














译者 | 布加迪
审校 | 重楼
提取、转换和加载(ETL)的三个阶段通常涉及多个任务,每个任务都可以独立执行。你可以将每个任务作为微服务来开发。
公司企业每天从各种业务运营中生成大量数据。比如说,每当客户在零售店结账时,可以在销售点(PoS)系统获取诸如客户标识符、零售店标识符、结账时间、购买物品列表和总销售额之类的数据。同样,现场销售人员可能会将潜在的销售机会录入到电子表格中。此外,大多数商业通信是通过电子邮件进行的,这使得电子邮件成为一个大有价值的数据源。为了在整个组织保持信息的一致性,并从这些数据中获得业务洞察力,从这些分散的数据源中提取必要的细节并保持所有的相关信息集中化就显得至关重要。
提取、转换和加载(ETL)技术侧重于这个问题:从多个数据源提取数据,将提取到的数据转换成所需的格式,最后将其加载到相关的数据存储或系统中。然而,由于业务和技术的进步,ETL应用生态也在迅速发生变化。其中面临一些挑战:
- 使用人工智能从自然语言或非结构化数据源中提取信息。
- 使用人工智能来转换数据。
- 与基于云的系统连接以提取或加载数据。
- 在混合云环境中灵活部署ETL流。
- ETL流的可扩展性。
- 像微服务那样敏捷和快速地部署ETL流。
- 支持流式ETL操作。
- 针对小规模用例的低成本ETL部署。
我们在下文将讨论构建这种敏捷ETL流的体系结构以及快速部署这些ETL流的方法。
用于构建敏捷ETL流的体系结构
ETL的每个提取、转换和加载阶段通常涉及多个任务。比如说,提取阶段可能涉及从CSV文档和电子邮件中提取数据的任务。与之相仿,转换阶段可能涉及删除缺失字段的数据项、连接字段、分类以及将数据从一种格式映射到另一种格式等任务。最后,加载阶段可能涉及加载到数据仓库、更新数据库中的数据项或将数据插入不同系统中等任务。这样的ETL流如下图所示:
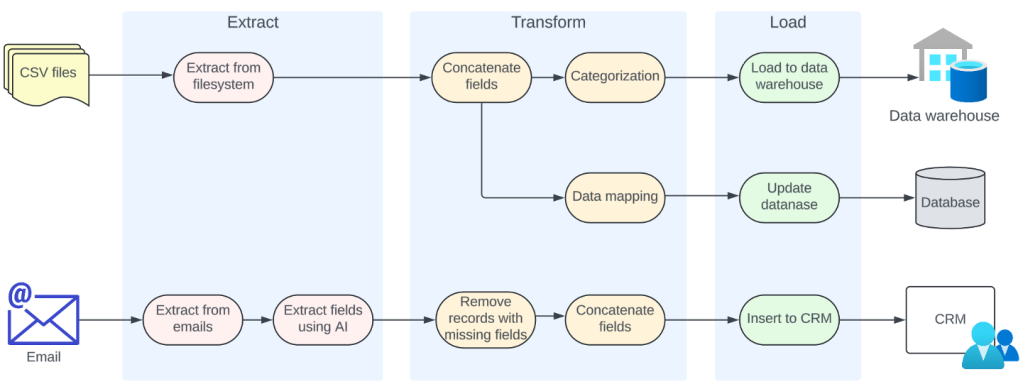
图1
一旦提供了原始数据或另一个任务的输出,这些任务中的每一个都可以独立执行。因此,可以使用合适的技术实现这每一个任务,并将它们作为可独立部署和扩展的集群加以执行。这使得我们可以将每个任务作为微服务来开发。
此外,任务之间存在依赖关系。比如说,“连接字段”任务依赖“从文件系统中提取”任务。可以使用多种方法在这类相关任务之间传递数据。一种简单的方法就是使用REST API调用在这些任务之间进行联系。然而,如果在任务之间使用消息传递系统,就可以促进解耦并提高可靠性。然后,每个任务使用来自消息传递系统中某个主题的数据,并在处理完成后将输出数据发布到另一个主题。这种方法有诸多优点:
- 每个任务可以以自己的速度工作,而不会被前一个任务的请求过载。
- 如果任务失败,数据不会丢失。
- 可以将另外的任务添加到ETL流中,而不会影响当前任务。
将ETL任务作为微服务来实现并通过消息传递层方便其通信的体系结构如下所示:
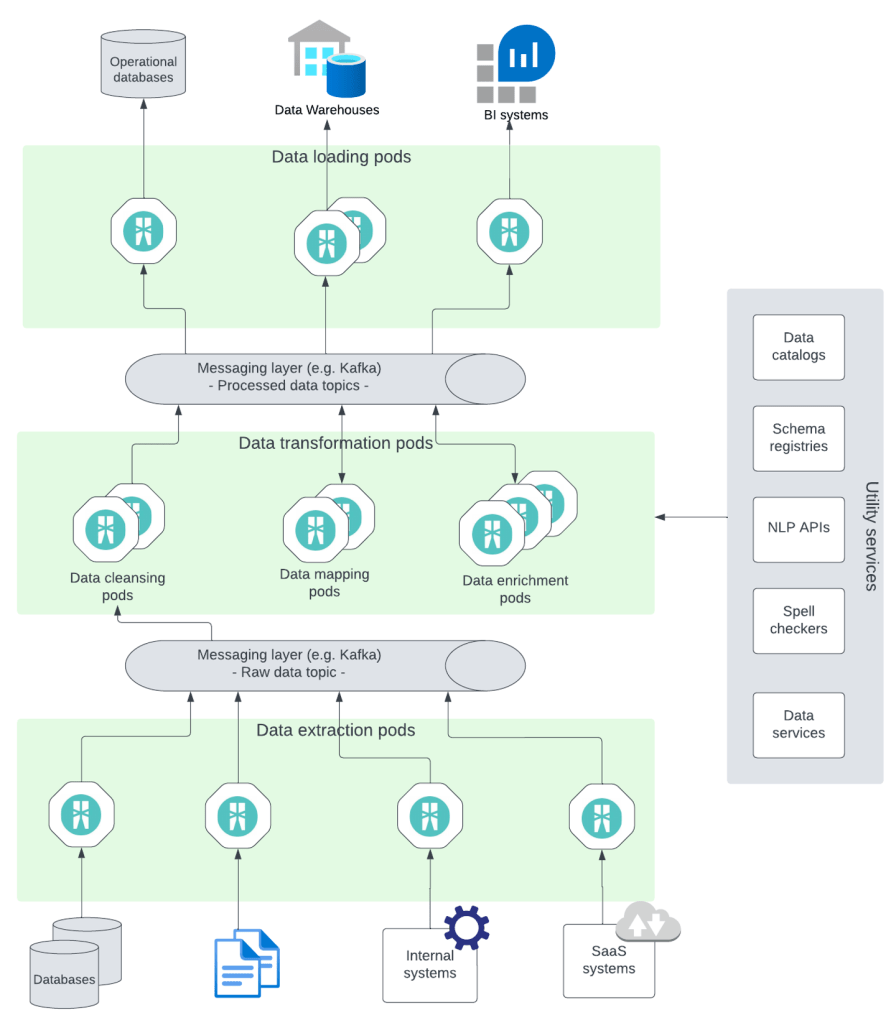
图2
将每个ETL任务分离为微服务可以视作逻辑体系结构。在实际的实现中,可以根据可扩展性、开发团队和预期的可扩展性需求等因素,确定是将ETL任务作为单独的微服务来实现,还是将多个任务组合成单个微服务。
实现ETL任务
下一步是实现单独的ETL任务。因为这每一个任务都是微服务,任何技术都可以用于实现。ETL任务通常包括三个步骤:
- 与本地数据中心和云端可用的数据存储和外部端点集成。
- 处理庞大且复杂的数据结构。
- 通过多种格式和协议传输数据。
许多支持微服务风格部署的集成技术都可以用于实现ETL任务。适合此用途的一种技术是Ballerina编程语言,它是专门为集成而设计的。Ballerina直接支持服务开发、数据库连接、通用协议、数据转换以及多种数据类型(如JSON、XML、CSV和EDI)。此外,它还附带大量连接件,以便与本地系统和SaaS系统集成。我们在下面将探讨一些使用Ballerina开发ETL任务的示例。
数据提取
业务数据有可能放在数据库、CSV文件、EDI文档、电子表格或ERP应用软件等各种企业系统中。因此,数据提取任务需要连接所有这些数据源,并使用它们支持的格式读取数据。下面是使用Ballerina从数据库、CSV文件和EDI文档中提取数据的几个示例。
- 读取数据库
- 读取CSV文件
- 读取EDI文档
数据提取阶段可能还需要从非结构化数据源中提取数据。这方面的一个典例是从电子邮件、留言和评论中提取结构化信息。下面的例子演示了使用Ballerina和OpenAI从评论中提取好评、差评和改进建议等信息。
数据转换
提取的数据可能来自员工填写的电子表格、从手写文档扫描而来的文本或操作员输入到系统的数据。因此,这类数据可能含有拼写错误、缺失字段、重复信息或无效数据。因此,转换阶段必须在将这些数据记录加载到目标系统之前加以清洁。此外,可能需要在转换阶段将来自多个数据源的相关细节组合起来,以便丰富数据。下面的例子展示了使用Ballerina来完成这些任务。
- 删除重复信息
- 识别无效数据项
- 数据丰富
提取的数据常常需要在存储到目标系统之前转换成不同的格式。然而,ETL任务通常不得不处理由数百个字段组成的非常庞大的数据结构,这可能使数据映射成为一项乏味枯燥的任务。可以使用Ballerina的可视化数据映射功能简化这项操作,如下所示:
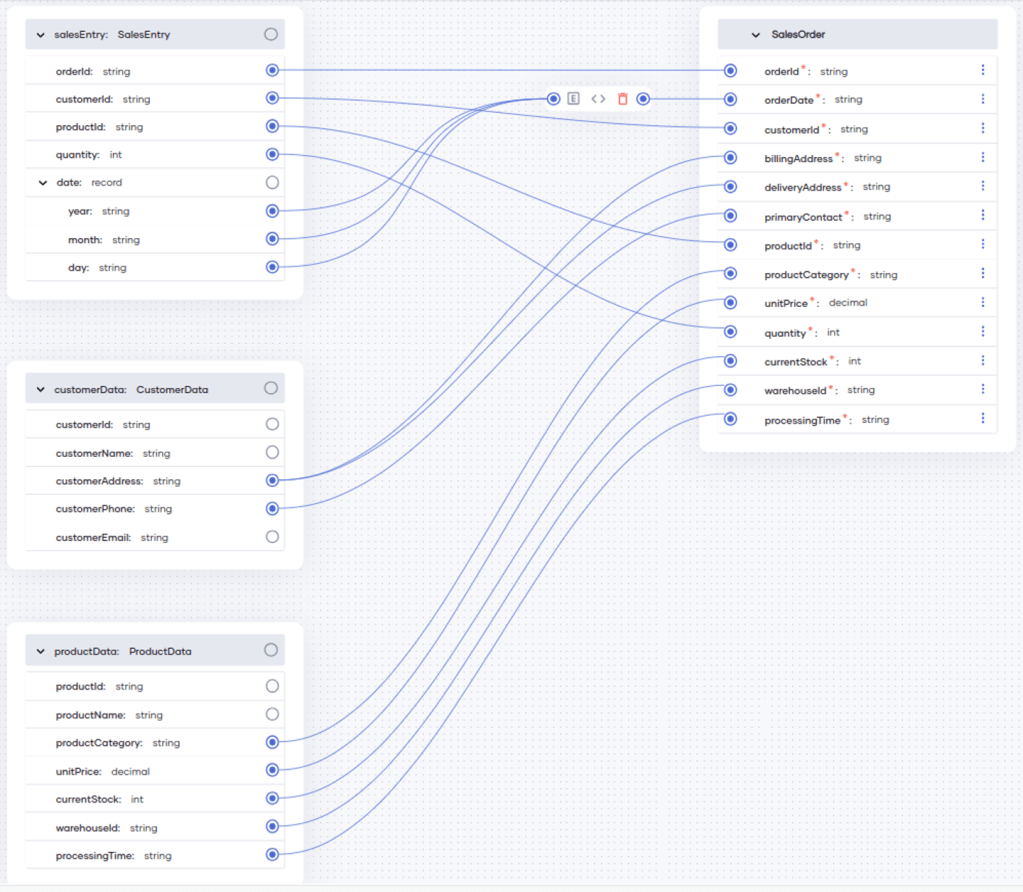
图3
数据加载
最后,数据加载阶段的任务需要连接不同的目标系统,并通过所需的协议发送数据。使用TLS和OAuth2等技术实现安全连接到这些目标系统也很重要。Ballerina有大量的连接件,并内置支持所有常见的安全标准,因而实现此类数据加载任务变得容易。下面的示例展示了如何将数据插入到Google BigQuery中。
有时候,业务用户可能希望检查某些数据记录,比如缺失值或无效值的数据项。就微服务体系结构而言,引入这样一个额外的任务只需要添加一个微服务来读取相关主题,并将数据加载到电子表格之类的最终用户系统中。下面是一个从主题中读取数据并将其插入到Google Sheets的示例。
部署和测试ETL流
将单个ETL任务作为微服务来开发便于将整个ETL流部署到Kubernetes集群中。每个ETL任务都可以是Kubernetes部署环境中的一个pod,从而可以根据负载大小来增加或减少单个ETL任务的pod数量。然而,组织通常有多个ETL流,每个流又涉及许多任务。此外,这些ETL流可能归不同的团队拥有。因此,拥有适当的CI/CD管道、权限模型、监测功能以及用于开发、测试、性能验证和生产的多个环境至关重要。
Ballerina可以与所有常见的CI/CD、监测和部署技术一起工作,从而无缝地将基于Ballerina的ETL流与组织的现有基础设施集成在一起。比如说,Ballerina ETL源代码可以在GitHub中加以维护,CI/CD操作可以使用Jenkins来实现,ETL流可以部署在Amazon EKS上,执行则可以使用Prometheus和Grafana加以监测。
另一个部署选项是Choreo平台,该平台默认情况下提供了所有这些功能。由于Choreo让用户无需构建平台,因此可以通过部署一组选定的ETL流、进行测试并将它们转移到生产环境中,立即开启ETL之旅。然后可以对这些ETL流进行改动,或者可以在相应的数据源存储库中引入新的ETL流,新的ETL流由Choreo摄取后部署到开发环境中。
结语
本文讨论了灵活的、类似微服务的ETL流的体系结构和Ballerina语言实现。考虑到大多数业务部门生成数据,并有着独特的数据需求,Ballerina语言提供的数据处理能力、连接性和灵活的部署选项可能具有变革性。Ballerina团队目前正在竭力改进工具支持,力求使构建集成和ETL流变得更简单。
原文标题:Developing agile ETL flows with Ballerina,作者:Chathura Ekanayake















