













译者 | 朱先忠
审校 | 重楼
本文将使用五篇新发表的强化学习论文中介绍的五种算法(DDPG、SAC、PPO、I2A和决策转换器)来训练模拟人形机器人互相打斗并对训练结果进行排名。
 训练模拟人形机器人的五种强化学习技术大PK-AI.x社区
训练模拟人形机器人的五种强化学习技术大PK-AI.x社区
简介
我想起了最近的一个老电视节目《Battlebots》,并想对这个节目进行进一步的改造。因此,我将使用最新发表的五篇有关强化学习的论文中提到的技术来分别训练模拟人形机器人并让它们展开决斗,以便比较这些算法的不同排名。
通过阅读本文中介绍的内容,你将学习到关于这五种强化学习算法的工作原理和数学原理,并了解我是如何实现这些不同算法的。同时,您还可以领略一下这些机器人是如何面对面地展开决斗,并最终确定哪一种算法是最后的冠军!
- 深度确定性策略梯度(DDPG)算法
- 决策转换器算法
- 柔性演员-评论家(Soft Actor-Critic:SAC)算法
- 基于近邻策略优化(PPO)的想象增强智能体(I2A)算法
设置模拟环境
在本文实验中,我将使用Unity机器人学习智能体模拟器,针对每个机器人身体在9个关节上构建21个执行器,通过他们头上的虚拟相机实现了10乘10的RGB视觉,还有一把剑和一个盾牌。然后,我使用C#代码来定义它们的奖励和物理交互。智能体可以通过三种主要方式来获得奖励:
- 用剑攻击对手(“击败”对手)
- 将头部的y位置保持在身体上方(以激励他们站起来)
- 比以前更接近对手(以鼓励智能体会聚在一起并展开决斗)
智能体将在1000个时间步后重置,我尽量大规模并行化执行环境,以加快训练速度。

大规模并行化训练环境(我个人的截图)
然后,就是编写算法了。为了理解我使用的算法,您首先需要理解Q学习,这是至关重要的。
Q学习(如果已熟悉,请跳过本节)
在强化学习中,我们让智能体采取行动来探索其环境,并根据其与目标的接近程度对其进行积极或消极的奖励。那么,智能体如何调整其决策标准以获得更好的奖励呢?
Q学习(Q Learning)算法提供了一种解决方案。在Q学习中,我们跟踪Q函数Q(s,a);这个函数能够跟踪从状态s_t到动作a_t后的预期返回结果。
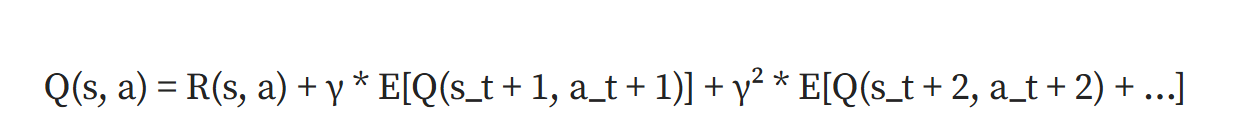
在上面公式中,R(s,a)表示当前状态和动作的奖励,γ表示折扣因子(超参数),E[]表示期望值。
如果我们学习了这个Q函数,那么我们可以简单地选择返回最高Q值的那个动作。
接下来,我们来看如何学习这个Q函数?
从训练回合结束时开始,我们已知道真实的Q值(也就是我们当前的奖励)。我们可以使用以下更新方程并使用递归技术来填充之前的Q值:
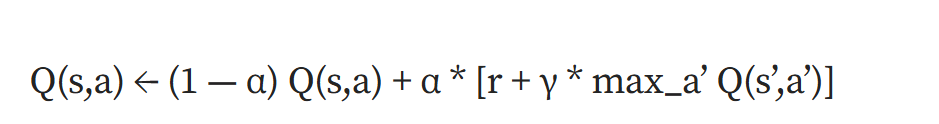
在上面公式中,α表示学习率,r表示即时奖励,γ表示折扣因子(权重参数),s'表示下一个状态,max_a'Q(s',a')表示所有可能动作中下一个状态的最大Q值。
从本质上讲,我们的新Q值变成了旧Q值+当前奖励+下一个最大Q值和旧Q值之间差值的一小部分。现在,当我们的智能体想要选择一个动作时,他们可以选择产生最大Q值(预期奖励)的那个动作。
不过,你可能会注意到这样一个潜在的问题:我们正在每个时间步对每个可能的操作评估Q函数。如果我们在离散空间中仅有有限数量的可能动作,这倒是很好的;但是,这种情况在连续动作空间中却会崩溃——此时不再可能对无限数量可能动作上的Q函数展开有效的评估。于是,这就引出了我们的第一个竞争算法——DDPG。
深度确定性策略梯度(DDPG)算法
DDPG(Deep Deterministic Policy Gradient)算法试图以一种新颖的方式在连续动作空间中使用Q网络。
创新点1:演员与评论家
我们不能使用Q网络直接做出决策,但我们可以用它来训练另一个单独的决策函数。这就要使用所谓的演员-评论家(actor-critic)设置。其中,演员(actor)代表决定行动的策略,评论家(critic)则根据这些行动确定未来的预期奖励。
其中,目标评论家的计算公式如下所示:
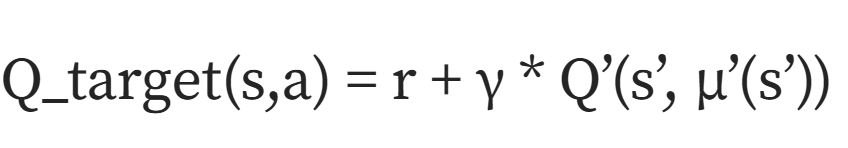
在上面公式中,r表示即时奖励,γ表示折扣因子,s'表示下一个状态,μ'(s')表示目标策略网络对下一状态的动作,Q'表示目标批评网络,目标演员:预期返回值wrt策略的梯度约等于:
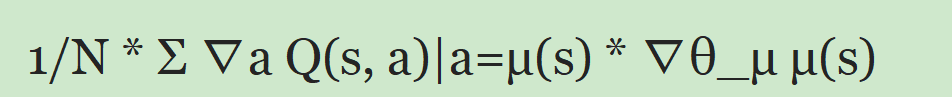
本质上,在N个样本上,策略(wrt-策略)选择的操作的Q值的变化方式会改变wrt-策略参数。
为了更新这两者,我们使用随机梯度上升更新的办法,在当前Q和目标Q的MSE损失上使用lr*梯度。请注意,演员和评论家都是作为神经网络实现的。
创新点2:确定性动作策略
我们的策略可以是确定性的(每个状态的保证动作)或随机性的(根据概率分布对每个状态的采样动作)。用于高效评估Q函数的确定性动作策略由于每个状态只有一个动作,因此是奇异型的递归评估。
然而,我们如何使用确定性策略来进行探索呢?我们不会一次又一次地重复同样的动作吗?确实如此,我们可以通过添加随机生成的噪声以鼓励探索来增加智能体的探索(这看起来有点像通过研究基因突变所具有的独特的遗传可能性来探索它是如何促进进化的一样)。
创新点3:交互式环境中的批处理学习
我们还希望通过观察到的每个时间步(由“状态-动作-奖励-下一个状态”组成)获得更大的回报:这样我们就可以存储之前的时间步数据元组,并将其用于未来的训练。
这允许我们离线使用批处理学习(这意味着使用之前收集的数据,而不是通过环境进行交互),此外还允许我们并行化以提高GPU的训练速度。我们现在也有了独立的同分布数据,而不是我们经常得到的有偏差的顺序数据(其中数据点的值取决于之前的数据点)。
创新点4:目标网络
通常,使用神经网络的Q学习太不稳定,也不容易收敛到最优解,因为更新太敏感/太强大了。
因此,我们使用目标演员和评论家网络,它们与环境相互作用,在训练过程中部分但不完全接近真实的演员和评论家((大因子)目标+(小因子)新目标)。
算法运行和代码
初始化评论家、演员、目标评论家和目标演员、重放缓冲区。
对于视觉,我在任何其他层之前都使用卷积神经网络(因此算法使用了视觉的最重要特征)。
然后,针对每一个回合(episode),执行如下操作:
- 观察状态,选择并执行动作mu+噪声。
- 获得奖励,转到下一个状态。
- 将(s_t,a_t,r_t, s_(t+1))存储在重放缓冲区中。
- 从缓冲区中提取小批量样品。
- 更新y_i = reward_i + gamma Q(s表示给定θ)。
- 递归计算。
- 更新critic以最小化L = y_i - Q(s,a|theta)。
- 使用策略梯度J更新演员,期望递归型的Q给定策略。
- 将目标更新为:大因子*目标+(1-大因子)*实际值。
【参考】github.com源码仓库地址:AlmondGod/Knights-of-Papers/src/DDPG/DDPG.py文件。
柔性演员-评论家(SAC)算法
DDPG算法确实存在一些问题。尽管评论家更新算法中包括贝尔曼方程:
Q(s,a)=r+max Q(s'a')
但是,神经网络作为Q网络近似器会产生大量噪声,噪声的最大值意味着我们高估了,也就是我们对我们的策略过于乐观,并奖励了平庸的行为。DPPG算法还需要大量的超参数调整(包括添加噪声),并且除非其超参数在窄范围内;否则,不能保证收敛到最优解。
创新点1:最大熵强化学习
现在,演员不再试图纯粹地最大化奖励,而是最大化奖励+熵。
那么,为什么要使用熵呢?
熵本质上是我们对某个结果的不确定性(例如,最大熵偏置的硬币总是有0熵显示形式)。
通过将熵作为最大化因子,我们鼓励了广泛的探索,从而提高了对局部最优解的敏感性,允许对高维空间进行更一致和稳定的探索(这正是比随机噪声更好的原因)。对熵的优先级进行加权的alpha参数,进行了自动调整(如何调整呢?)。
创新点2:使用两个Q函数
这一变化旨在通过独立训练两个Q网络并在策略改进步骤中使用两者中的最小值来解决Q函数的贝尔曼高估偏差。
算法运行和代码
初始化演员、2个Q函数、2个目标Q函数、回放缓冲区、alpha
重复执行下面操作直到收敛,对于每个环境步骤执行:
- 从策略中取样行动,观察下一个状态并奖励
- 将(s_t,a_t,r_t,s_t+1)存储在重放缓冲区中
在每个更新步骤中,执行:
- 抽样批次
- 更新Qs:
- 计算目标y=奖励+策略的最小Q+阿尔法熵
- 最小化Q预测-y
- 更新策略以最大化策略Q+阿尔法奖励
- 更新alpha以满足目标熵
- 更新目标Q网络(柔性更新目标为:大因子*目标+(1-大因子)*实际值)
【参考】github.com源码仓库地址:AlmondGod/Knights-of-Papers/src/SAC/SAC.py文件。
I2A算法与PPO算法
这里有两种算法(额外的alg层可以在任何算法之上工作)。
近端策略优化(PPO)算法
使用与DDPG和SAC不同的方法,我们的目标是一种可扩展、数据高效、鲁棒性强的收敛算法(对超参数的定义不敏感)。
创新点1:代理目标函数
代理目标允许进行非策略性训练,因此我们可以使用更广泛的数据(特别有利于存在大量预先存在的数据集的现实世界场景)。
在我们讨论代理目标之前,理解优势(Advantage)的概念至关重要。优势的定义是:采取s策略后,s的预期回报与s的预期回报之间的差异。本质上,它量化了一个行动在多大程度上比“平均”行动更好或更差。
我们估计它的表达式是:A=Q(A,s)-V(A)。其中,Q是动作值(动作A后的预期回报),V是状态值(当前状态的预期回报);两者都可以学习。
现在,代理目标的计算公式是:
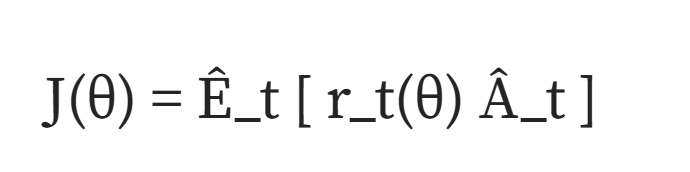
其中:
J(θ)表示代理目标;
Ê_t[…]表示有限批样品的经验平均值;
r_t(θ)=π_θ(a_t|s_t)/π_θ_old(a_t| s_t),即:新策略中行动的可能性/旧策略中的可能性;
Â_t代表时间步长t的估计优势。
这相当于量化新策略在多大程度上提高了更高回报行动的可能性,并降低了更低回报行动的可能。
创新点2:剪切目标函数
这是解决超大策略更新问题以实现更稳定学习的另一种方法。
L_CLIP(θ)=E[min(r(θ)*A,CLIP(r(σ),1-ε,1+ε)*A)]
在此,剪切目标是真实代理和代理的最小值,其中比率被截断在1-epsilon和1+epsilon之间(基本上是未修改比率的信任区域)。Epsilon通常为~0.1/0.2。
它本质上选择了更保守的剪切比和正态比。
PPO的实际目标函数是:
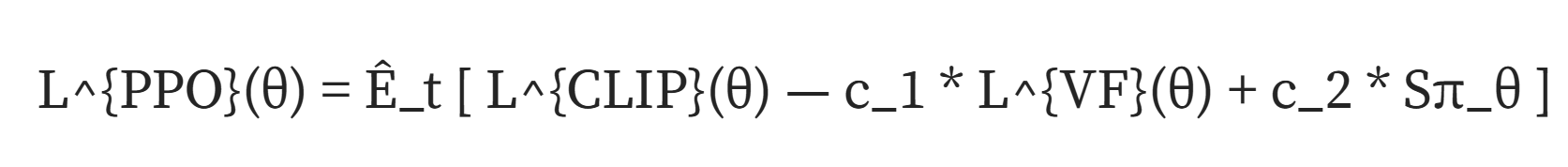
其中,
1. L^{VF}(θ)=(V_θ(s_t)-V^{target}_t)²
2. Sπ_θ代表状态S_t的策略π_θ的熵
从本质上讲,我们优先考虑更高的熵、更低的值函数和更高的削波优势。
此外,PPO算法还使用小批量和交替数据训练。
算法运行和代码
针对每次迭代,执行如下操作;对于N个演员中的每一个演员执行如下操作:
- 运行T时间步策略
- 计算优势
- 针对K个迭代周期和最小批处理大小M<NT的策略优化代理函数
- 更新策略
【参考】github.com源码仓库地址:AlmondGod/Knights-of-Papers/src/I2A-PPO/gpuI2APPO.py文件。
增强想象智能体算法
我们的目标是为任何其他算法创建一个额外的嵌入向量输入,以提供关键的有价值信息,并作为环境的“思维模型”。
创新点:想象向量
想象向量允许我们在智能体的观察中添加一个额外的嵌入向量,以便对多个“想象的未来运行”的动作和对其奖励的评估进行编码(目标是“看到未来”和“行动前思考”)。
那么,我们是如何计算想象向量的呢?我们的方法是使用一个学习环境近似函数,它试图对环境进行模拟(这被称为基于模型的学习,因为我们试图学习一个环境的模型)。我们将其与推出策略(rollout policy)相结合,这是一种非常简单且快速执行的策略(通常是随机的),用于决定“探索未来”的行动。
通过在推出策略上运行环境近似器,我们可以探索未来的行动及其回报,然后找到一种方法将所有这些想象中的未来行动和回报通过一个向量来描述。但是,这里也存在一个值得注意的缺点:正如你所料,它增加了大量的训练,因此这样的训练就更依赖于必要的大量数据。
组合I2A算法和PPO算法的运行与代码
- 每次我们收集PPO的观察结果:
- 初始化环境模型与推出策略。
然后,对于多个“想象的跑动”循环执行如下操作:
- 从当前状态开始运行环境模型,并决定推出策略,直到产生一个想象轨迹的地平线(s、a、r序列)。
- 想象编码器:将多个想象的轨迹转化为实际决策网络的单个输入嵌入。
决策转换器
我们的目标是利用转换器架构的优势进行强化学习。借助决策转换器(Decision Transformer,简称“DT”),我们可以在稀疏/分散的奖励中识别重要的奖励,享受更广泛的分布建模以实现更大的泛化和知识转移,并从预先获得的次优的有限数据中学习(称为离线学习)。
对于决策转换器,我们本质上将强化学习视为序列建模问题。
创新点1:转换器
如果你想真正了解转换器的话,我推荐您观看李飞飞高徒、被誉为AI“网红”的Karpathy发布的“从零开始构建GPT2”的有关视频。以下是适用于DT的有关转换器技术的一个快速回顾:
假设我们已经有一些表示状态、动作、回报(预期收到的未来奖励的总和)和时间步长的令牌序列。我们现在的目标是接收一系列令牌并预测下一步行动:这将作为我们的策略。
这些令牌都有键、值和查询,我们将使用复杂的网络将它们组合在一起,以表达每个元素之间的关系。然后,我们将这些关系组合成一个“嵌入”向量,该向量对输入之间的关系进行编码。这个过程被称为注意力。
请注意,“因果自注意力掩码”能够确保嵌入只能与序列中出现在它们之前的嵌入相关,因此我们不能使用未来来预测未来,而是使用过去的信息来预测未来(因为我们的目标是预测下一个动作)。
一旦我们有了这个嵌入向量,我们就可以把它传递到神经网络层(大牛Karpathy使用的类比是,在这种情况下,我们“推理”令牌之间的关系)。
这两个组合(用注意力查找令牌之间的关系,用神经网络层推理关系)是转换器的一个头部,我们多次堆叠它。在这些头部的最后,我们使用一个学习的神经网络层将输出转换为我们的动作空间大小和要求。
在推理时,我们预先定义了回报,作为我们最终想要的总奖励。
算法运行和代码
对于数据加载器中的(R,s,a,t)执行如下操作:
- 预测行动
- 模型将obs、vision(带卷积神经网络的层)、rtg和timestep转换为唯一的嵌入,并将timestep嵌入添加到其他嵌入中
- 所有另外三个用作转换器层的输入参数最终使用动作嵌入
- 计算MSE损失(a_pred-a)*2
- 使用具有该损耗的梯度参数wrt在决策转换器模型上执行SGD计算
【参考】github.com源码仓库地址:Knights-of-Papers/src/Decision-Transformer/DecisionTransformer.py。
结果评析
为了训练所有上述这些模型,我选择在NVIDIA RTX 4090 GPU计算机上运行了这些算法,以便利用这些算法中新加入的在GPU加速方面的支持。在此,非常感谢GPU共享市场vast.ai!以下给出各算法对应的损失曲线:
DDPG算法损失(2000回合)
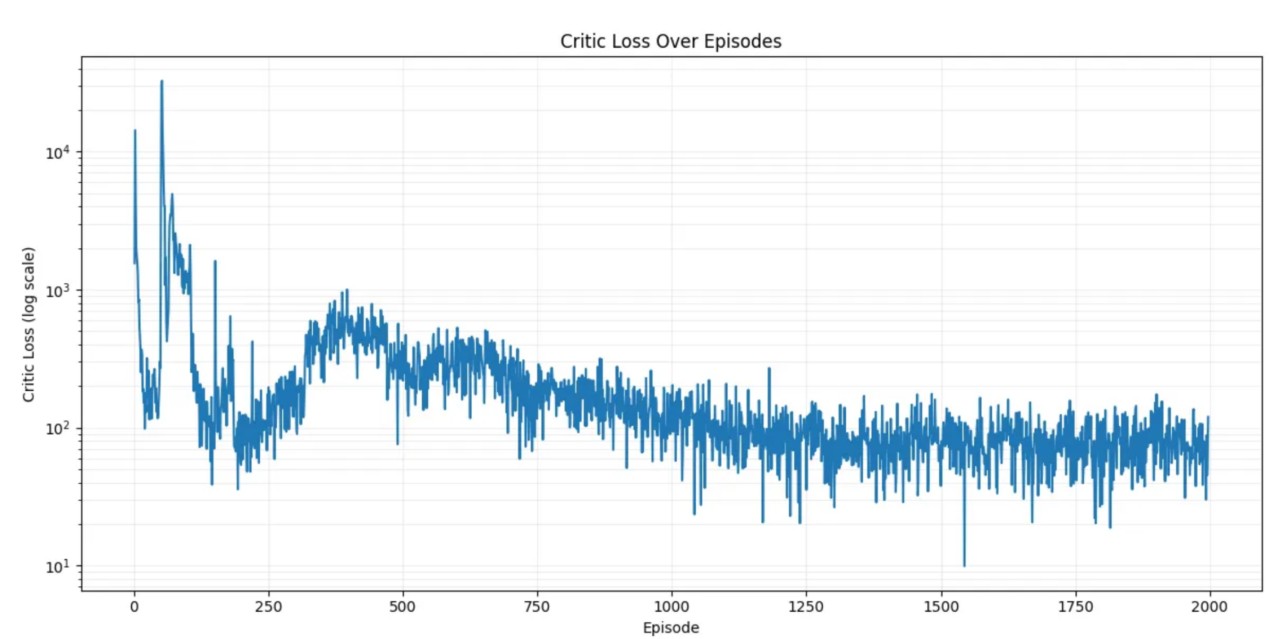
使用Matplotlib表示的损失图表(本人绘制)
I2APPO算法损失(3500回合)
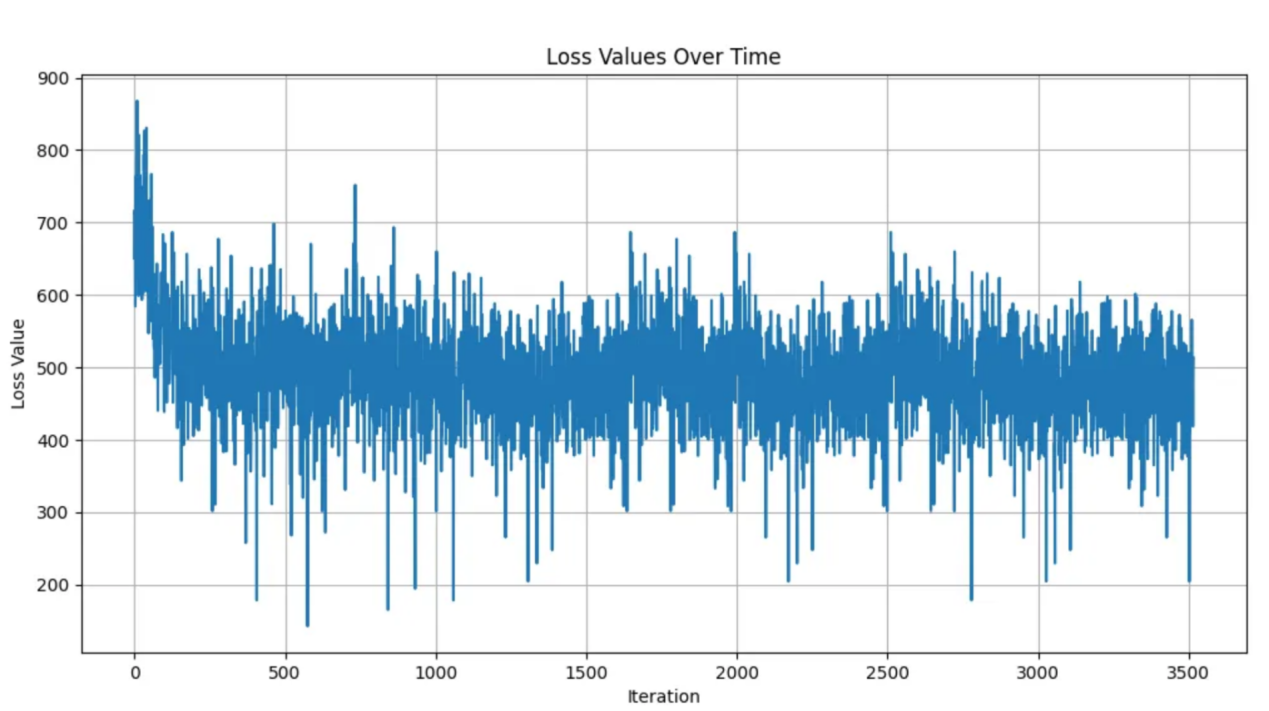
使用Matplotlib表示的损失图表(本人绘制)
SAC算法损失(5000集)
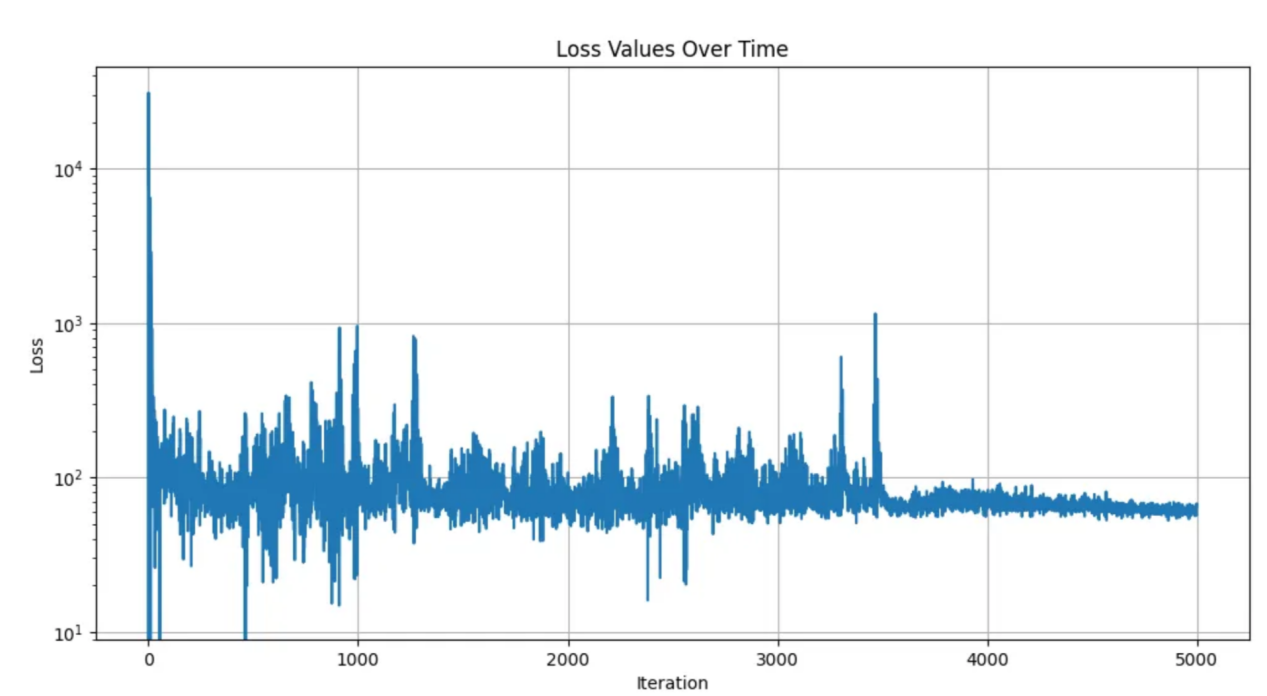
使用Matplotlib表示的损失图表(本人绘制)
决策转换器算法损失(1600回合,每40个回合记录一次损失)
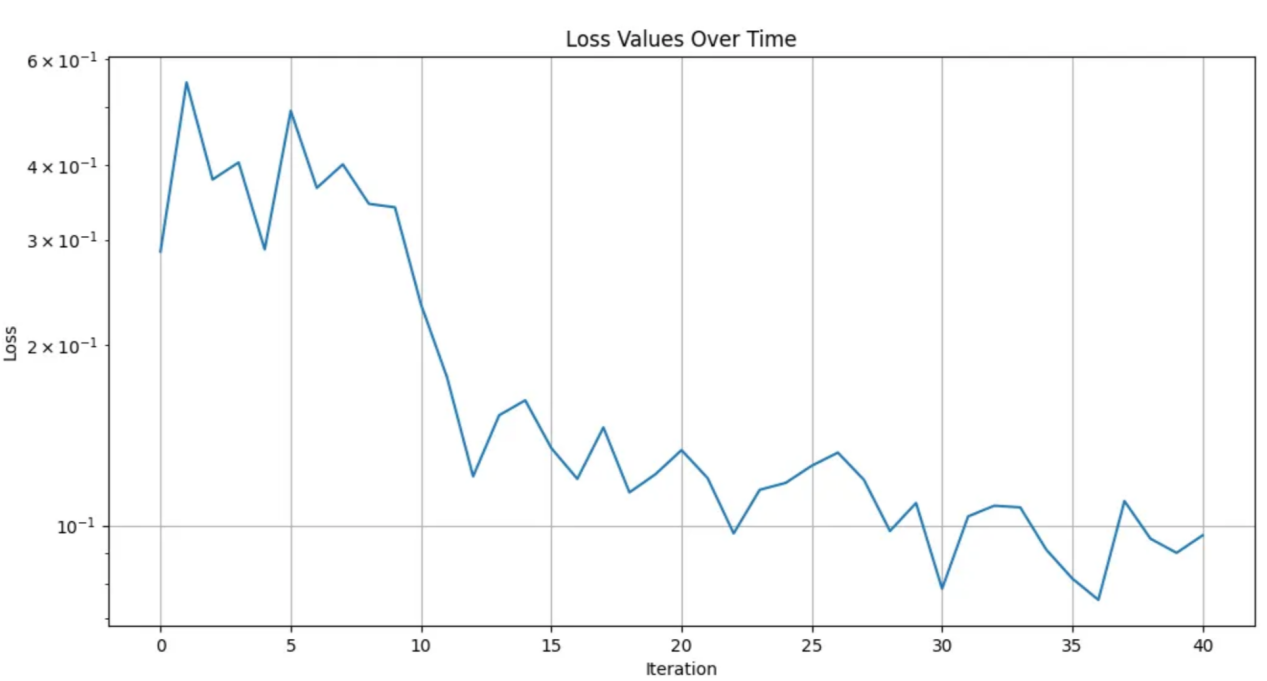
使用Matplotlib表示的损失图表(本人绘制)
通过比较以上各种算法的运行结果(我自主地按训练时间进行了加权),我发现策略转换器的表现最好!考虑到DT是专门为利用GPU而构建的,这是有道理的。最后,有兴趣的读者可以观看我制作的视频(https://www.youtube.com/watch?v=kpDfXqX7h1U),它将有助于你更细致地了解这些算法的实际性能。最后的比赛结果是,这些机器人模型都在不同程度上学会了爬行和防止摔倒;但是,要想成为专业的拳击手还有很长的一段路要走。
有待改进的方面
我了解到训练人形机器人是非常困难的。本实验中,我们是在高维输入空间(视觉RGB和执行器位置/速度)和令人难以置信的高维输出空间(27维连续空间)中进行的操作。
从一开始,我所希望的最好的结果就是他们能够彼此爬到一起,并相互决斗,尽管这也是一个挑战。然而,大多数的训练结果甚至都没有体验到将剑触碰对手的高回报,因为独自行走太难了。
总结一下的话,需要改进的主要方面也就是增加训练时间和使用的计算量。正如我们在现代人工智能革命中所看到的那样,这些增加的计算和数据趋势似乎没有上限!
最重要的是,我学到了很多!下一次,我会使用NVIDIA的技能嵌入或终身学习,让机器人在学会战斗之前学会走路!
最后,如果您要观看我制作的视频,了解创建这个项目的完整过程,并观看机器人的战斗场景,请观看下面的视频(https://youtu.be/kpDfXqX7h1U):

我试着用新的强化学习论文中的算法让模拟机器人进行打斗(本人自制图片)
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:The Tournament of Reinforcement Learning: DDPG, SAC, PPO, I2A, Decision Transformer,作者:Anand Majmudar




























