整理 | 星璇
不走寻常路的面壁智能,又一次“掀桌子”了!
面壁昨天发布了第三代小钢炮MiniCPM3.0,参数只有4B,性能却足以叫板市面上千亿参数规模的大模型!端侧的“面壁定律”又一次发威了!
 图片
图片
话不多说,直接上干货。
1.综合能力:4B规模干翻GPT-3.5
提前近 4 个月,面壁智能实现了初代面壁小钢炮发布时立下的 Flag:今年内让 GPT-3.5 水平的模型在端侧跑起来!
 图片
图片
MiniCPM 3.0 再次挖掘端侧模型的极致性能,仅 4B 参数,在包括知识水平、数学逻辑、代码能力、指令遵循、工具调用等多项能力上对 GPT-3.5 实现赶超,Overall Acc(所有分类任务的准确率平局值)超过了Llama3.1-8B-instruct、Qwen2-7B-Instruct、GLM-4-9B-Chat、Phi-3.5,可谓一匹黑马。
2.小钢炮挑战无限长文本
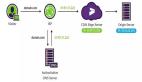
小钢炮3.0采用了一种LLMxMapReduce长文本分帧处理的技术,通过将长上下文切分为多个片段,让模型并行处理,并从不同片段中提取关键信息,汇总最终答案,实现无限长文本。这一技术对模型长文本能力,具有普遍增强作用,且在文本不断加长情况,仍保持稳定性能、减少长文本随加长掉分情况。
 LLMxMapReduce 技术框架图
LLMxMapReduce 技术框架图
更长的上下文长度,意味大模型拥有更大的“内存”和更长的“记忆”,不仅能提高大模型处理数据的能力上限,还能拓宽大模型应用的广度和深度。
 长上下文:小模型也可以无限长文本
长上下文:小模型也可以无限长文本
而小钢炮这种无限上下文技术, 可以让模型一次性读取不限字数的书籍或不限量的学术论文、简历等材料,成为你身边更加强大的终端个人助手。
这也就意味着,搭载小钢炮的手机,AI能力将会得到真正的释放,比如读取你的大众点评美食、酒店评价、微博互动内容,并牢牢记住你和AI 跨越多年的聊天记录,成为最懂你的AI陪伴者,为你提供“共情”的推荐与内容。
3.超强 RAG 外挂三件套,中文检索第一、生成超 Llama3-8B
现在RAG已经成为AI原生应用开发的标配,让模型引用外部知识库,检索到最新、最可靠的专业知识,确保生成内容更加可信,大大减少大模型的幻觉问题,尤其是对法律、医疗等依赖专业知识库、对大模型幻觉容忍度极低的垂直行业。
在检索、重排、生成这三个重要的RAG环节,面壁这次一口气把三件套全都放了出来:MiniCPM-Embedding(检索模型)、MiniCPM-Reranker(重排序模型)和面向 RAG 场景的 LoRA 插件(生成模型)。
- MiniCPM-Embedding(检索模型)中英跨语言检索取得 SOTA 性能,在评估模型文本嵌入能力的权威评测集 MTEB 的检索榜单上中文第一、英文第十三 ;
- MiniCPM-Reranker(重排序模型)在中文、英文、中英跨语言测试上取得 SOTA 性能 ;
- 经过针对 RAG 场景的 LoRA 训练后,MiniCPM 3.0-RAG-LoRA 在开放域问答(NQ、TQA、MARCO)、多跳问答(HotpotQA)、对话(WoW)、事实核查(FEVER)和信息填充(T-REx)等多项任务上的性能表现,超越 Llama3-8B 和 Baichuan2-13B 等业内优秀模型。
 图片
图片
4.端侧智能体:GPT-4o 级 Function calling
智能体应用是端侧AI 必争之地,而这其中一项至关重要的技术是 Function Calling(函数调用),它能够将用户模糊化的输入语义转换为机器可以精确理解执行的结构化指令,并让大模型连接外部工具和系统,例如通过语音在手机上调用日历、天气、邮件、浏览器等 APP 或相册、文件等本地数据库,从而打开终端设备 Agent 应用的无限可能,也让人机交互更加自然和方便。
小钢炮 3.0 这次发布的数据来看,堪比具备端侧最强 Function calling 性能 ,在权威评测榜单 Berkeley Function-Calling Leaderboard 上,其性能接近 GPT-4o,并超越 Llama 3.1-8B、Qwen-2-7B、GLM-4-9B 等众多模型。
 图片
图片
最后,上地址。MiniCPM 3.0 开源地址:
GitHub: https://github.com/OpenBMB/MiniCPM
HuggingFace: https://huggingface.co/openbmb/MiniCPM3-4B