












尽管LLMs的巨大规模使其在广泛的应用场景中表现卓越,但这也为其在实际问题中的应用带来了挑战。本文将探讨如何通过压缩LLMs来应对这些挑战。我们将介绍关键概念,然后通过具体的Python代码实例进行演示。

2023年人工智能领域的主导思想是"更大即更好",改进语言模型的方程相对简单:更多数据 + 更多参数 + 更多计算资源 = 更优性能。
虽然这种思路可能仍然适用(GPT-5即将问世?),但使用超过100B参数的模型显然面临挑战。例如一个使用FP16的100B参数模型仅存储就需要200GB空间!
大多数消费级设备(如智能手机、平板电脑、笔记本电脑)无法处理如此庞大的模型。那么,我们是否可以在不损失性能的前提下缩小这些模型呢?
模型压缩
模型压缩旨在在保持性能的同时减小机器学习模型的规模[2]。这种方法对(大型)神经网络特别有效,因为它们通常存在过度参数化的问题(即包含冗余计算单元)[3]。
模型压缩的主要优势在于降低推理成本。这意味着强大的机器学习模型可以更广泛地应用(例如,在个人笔记本电脑上本地运行LLMs),将人工智能集成到消费产品中的成本降低,以及支持设备端推理,从而增强用户隐私和安全性[3]。
压缩模型的三种方法
模型压缩技术多种多样。本文将重点介绍三大类方法。
- 量化 — 使用低精度数据类型表示模型
- 剪枝 — 移除模型中不必要的组件
- 知识蒸馏 — 利用大型模型训练小型模型
这些方法都相互独立,可以结合多种技术以实现最大化压缩效果!
1、量化
尽管"量化"这个术语听起来可能晦涩复杂,但其核心概念相对简单。它指的是降低模型参数的精度。可以将这个过程类比为将高分辨率图像转换为低分辨率图像,同时保持图像的主要特征。

量化技术主要分为两类:训练后量化(PTQ)和量化感知训训练(QAT)。
训练后量化(PTQ)
对于给定的神经网络,训练后量化(PTQ)通过将参数替换为低精度数据类型来压缩模型(例如,从FP16转换为INT-8)。这是减少模型计算需求最快速和简单的方法之一,因为它无需额外的训练或数据标注。
虽然这是一种相对简便的降低模型成本的方法,但过度使用这种技术进行量化(例如,从FP16转换为INT4)通常会导致性能下降,这限制了PTQ的潜在收益。
量化感知训练(QAT)
在需要更高压缩率的情况下,可以通过使用低精度数据类型从头开始训练模型来克服PTQ的局限性。这就是量化感知训练(QAT)的核心思想。
尽管这种方法在技术上更具挑战性,但它可以产生显著更小且性能良好的模型。例如,BitNet架构使用三元数据类型(即1.58位)就达到了与原始Llama LLM相当的性能!
PTQ和从头开始的QAT之间存在较大的技术差距。介于两者之间的一种方法是量化感知微调,它包括在量化后对预训练模型进行额外的训练[3]。
2、剪枝
剪枝的目标是移除对模型性能影响较小的组件[7]。这种方法之所以有效,是因为机器学习模型(特别是大型模型)往往会学习冗余和噪声结构。
这个过程可以类比为修剪树木中的枯枝。移除这些枯枝可以减小树的体积而不会损害树的健康。

剪枝方法可以分为两类:非结构化剪枝和结构化剪枝。
非结构化剪枝
非结构化剪枝从神经网络中移除不重要的权重(即将其值设为零)。早期的工作如Optimal Brain Damage和Optimal Brain Surgeon通过估计剪枝对损失函数的影响来计算网络中每个参数的重要性分数。
最近基于幅度的方法(即移除绝对值最小的权重)因其简单性和可扩展性而变得更加流行。
虽然非结构化剪枝的细粒度特性可以显著减少参数数量,但这些收益通常需要专门的硬件才能实现。非结构化剪枝会导致稀疏矩阵运算(即乘以包含大量零的矩阵),而标准硬件在执行这类运算时并不比非稀疏运算更有效。
结构化剪枝
相比之下,结构化剪枝从神经网络中移除整个结构(例如注意力头、神经元和层)。这种方法避免了稀疏矩阵运算的问题,因为可以直接从模型中删除整个矩阵,而不是单个参数。
虽然识别待剪枝结构的方法多种多样,但其基本原则都是试图移除对性能影响最小的结构。参考文献[5]提供了结构化剪枝方法的详细综述。
3、知识蒸馏
知识蒸馏是一种将知识从(较大的)教师模型转移到(较小的)学生模型的技术[5]。一种常见的实现方法是使用教师模型生成预测,然后用这些预测来训练学生模型。从教师模型的输出logits(即所有可能的下一个标记的概率)中学习,可以提供比原始训练数据更丰富的信息,从而提高学生模型的性能[8]。
最新的蒸馏应用完全摒弃了对logits的依赖,转而从教师模型生成的合成数据中学习。一个典型的例子是斯坦福大学的Alpaca模型,它使用OpenAI的text-davinci-003(即原始ChatGPT模型)生成的合成数据对LLaMa 7B(基础)模型进行了微调,使其能够遵循用户指令[9]。
代码示例:使用知识蒸馏和量化压缩文本分类器
在了解了各种压缩技术的基本原理后,让我们通过一个Python实例来展示如何实际应用这些技术。在这个例子中,我们将压缩一个具有100M参数的模型,该模型用于将URL分类为安全或不安全(即钓鱼网站)。
我们首先使用知识蒸馏将100M参数模型压缩为50M参数模型。然后,通过应用4位量化,我们进一步将内存占用减少了3倍,最终得到的模型比原始模型小7倍。
首先,我们导入必要的库:
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from transformers import DistilBertForSequenceClassification, DistilBertConfig
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from sklearn.metrics import accuracy_score, precision_recall_fscore_support然后,我们从Hugging Face Hub加载数据集。这包括训练集(2100行)、测试集(450行)和验证集(450行)。
data = load_dataset("shawhin/phishing-site-classification")接下来,加载教师模型。我们将模型加载到Google Colab提供的T4 GPU上。
# 使用Nvidia GPU
device = torch.device('cuda')
# 加载教师模型和分词器
model_path = "shawhin/bert-phishing-classifier_teacher"
tokenizer = AutoTokenizer.from_pretrained(model_path)
teacher_model = AutoModelForSequenceClassification.from_pretrained(model_path)
.to(device)教师模型是Google的bert-base-uncased模型的微调版本,用于对钓鱼网站URL进行二元分类。
对于学生模型,我们基于distilbert-base-uncased从头初始化一个新模型。我们通过移除两层和减少剩余层中的四个注意力头来修改架构。
# 加载学生模型
my_config = DistilBertConfig(n_heads=8, n_layers=4) # 每层减少4个头,总共减少2层
student_model = DistilBertForSequenceClassification
.from_pretrained("distilbert-base-uncased",
config=my_config,)
.to(device)在训练学生模型之前,我们需要对数据集进行标记化处理。这一步至关重要,因为模型要求输入文本以特定格式表示。我们根据每个批次中最长样本的长度对样本进行填充。这允许将批次表示为PyTorch张量。
# 定义文本预处理函数
def preprocess_function(examples):
return tokenizer(examples["text"], padding='max_length', truncation=True)
# 对所有数据集进行标记化
tokenized_data = data.map(preprocess_function, batched=True)
tokenized_data.set_format(type='torch',
columns=['input_ids', 'attention_mask', 'labels'])训练前的另一个关键步骤是为模型定义评估策略。以下函数用于计算给定模型和数据集的准确率、精确率、召回率和F1分数。
# 评估模型性能的函数
def evaluate_model(model, dataloader, device):
model.eval() # 将模型设置为评估模式
all_preds = []
all_labels = []
# 禁用梯度计算
with torch.no_grad():
for batch in dataloader:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
# 前向传播获取logits
outputs = model(input_ids, attention_mask=attention_mask)
logits = outputs.logits
# 获取预测结果
preds = torch.argmax(logits, dim=1).cpu().numpy()
all_preds.extend(preds)
all_labels.extend(labels.cpu().numpy())
# 计算评估指标
accuracy = accuracy_score(all_labels, all_preds)
precision, recall, f1, _ = precision_recall_fscore_support(all_labels,
all_preds,
average='binary')
return accuracy, precision, recall, f1现在开始训练过程。为了使学生模型能够同时从训练集的真实标签(硬目标)和教师模型的logits(软目标)中学习,我们需要构建一个特殊的损失函数,该函数考虑这两种目标。
这是通过将学生和教师输出概率分布的KL散度与学生logits与真实标签的交叉熵损失相结合来实现的。
# 计算蒸馏损失和硬标签损失的函数
def distillation_loss(student_logits, teacher_logits,
true_labels, temperature, alpha):
# 从教师logits计算软目标
soft_targets = nn.functional.softmax(teacher_logits / temperature, dim=1)
student_soft = nn.functional.log_softmax(student_logits / temperature, dim=1)
# 蒸馏的KL散度损失
distill_loss = nn.functional.kl_div(student_soft,
soft_targets,
reduction='batchmean') * (temperature ** 2)
# 硬标签的交叉熵损失
hard_loss = nn.CrossEntropyLoss()(student_logits, true_labels)
# 结合损失
loss = alpha * distill_loss + (1.0 - alpha) * hard_loss
return loss定义超参数、优化器以及训练和测试数据加载器。
# 超参数
batch_size = 32
lr = 1e-4
num_epochs = 5
temperature = 2.0
alpha = 0.5
# 定义优化器
optimizer = optim.Adam(student_model.parameters(), lr=lr)
# 创建训练数据加载器
dataloader = DataLoader(tokenized_data['train'], batch_size=batch_size)
# 创建测试数据加载器
test_dataloader = DataLoader(tokenized_data['test'], batch_size=batch_size)最后使用PyTorch训练学生模型。
# 将学生模型设置为训练模式
student_model.train()
# 训练模型
for epoch in range(num_epochs):
for batch in dataloader:
# 准备输入
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
# 禁用教师模型的梯度计算
with torch.no_grad():
teacher_outputs = teacher_model(input_ids,
attention_mask=attention_mask)
teacher_logits = teacher_outputs.logits
# 学生模型前向传播
student_outputs = student_model(input_ids,
attention_mask=attention_mask)
student_logits = student_outputs.logits
# 计算蒸馏损失
loss = distillation_loss(student_logits, teacher_logits, labels,
temperature, alpha)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"第 {epoch + 1} 轮训练完成,损失: {loss.item()}")
# 评估教师模型
teacher_accuracy, teacher_precision, teacher_recall, teacher_f1 =
evaluate_model(teacher_model, test_dataloader, device)
print(f"教师模型 (测试集) - 准确率: {teacher_accuracy:.4f},
精确率: {teacher_precision:.4f},
召回率: {teacher_recall:.4f},
F1分数: {teacher_f1:.4f}")
# 评估学生模型
student_accuracy, student_precision, student_recall, student_f1 =
evaluate_model(student_model, test_dataloader, device)
print(f"学生模型 (测试集) - 准确率: {student_accuracy:.4f},
精确率: {student_precision:.4f},
召回率: {student_recall:.4f},
F1分数: {student_f1:.4f}")
print("\n")
# 将学生模型重新设置为训练模式
student_model.train()训练结果如下图所示。值得注意的是,在训练结束时,学生模型在所有评估指标上都超过了教师模型。
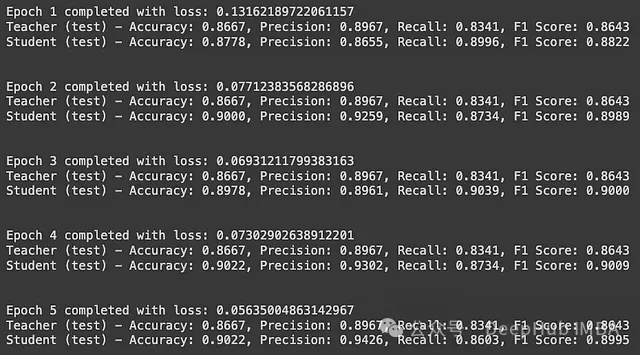
最后一步,我们可以在独立的验证集上评估模型,即未用于训练模型参数或调整超参数的数据。
# 创建验证数据加载器
validation_dataloader = DataLoader(tokenized_data['validation'], batch_size=8)
# 评估教师模型
teacher_accuracy, teacher_precision, teacher_recall, teacher_f1 =
evaluate_model(teacher_model, validation_dataloader, device)
print(f"教师模型 (验证集) - 准确率: {teacher_accuracy:.4f},
精确率: {teacher_precision:.4f},
召回率: {teacher_recall:.4f},
F1分数: {teacher_f1:.4f}")
# 评估学生模型
student_accuracy, student_precision, student_recall, student_f1 =
evaluate_model(student_model, validation_dataloader, device)
print(f"学生模型 (验证集) - 准确率: {student_accuracy:.4f},
精确率: {student_precision:.4f},
召回率: {student_recall:.4f},
F1分数: {student_f1:.4f}")我们再次观察到学生模型的表现超过了教师模型。

到目前为止,我们已经将模型从109M参数(438 MB)压缩到52.8M参数(211 MB)。我们还可以更进一步,对学生模型进行量化处理。
我们使用QLoRA论文中描述的4位NormalFloat数据类型存储模型参数,并使用bfloat16进行计算。
from transformers import BitsAndBytesConfig
# 以4位精度加载模型
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype = torch.bfloat16,
bnb_4bit_use_double_quant=True
)
model_nf4 = AutoModelForSequenceClassification.from_pretrained(model_id,
device_map=device,
quantization_config=nf4_config)然后我们可以在验证集上评估量化后的模型。
# 评估量化后的学生模型
quantized_accuracy, quantized_precision, quantized_recall, quantized_f1 =
evaluate_model(model_nf4, validation_dataloader, device)
print("量化后性能")
print(f"准确率: {quantized_accuracy:.4f},
精确率: {quantized_precision:.4f},
召回率: {quantized_recall:.4f},
F1分数: {quantized_f1:.4f}")
量化后学生模型在验证集上的表现。
再次观察到压缩后性能略有提升。这可以从奥卡姆剃刀原理的角度理解,该原理认为在其他条件相同的情况下,更简单的模型通常更优。
在这个案例中,原始模型可能对这个二元分类任务而言过于复杂。简化模型反而导致了性能的提升。
总结
尽管现代大型语言模型(LLMs)在各种任务上展现出卓越的性能,但它们的规模在实际部署中带来了诸多挑战。
近期模型压缩技术的创新有助于通过降低LLM解决方案的计算成本来缓解这些挑战。本文讨论了三大类压缩技术(量化、剪枝和知识蒸馏),并通过Python实例演示了它们的实际应用。



























