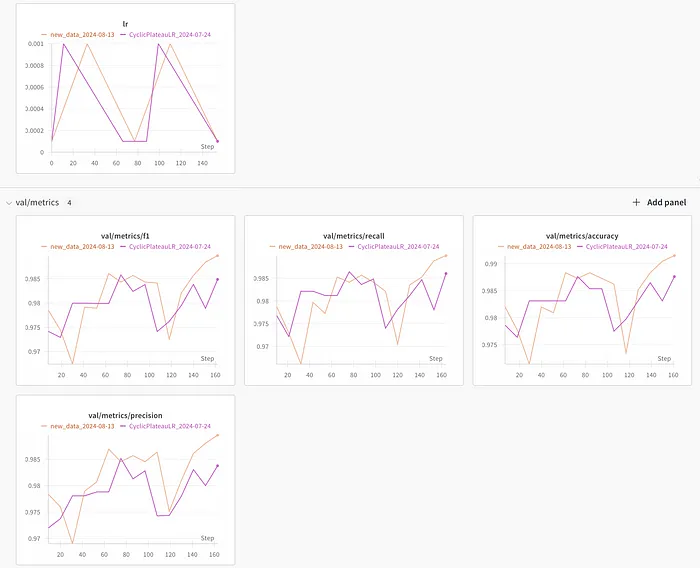
我也更喜欢保存在本地:
在训练期间:
- 每个时代后打印验证指标
- 如果它实现了最佳指标,则保存模型
- 如果调试模式开启,则保存预处理图像
训练结束时:
- 保存包含最佳验证和测试指标的 metrics.csv
训练后:
- 保存 model.onnx,model.engine 和在模型导出期间创建的其他格式
- 保存显示模型注意力的可视化
结构示例: