













 语言模型的发展历程
语言模型的发展历程
语言模型(LM,Language Model)的发展历程可以清晰地划分为三个主要阶段:统计语言模型、神经网络语言模型以及基于Transformer的大语言模型。每个阶段的模型都在前一个阶段的基础上进行了改进和优化,使得语言模型的性能得到了显著提升。
 语言模型的发展历程
语言模型的发展历程
一、统计语言模型
什么是统计语言模型?统计语言模型是早期自然语言处理(NLP)中的重要工具,它们主要通过分析词序列的出现频率来预测下一个词。这种方法基于统计学的原理,利用大规模语料库中的词频信息来建模语言的概率分布。
代表模型:N-gram模型、隐马尔可夫模型(HMM)
- N-gram模型:这是最常见的统计语言模型之一,它基于马尔可夫假设,认为一个词出现的概率仅与其前面的n-1个词有关。N-gram模型简单易用,但存在数据稀疏和无法捕捉长距离依赖关系的问题。
- 隐马尔可夫模型(HMM):另一种重要的统计语言模型,通过引入隐藏状态来捕捉序列数据中的潜在结构。
 统计语言模型
统计语言模型
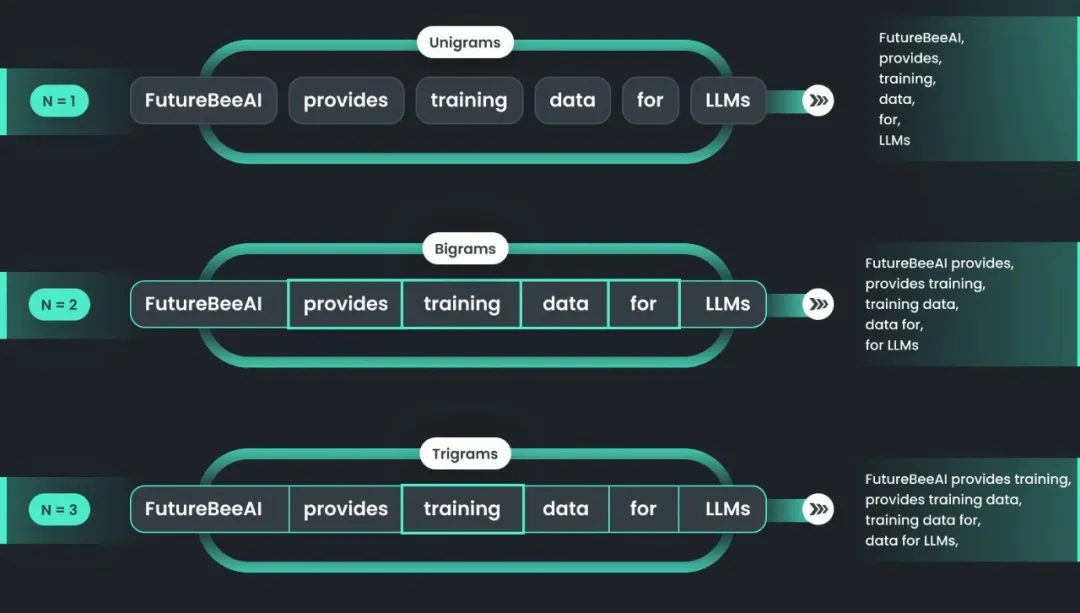
N-gram模型:N-gram模型是一种基于统计语言模型的文本分析算法,它用于预测文本中下一个词出现的概率,基于前面出现的n-1个词的序列。这里的n代表序列中元素的数量,因此称为N-gram。
- Unigram:N=1,每个单词的出现概率独立计算,不考虑上下文。
- Bigram:N=2,基于前一个单词预测当前单词的联合概率模型。
- Trigram:N=3,考虑前两个单词来预测当前单词的联合概率模型,更复杂但可能更准确。
 N-gram
N-gram
N-gram模型的工作原理:N-gram模型通过统计语料库中n-gram序列的频率,估计给定前n-1个元素后下一个元素出现的概率,从而实现文本预测。
- 语料库准备:首先,需要有一个大型的文本语料库,用于训练N-gram模型。
- 计算频率:然后,计算语料库中所有可能的n-gram序列的频率。
- 概率估计:根据这些频率,可以估计出给定n-1个词后,下一个词出现的概率。
- 预测:在预测阶段,给定一个词序列的前n-1个词,模型可以输出下一个词的概率分布,从而可以选择最可能的词作为预测结果。
N-gram
二、神经网络语言模型
什么是神经网络语言模型?随着深度学习技术的发展,神经网络开始被应用于语言建模任务中。神经网络语言模型通过引入神经网络结构来捕捉词与词之间的复杂关系,从而提高了语言模型的性能。
代表模型:NNLM、RNN、LSTM、GRU
- 神经网络语言模型(NNLM):由Bengio等人提出,通过嵌入层将单词映射到连续的向量空间中,并通过多个隐藏层来学习语言的内部结构。NNLM能够捕捉词与词之间的语义关系,提高了语言模型的预测能力。
- 循环神经网络(RNN)及其变体(LSTM、GRU):RNN通过引入循环连接来处理序列数据中的长期依赖关系。LSTM和GRU是RNN的改进版本,通过引入门控机制来解决梯度消失或梯度爆炸问题。
 神经网络语言模型
神经网络语言模型
NNLM:一种基于神经网络的方法来建模自然语言中的词语序列。与传统的统计语言模型(如n-gram模型)相比,NNLM能够捕捉更复杂的语言结构和语义信息,因为它利用了神经网络强大的非线性建模能力。
- 原理:利用神经网络来预测文本序列中下一个词或字符出现的概率的模型。
- 目的:通过建模词汇之间的概率关系,实现自然语言文本的生成或理解。
 NNLM
NNLM
NNLM的工作原理:通过嵌入层将输入的固定长度前文单词序列转换为连续向量表示,然后利用一个或多个隐藏层学习这些向量的语言结构,最后由输出层输出下一个单词的概率分布,以最大化给定前文条件下的单词预测准确性。
- 输入:NNLM的输入是一个固定长度的前文单词序列,用于预测下一个单词。每个单词通常由其词嵌入(word embedding)表示,即将单词映射到连续的向量空间中。
- 结构:NNLM通常包含一个嵌入层(embedding layer),用于将输入的单词转换为连续向量表示;一个或多个隐藏层(hidden layers),用于学习输入序列的语言结构;以及一个输出层(output layer),输出下一个单词的概率分布。
- 训练目标:最大化给定训练数据中序列的联合概率,即最大化给定前文单词的条件下,下一个单词出现的概率。这通常通过最小化负对数似然(negative log-likelihood)来实现。
 NNLM
NNLM
三、基于Transformer的大语言模型
什么是基于Transformer的大语言模型?基于Transformer的大语言模型在预训练阶段利用大规模语料库进行训练,然后在特定任务上进行微调,取得了惊人的效果。
代表模型:BERT、GPT系列
- BERT:由Google提出的一种基于Transformer的双向编码器表示模型。BERT在预训练阶段采用了遮蔽语言模型(Masked Language Model)和下一句预测(Next Sentence Prediction)两个任务来训练模型,提高了模型的语言表示能力。
- GPT系列:由OpenAI开发的基于Transformer的生成式预训练模型。GPT系列模型在预训练阶段采用了自回归语言建模任务来训练模型,能够生成连贯、自然的文本。随着模型规模的增大(如GPT-3、GPT-4等),GPT系列模型在多个NLP任务上取得了优异的表现。
 基于Transformer的大语言模型
基于Transformer的大语言模型
Transformer模型:Transformer模型由Vaswani等人在2017年提出,是一种基于自注意力机制的深度学习模型。它彻底摒弃了传统的循环神经网络结构,通过自注意力机制和位置编码来处理序列数据中的长期依赖关系和位置信息。
 Transformer
Transformer
1.Encoder-Decoder Architecture(编码器-解码器架构)
- Transformer模型通常包含编码器和解码器两部分。
- 编码器负责将输入序列转化为上下文向量(或称为隐藏状态),这些向量包含了输入序列的语义信息。
- 解码器则利用这些上下文向量生成输出序列。在生成过程中,解码器会逐步产生输出序列的每个token,并在每一步都考虑之前的输出和编码器的上下文向量。
2.Embedding(向量化)
- 在自然语言处理(NLP)中,输入的文本内容(如句子、段落或整个文档)首先被拆分成更小的片段或元素,这些片段通常被称为词元(tokens)。
- Embedding层负责将这些tokens转换为固定大小的实数向量,以捕捉这些tokens的语义信息。这个过程是通过查找一个预训练的嵌入矩阵来实现的,其中每一行代表一个token的向量表示。
3.Attention(注意力机制)
- 注意力机制的核心是计算查询向量(Q)、键向量(K)和值向量(V)之间的相互作用。对于每个token,它有一个对应的查询向量,而整个输入序列的tokens则共享一套键向量和值向量。
- 通过计算查询向量与每个键向量的相似度(通常使用缩放点积注意力),得到一组注意力权重。这些权重表示了在生成当前token的表示时,应该给予其他token多大的关注。
- 最后,将注意力权重应用于值向量,并进行加权求和,得到当前token的自注意力输出表示。
4.Position Encoding(位置编码)
- 由于Transformer模型本身无法识别序列中token的位置顺序,因此需要引入位置编码来补充这一信息。
- 位置编码可以是预定义的(如正弦和余弦函数)或可学习的参数。这些编码被添加到每个token的嵌入向量中,以帮助模型区分不同位置的token。
5.Multi-Head Attention(多头注意力机制)
- 多头注意力机制是自注意力机制的扩展,它允许模型在不同的表示空间中同时关注信息的多个方面。
- 通过将输入序列的嵌入向量分割成多个头(即多个子空间),并在每个头中独立计算自注意力,然后将这些头的输出拼接在一起,最后通过一个线性变换得到最终的输出表示。
- 多头注意力机制能够捕获更复杂的语义关系,增强模型的表达能力。
6.Feed-Forward Network(前馈网络)
- Transformer中的编码器和解码器都包含前馈网络(也称为全连接层)。
- 前馈网络用于进一步处理和转换注意力机制提取的特征,提取和整合更多有用的信息,以生成最终的输出表示。
7. Residual Connection and Layer Normalization(残差连接和层归一化)
- 在Transformer的每个子层(如多头注意力层、前馈网络层)之后,都会添加残差连接和层归一化操作。
- 残差连接有助于缓解深层网络中的梯度消失问题,而层归一化则有助于加速训练过程并提高模型的稳定性。
 Transformer
Transformer






















