原标题:CoVLA: Comprehensive Vision-Language-Action Dataset for Autonomous Driving
论文链接:https://arxiv.org/pdf/2408.10845
作者单位:Turing Inc. 东京大学 University of Tsukuba Keio Research Institute at SFC National Institute of Informatics

论文思路:
自动驾驶,特别是在复杂和意外场景中的导航,要求具备复杂的推理和规划能力。虽然多模态大语言模型(MLLMs)在这方面提供了一个有前途的途径,但其应用主要局限于理解复杂的环境上下文或生成高层次的驾驶指令,只有少数研究将其应用扩展到端到端路径规划。一个主要的研究瓶颈是缺乏包含视觉、语言和动作的大规模标注数据集。为了解决这个问题,本文提出了CoVLA(Comprehensive Vision-Language-Action)数据集,这是一个包含超过80小时真实驾驶视频的广泛数据集。该数据集利用了一种基于自动数据处理和描述(caption)生成流程的新颖且可扩展的方法,生成了与详细自然语言描述的驾驶环境和操作相匹配的精确驾驶轨迹。这种方法利用了车内传感器的原始数据,使其在规模和标注丰富性上超越了现有的数据集。使用CoVLA,本文研究了能够在各种驾驶场景中处理视觉、语言和动作的MLLMs的驾驶能力。本文的结果显示了本文的模型在生成连贯的语言和动作输出方面的强大能力,强调了视觉-语言-动作(VLA)模型在自动驾驶领域的潜力。通过提供一个全面的平台用于训练和评估VLA模型,该数据集为构建稳健、可解释和数据驱动的自动驾驶系统奠定了基础,助力于更安全和更可靠的自动驾驶车辆。
主要贡献:
- 本文介绍了CoVLA数据集,这是一个大规模数据集,提供了多种驾驶场景的轨迹目标,以及详细的逐帧情境描述。
- 本文提出了一种可扩展的方法,通过传感器融合准确估计轨迹,并自动生成关键驾驶信息的逐帧文本描述。
- 本文开发了CoVLA-Agent,这是一种基于CoVLA数据集的新型VLA模型,用于可解释的端到端自动驾驶。本文的模型展示了持续生成驾驶场景描述和预测轨迹的能力,为更可靠的自动驾驶铺平了道路。
论文设计:
自动驾驶技术面临的一个关键挑战在于应对多样且不可预测的驾驶环境的“长尾”问题[35, 63]。自动驾驶车辆不仅需要在常见场景中导航,还必须应对罕见和复杂的情况,这就需要广泛的世界知识和高级推理能力[20]。这要求对环境有深刻的理解,并且具备超越物体识别的推理能力,能够解释其行为并据此规划行动。视觉-语言-动作(VLA)模型通过无缝整合视觉感知、语言理解和动作规划,已成为实现这一目标的有前途的途径。近期在VLA领域的进展,特别是在机器人[4, 28, 40]和自动驾驶[45]方面,展示了其在实现更健壮和智能的驾驶系统方面的潜力。
然而,将VLA模型应用于自动驾驶的一个主要障碍是缺乏有效结合视觉数据、语言描述和驾驶动作的大规模数据集。现有的数据集在规模和全面标注方面往往不足,尤其是语言方面,通常需要繁重的人工工作。这限制了能够处理现实世界驾驶复杂性的健壮VLA模型的发展和评估。
本文介绍了CoVLA(Comprehensive Vision-Language-Action)数据集,这是一个旨在克服现有局限性的新型大规模数据集。CoVLA数据集利用可扩展的自动化标注和描述生成方法,创建了一个包含10,000个真实驾驶场景、总计超过80小时视频的丰富数据集。每个30秒的场景都包含精确的驾驶路径和详细的自然语言描述,这些描述来源于同步的前置相机录像和车内传感器数据。这个丰富的数据集允许对驾驶环境和代理行为进行更深入的理解。为了展示其在推进自动驾驶研究方面的有效性,本文开发了CoVLA-Agent,这是一种基于本文数据集进行训练的VLA模型,用于轨迹预测和交通场景描述生成。本文的研究结果表明,即使在需要复杂和高级判断的情况下,本文的VLA模型也能够做出一致且精确的预测。
本节深入介绍了CoVLA数据集,详细描述了其结构、内容以及用于创建这一宝贵自动驾驶研究资源的方法。本文重点介绍了其对多样化真实世界驾驶场景的覆盖、同步的多模态数据流(前置相机、车内信号及其他传感器)以及大规模标注数据:10,000个驾驶场景,总计超过80小时的视频,每个场景都包含精确的逐帧轨迹和描述标注。为了创建这个广泛的VLA数据集,本文开发了一种新颖且可扩展的方法,从原始数据中自动生成场景描述和真实轨迹。

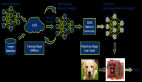
图1. CoVLA框架概述。本文开发了CoVLA数据集,这是一个用于自动驾驶的综合数据集,包含独特的10,000个视频片段、描述驾驶场景的逐帧语言描述以及未来的轨迹动作。本文还展示了CoVLA-Agent,这是一种基于VLM的路径规划模型,能够预测车辆的未来轨迹,并提供其行为和推理的文本描述。

表1. 含有语言和动作数据的驾驶数据集比较。

图2. 数据集生成 pipeline 概述。本文自动标注视频帧和传感器信号以生成轨迹和其他标签。此外,本文对视频帧应用自动描述生成,以生成行为和推理的描述。

图3. CoVLA数据集的示例帧。显示了估计的轨迹(绿色线)和由描述生成模型生成的描述。关键对象以蓝色粗体文本突出显示,而描述中的错误以红色粗体文本显示。

图4. 车辆速度和转向角的数据分布。红色条表示采样前的分布,而黄色条显示采样后的分布。请注意,为了清晰展示,(b)中使用了对数刻度。
在本节中,本文介绍了基线模型CoVLA-Agent的开发和评估方法,该模型利用CoVLA数据集的丰富性来完成自动驾驶任务。本文详细描述了实验设置,包括数据集、模型配置、训练过程和评估指标,并对结果进行了分析。
架构:如图5所示,CoVLA-Agent是一个为自动驾驶设计的VLA模型。本文使用预训练的Llama-2(7B)[52]作为语言模型,并使用CLIP ViT-L(224×224像素)[43]作为视觉编码器。此外,本文的模型将自车速度作为输入,通过多层感知器(MLP)转换为嵌入向量。CLIP ViT-L提取的视觉特征与速度嵌入和文本嵌入拼接在一起,然后输入到Llama-2模型中。对于轨迹预测,使用特殊的 tokens 作为轨迹查询。这些轨迹查询的输出经过MLP层处理,生成10个(x, y, z)坐标的序列,表示车辆相对于当前位置的预测轨迹,覆盖三秒的时间范围。
训练:基于这种架构,本文在两个任务上训练CoVLA-Agent,分别是交通场景描述生成和轨迹预测。对于交通场景描述生成,本文使用交叉熵损失作为损失函数;对于轨迹预测,本文采用均方误差损失。最终,训练的目标是最小化一个组合损失函数,其中两个损失被等权重对待。

图5. CoVLA-Agent的架构。
实验结果:

图6. CoVLA-Agent在各种交通场景下的轨迹预测结果。红线表示在预测描述条件下的预测轨迹,蓝线表示在真实描述条件下的预测轨迹,绿线表示真实轨迹。

表2. 不同条件的定量比较。

表3. 平均ADE和FDE最大的前10个单词。这些单词对应的是从单帧中难以估计的运动。明确表示运动的单词以粗体显示。
总结:
本文介绍了CoVLA数据集,这是一个用于自动驾驶的VLA模型的新型数据集。通过利用可扩展的自动化方法,本文构建了一个大规模、全面的数据集,并丰富了详细的语言标注。基于这个稳健的数据集,本文开发了CoVLA-Agent,这是一种先进的VLA自动驾驶模型。评估结果强调了该模型在生成连贯的语言和动作输出方面的强大能力。这些发现突显了VLA多模态模型的变革潜力,并为未来的自动驾驶研究创新铺平了道路。