大家好,这里是物联网心球。
谈到高性能编程,我们绕不过一个问题高效内存分配,通常我们会使用malloc和free函数来申请和释放内存。
那么我们习以为常的malloc和free函数,真的能满足高性能编程的要求吗?
带着这个问题我们来深入理解malloc和free函数实现原理。
1.ptmalloc工作原理
malloc和free函数属于glibc库的ptmalloc模块,我们得通过学习glibc源码了解ptmalloc工作原理。源码位置:glibc/malloc/malloc.c。
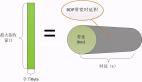
1.1 ptmalloc软件架构
 图片
图片
ptmalloc内存池是一个比较复杂的软件模块,会涉及到malloc_state,malloc_chunk,mmap,brk等概念。
ptmalloc通过brk(堆内存)或者mmap(内存映射)系统调用从内核申请一大块连续的内存,申请的内存由top chunk管理,用户程序调用malloc函数从内存池申请内存(chunk),如果内存池有空闲的chunk,则从空闲的chunk返回给用户程序,如果没有空闲的chunk,则从top chunk裁剪出可用的chunk返回给用户程序。
用户程序调用free函数将会释放chunk至空闲链表或top chunk。
我们将围绕两个比较重要的概念来进行讲解:malloc_state和malloc_trunk。
1) malloc_state
ptmalloc由struct malloc_state统一管理,定义如下:
malloc_state有几个重要成员:fastbinsY,top,bins,binmaps,next。
- fastbinsY数组:fastbins,用于存储16-160字节chunk的空闲链表。
- bins数组:bins分为三个部分:unsortedbins,smallbins,largebins:
unsortedbins:chunk缓存区,用于存储从fastbins合并的空闲chunk。
smallbins:空闲链表,用于存储32-1024字节的chunk。
largebins:空闲链表,用于存储大于1024字节的chunk。
- top chunk:超级chunk,ptmalloc内存池。
- binmap:可用bins位图,用于快速查找可用bin。
- next:单向链表指针,用于连接不同的malloc_state。
进程通常会有多个malloc_state,进程启动时,由主线程创建第一个malloc_state称为主分配区(main_state),主分配区的内存通过brk(堆)或者malloc(内存映射)从内核申请而来,这也解释了为什么malloc可以从堆区分配内存。
如果程序所有的线程都使用主分配区分配内存,那么多线程会存在竞争关系,为了解决这个问题,进程会根据实际情况动态创建非主分配区(thread_state),thread_state分配区内存池内存只能通过mmap从内核申请,当主分配区被使用或者没有可用的分配区时,系统会创建一个新的分配区,这样可以减少多线程竞争,提高内存分配效率。
当然malloc_state数量并不是没有限制,通常malloc_state数量最多为CPU核心数的数倍,超过该阈值后将不能再创建新的分配区。如果一个程序线程数量太多,会加剧对分配区的竞争。
 图片
图片
2)malloc_chunk
ptmalloc以malloc_chunk为单位申请和释放内存,struct malloc_chunk定义如下:
chunk是ptmalloc最难理解的一个概念,只有理解了chunk才能真正理解ptmalloc。
 图片
图片
chunk是从内存池裁剪下来的内存块,这个内存块由malloc_chunk管理。
malloc_chunk对象mchunk_prev_size和mchunk_size成员为chunk头部,chunk头部将会伴随chunk整个生命周期,用于记录和识别chunk。
内存块除了chunk头部外就是内存区域,当chunk分配给用户程序后,内存区域用于存储用户数据,如果chunk处于空闲状态,将会借用内存区域前16个字节作为链表指针,将chunk插入空闲链表。
3)fastbins数组
 图片
图片
fastbins数组长度为10,每个数组元素都是一个chunk链表头,10个链表分别存储16-160字节的chunk,步长为16字节,malloc函数申请小于160字节的内存时,从fastbins空闲链表查找匹配的chunk进行分配。
4)bins数组
 图片
图片
bins数组长度为128,可以分为三部分:unsortedbins,smallbins,largebins。
unsortedbins:bins数组0号元素,unsortedbins是一个特殊的链表,该链表是一个chunk缓存区,用于存储从fastbins合并的空闲chunk,目的是为了回收小块内存,解决内存碎片问题。
smallbins:bins数组1-63号元素,和fastbins功能一样,smallbins用于存储32-1008字节的空闲chunk。
largebins:bins数组64-127号元素,用于存储超过1024字节大小的空闲chunk。
5)top chunk
top chunk可以理解为超级chunk,当bins空闲链表中没有匹配的chunk分配给用户程序时,top chunk将会被裁剪,裁剪成用户chunk和剩余chunk,用户chunk分配给用户程序,剩余chunk继续由top chunk管理。
如果top chunk内存不足,调用brk或者mmap从内核申请内存对top chunk扩容,并将扩容后的内存块裁剪分配给用户程序。
1.2 malloc函数流程分析
 图片
图片
用户程序调用malloc函数申请内存时,首先会去查询空闲链表,如果空闲链表没有足够的chunk,则去查询top chunk进行内存分配。
如果top chunk没有足够的内存,说明内存池内存不足,需要通过brk或者mmap扩容。
注意:内存池内存不够,并不一定表示内存都被用完,也有可能是存在内存碎片。
1.3 free函数流程分析
 图片
图片
用户程序调用free函数释放内存,优先将内存释放至空闲链表,如果释放至空闲链表失败,则释放至top chunk,如果释放的内存比较大,可能通过munmap或者brk回收至内核。
2.ptmalloc高并发测试
前一小节,我们花了比较多的精力去学习ptmalloc实现原理,对于很多项目来说,我们不需要花过多时间去研究ptmalloc实现原理,直接使用malloc和free函数即可,然而对于高并发项目,我们得深入理解ptmalloc实现原理,从而清楚地知道ptmalloc存在的问题,为后续优化打好基础。
2.1 ptmalloc常见问题
通过学习ptmalloc实现原理,我们会发现ptmalloc存在两个问题:锁竞争问题和内存碎片问题。
- 锁竞争问题
struct malloc_state结构定义了一个mutex成员,多线程想要通过分配区进行内存分配时需要加锁,频繁分配内存会导致频繁加锁。 - 内存碎片问题
 图片
图片
ptmalloc通过mmap或brk从内核申请一大块连续的内存,调用malloc函数会将这块大的内存裁剪成一块块小的内存,如果其中某些小的内存块一直不释放至内存池,将导致小的内存块无法合并成大的内存块,造成内存碎片,严重的情况会导致内存泄露,程序退出。
2.2 ptmalloc高并发测试
1)测试代码
采用多个线程循环申请和释放内存,每次随机申请SIZE_THREHOLD范围大小内存,如果申请的内存小于LEAK_THREHOLD大小,则申请的内存不释放,人为制造内存泄露,并实时统计泄露内存总量。
测试项:频繁加锁测试,内存碎片测试。
- 频繁加锁测试方法:
通过:strace -tt -f -e trace=futex ./a.out命令执行测试程序,观察是否调用futex系统调用加锁。
- 内存碎片测试
通过:strace -tt -f -e trace=mprotect,brk ./a.out命令执行测试程序,观察是否调用mprotect或者brk进行扩容。
统计程序已使用内存总量,内存泄露总量,计算内存碎片总量:
内存碎片总量=已使用内存总量-内存泄露总量。
测试代码如下:
2)测试结果
- 频繁加锁测试
通过strace -tt -f -e trace=futex ./a.out命令观察到测试程序频繁的调用futex系统调用,为了保证线程安全,malloc和free函数需要频繁加锁,频繁加锁会影响内存分配的效率。

- 内存碎片测试
1.程序刚启动时,内存泄露总量为1.8MB,此时系统可用内存总量为2724MB。
 图片
图片
 图片
图片
2. 程序泄露内存总量至162MB时,此时系统可用内存总量为2474MB。
 图片
图片
 图片
图片
用户程序使用内存总量为:2724 - 2474 = 250MB。泄露内存总量为162MB,内存碎片总量为88MB。
通过strace -tt -f -e trace=mprotect,brk ./a.out命令观察到,ptmalloc频繁的通过mprotect或者brk进行扩容。
 图片
图片
3.总结
- malloc和free函数不适用于多线程申请和释放内存使用场景,存在频繁加锁的问题。
- malloc和free函数不适用于长期占用内存的使用场景,长期占用内存会导致内存碎片问题。
- 对并发要求不高的场景可以使用malloc和free函数,高并发场景需要使用更高效的内存池。