














译者 | 布加迪
审校 | 重楼
ChatGPT和Bard等大语言模型(LLM)的兴起已极大地改变了许多人的工作、交流和学习方式,这已不是什么秘密。但除了取代搜索引擎外,LLM还有其他应用。最近,数据科学家已重新改造LLM用于时间序列预测。
时间序列数据在从金融市场到气候科学的各个领域无处不在。在人工智能进步的推动下,LLM 正在彻底改变我们处理和生成人类语言的方式。本文深入研究时间序列语言模型如何提供创新的预测和异常检测模型。
什么是时间序列模型?
大体上说,时间序列语言模型被重新改造后用于处理时间序列数据,而不是处理文本、视频或图像数据。它们将传统时间序列分析方法的优点与语言模型的高级预测功能相结合。当数据与预测或预期结果有明显偏差时,可以使用强大的预测来检测异常。时间序列语言模型和传统LLM之间的一些显著差异如下:
- 数据类型和训练:ChatGPT 之类的传统 LLM 用文本数据进行训练,但时间序列语言模型用连续的数值数据进行训练。具体来说,预训练针对大型、多样化的时间序列数据集(实际数据集和合成数据集)进行,这使模型能够很好地适用于不同的领域和应用。
- 词元化:时间序列语言模型将数据分解为块而不是文本词元(块是指时间序列数据的连续段、块或窗口)。
- 输出生成:时间序列语言模型生成未来数据点的序列,而不是单词或句子。
- 架构调整:时间序列语言模型结合特定的设计选择来处理时间序列数据的时间特性,比如可变上下文和范围长度。
与分析和预测时间序列数据的传统方法相比,时间序列语言模型具有多个显著优势。不像ARIMA 等传统方法通常需要广泛的领域专业知识和手动调整,时间序列语言模型则利用先进的机器学习技术自动从数据中学习。这使得它们在传统模型可能不尽如人意的众多应用领域成为强大且多功能的工具。
- 零样本性能:时间序列语言模型可以对未见过的新数据集进行准确预测,而无需额外的训练或微调。这尤其适用于新数据频繁出现的快速变化的环境。零样本方法意味着用户不必花费大量资源或时间来训练模型。
- 复杂模式处理:时间序列语言模型可以捕获数据中复杂的非线性关系和模式,ARIMA 或 GARCH等传统的统计模型可能发现不了这些关系和模式,尤其是对于未见过或未预处理的数据。此外,调整统计模型可能很棘手,需要深厚的领域专业知识。
- 效率:时间序列语言模型并行处理数据。与通常按顺序处理数据的传统模型相比,这大大缩短了训练和推理时间。此外,它们可以在单单一个步骤中预测更长序列的未来数据点,从而减少所需的迭代步骤数。
时间序列语言模型的实际运用
一些用于预测和预测分析的最流行的时间序列语言模型包括:谷歌的TimesFM、IBM的TinyTimeMixer和AutoLab的MOMENT。
谷歌的TimesFM可能最容易使用。使用pip安装它,初始化模型,并加载检查点。然后,你可以对输入数组或Pandas DataFrames执行预测。比如:
<span style="font-weight: 400;">```python</span>
import pandas as pd
# e.g. input_df is
# unique_id ds y
# 0 T1 1975-12-31 697458.0
# 1 T1 1976-01-31 1187650.0
# 2 T1 1976-02-29 1069690.0
# 3 T1 1976-03-31 1078430.0
# 4 T1 1976-04-30 1059910.0
# ... ... ... ...
# 8175 T99 1986-01-31 602.0
# 8176 T99 1986-02-28 684.0
# 8177 T99 1986-03-31 818.0
# 8178 T99 1986-04-30 836.0
# 8179 T99 1986-05-31 878.0
forecast_df = tfm.forecast_on_df(
inputs=input_df,
freq="M", # monthly
value_name="y",
num_jobs=-1,
)谷歌的TimesFM还支持微调和协变量支持,这是指模型能够结合和利用额外的解释变量(协变量)以及主要时间序列数据,以提高预测的准确性和稳健性。你可以在此论文(https://arxiv.org/pdf/2310.10688)中详细了解谷歌的TimesFM工作原理。
IBM的TinyTimeMixer包含用于对多变量时间序列数据执行各种预测的模型和示例。此笔记本(https://github.com/ibm-granite/granite-tsfm/blob/main/notebooks/hfdemo/ttm_getting_started.ipynb)重点介绍了如何使用TTM(TinyTimMixer)对数据执行零样本预测和少样本预测。下面的屏幕截图显示了TTM生成的一些估计值:
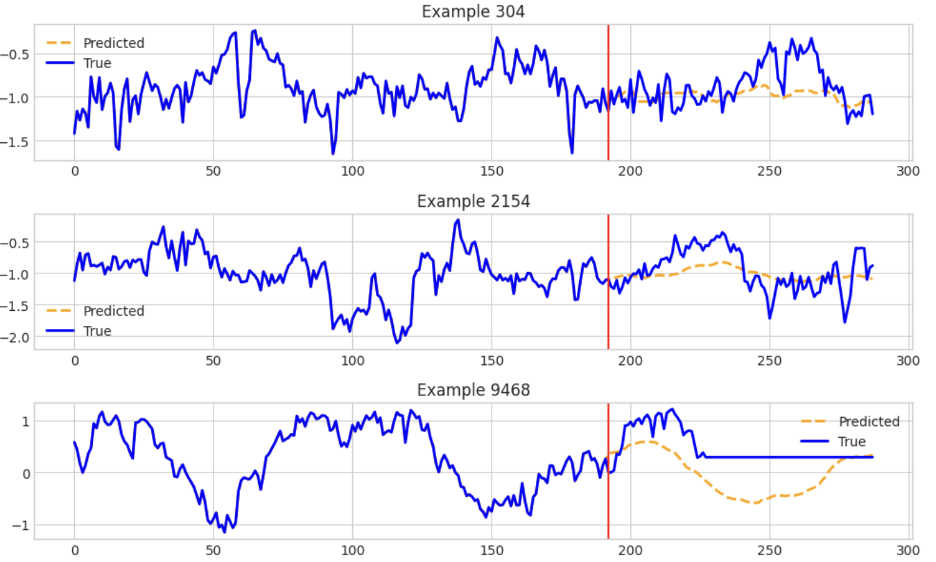
最后,AutoLab的MOMENT拥有预测和异常检测方法,并附有一目了然的示例。它擅长长范围预测。举例来说,该笔记本表明了如何通过先导入模型来预测单变量时间序列数据:
```python
from momentum import MOMENTPipeline
model = MOMENTPipeline.from_pretrained(
"AutonLab/MOMENT-1-large",
model_kwargs={
'task_name': 'forecasting',
'forecast_horizon': 192,
'head_dropout': 0.1,
'weight_decay': 0,
'freeze_encoder': True, # Freeze the patch embedding layer
'freeze_embedder': True, # Freeze the transformer encoder
'freeze_head': False, # The linear forecasting head must be trained
},
)
```下一步是使用你的数据训练模型进行正确的初始化。在每个训练轮次之后,都会针对测试数据集评估模型。在评估循环中,模型使用output = model(timeseries, input_mask) 这一行进行预测。
```python
while cur_epoch < max_epoch:
losses = []
for timeseries, forecast, input_mask in tqdm(train_loader, total=len(train_loader)):
# Move the data to the GPU
timeseries = timeseries.float().to(device)
input_mask = input_mask.to(device)
forecast = forecast.float().to(device)
with torch.cuda.amp.autocast():
output = model(timeseries, input_mask)
```结语
时间序列语言模型是预测分析领域的重大进步,它们将深度学习的强大功能与时间序列预测的复杂需求结合在一起。它们能够执行零样本学习、整合协变量支持,并高效处理大量数据,这使它们成为各行各业的革命性工具。随着我们见证这一领域的快速发展,时间序列 语言模型的潜在应用和优势只会不断扩大。
若要存储时间序列数据,请查看领先的时间序列数据库InfluxDB Cloud 3.0。你可以利用InfluxDB v3 Python客户端库和InfluxDB来存储和查询时间序列数据,并运用时间序列LLM进行预测和异常检测。你可以查看下列资源开始上手:
- 客户端库深度探究:Python(第 1 部分):https://www.influxdata.com/blog/client-library-deep-dive-python-part-1/
- 客户端库深度探究:Python(第 2 部分):https://www.influxdata.com/blog/client-library-deep-dive-python-part-2/
原文标题:Transform Predictive Analytics With Time Series Language Models,作者:Anais Dotis-Georgiou

























