译者 | 朱先忠
审校 | 重楼
简介
检索增强生成(Retrieval Augmented Generation,简称“RAG”)是一种自然语言过程,它涉及将传统检索技术与LLM(大型语言模型)相结合,通过将生成属性与检索提供的上下文相结合来生成更准确和相关的文本。最近,这种技术在聊天机器人开发中得到了广泛的应用,使公司能够通过使用其数据定制的尖端LLM模型来改善与客户的自动化通信。
Langflow(https://github.com/langflow-ai/langflow)是Langchain的图形用户界面,Langchain是LLM的集中式开发环境。早在2022年10月,LangChain就发布了,到2023年6月,它已成为GitHub上使用最多的开源项目之一。可以说,如今LangChain席卷了整个人工智能社区,特别是为创建和定制多个LLM而开发的框架,这些LLM具有与最相关的文本生成和嵌入模型集成、链接LLM调用的可能性、管理提示的能力、配备向量数据库以加速计算的选项,以及将结果顺利交付给外部API和任务流等功能。
在这篇文章中,我们将使用著名的开源泰坦尼克号(Titanic)数据集(https://www.kaggle.com/datasets/vinicius150987/titanic3)展示如何使用Langflow开发一个完整的端到端RAG聊天机器人。
使用Langflow平台开发RAG聊天机器人
首先,需要在Langflow平台(https://astra.datastax.com/langflow/)进行注册。为了开始一个新项目,可以根据用户需求快速定制一些有用的预构建流程。本文中要创建一个RAG聊天机器人程序,最好的选择是使用向量存储(Vector Store)RAG模板。图1显示了这种方案的原始操作流程。
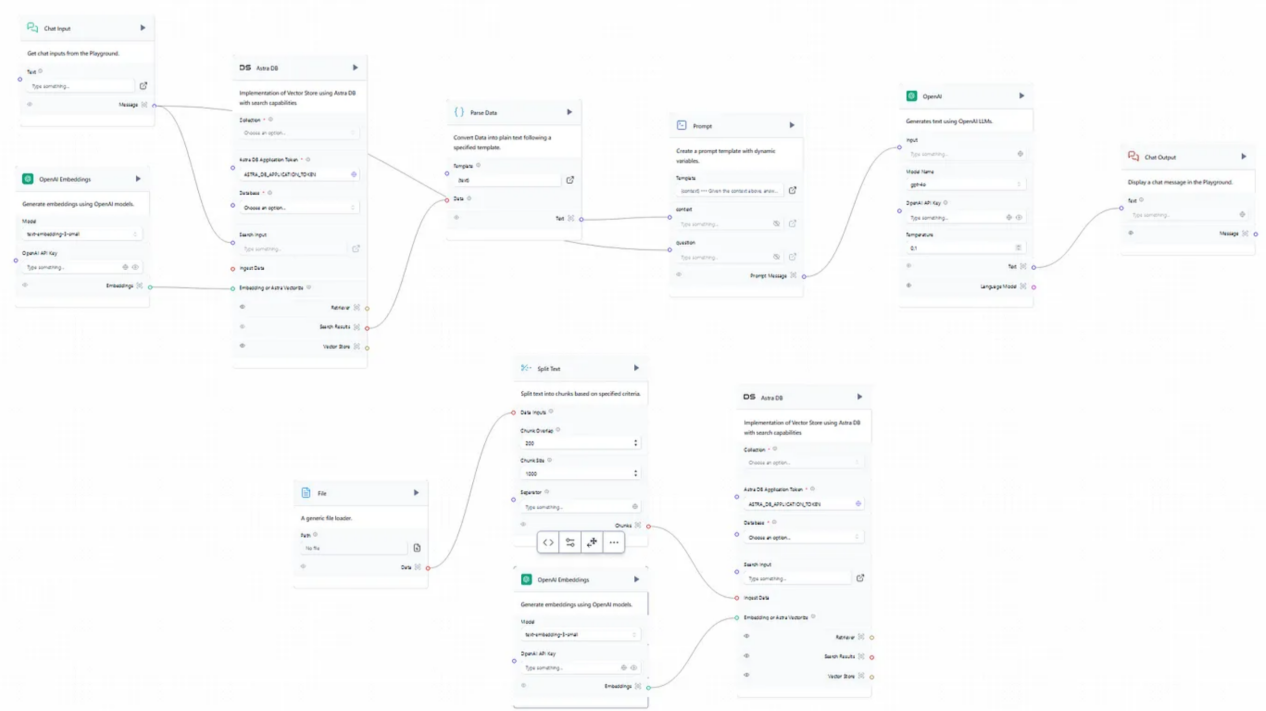
图1:Langflow向量存储RAG模板流
在上述模板中,为嵌入和文本生成预先选择了OpenAI,这些是本文中使用的技术;但是,其他一些选项,如Ollama、NVIDIA和Amazon Bedrock等,也都是可用的,只需设置相关的API密钥即可轻松将其集成。值得注意的是,在使用与LLM提供程序的集成之前,要检查所选的集成是否在配置上处于活动状态,如下图2所示。此外,可以定义全局变量,如API键和模型名称,以便于对流对象进行输入。
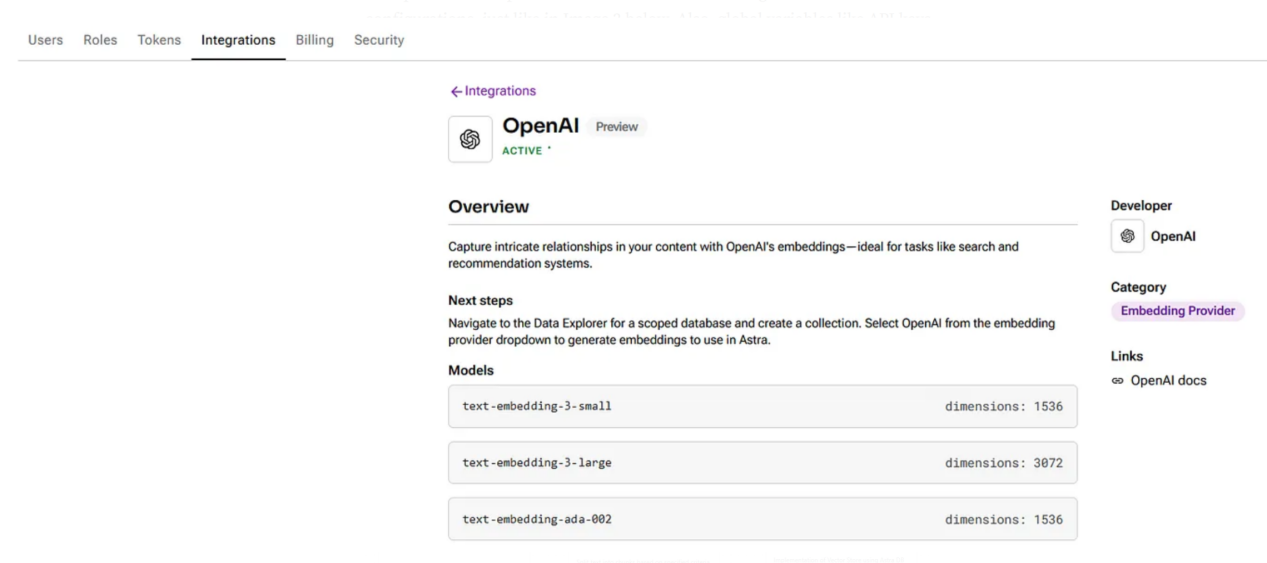
图2:OpenAI集成和概述的界面
向量存储Rag模板上提供了两种不同类型的流。其中,下面的一个显示了Rag的检索部分,其中通过上传文档、拆分、嵌入,然后将其保存到Astra DB(【译者注】。Astra DB是一个基于Apache Cassandra的开源云原生数据库服务,它提供了强大的向量存储能力,非常适合用于构建RAG系统)上的向量数据库中来提供上下文,该数据库可以在流界面上轻松创建。
目前,默认情况下,Astra DB对象能够自动检索Astra DB应用程序令牌,因此甚至不需要收集它。最后,需要创建将嵌入值存储在向量DB中的集合。为了正确存储嵌入结果,集合维度需要与文档中提供的嵌入模型中的维度相匹配。因此,如果你选择的嵌入模型是OpenAI的text-embedding-3-small的话,那么创建的集合维度必须是1536。下图3显示了完整的检索流程。
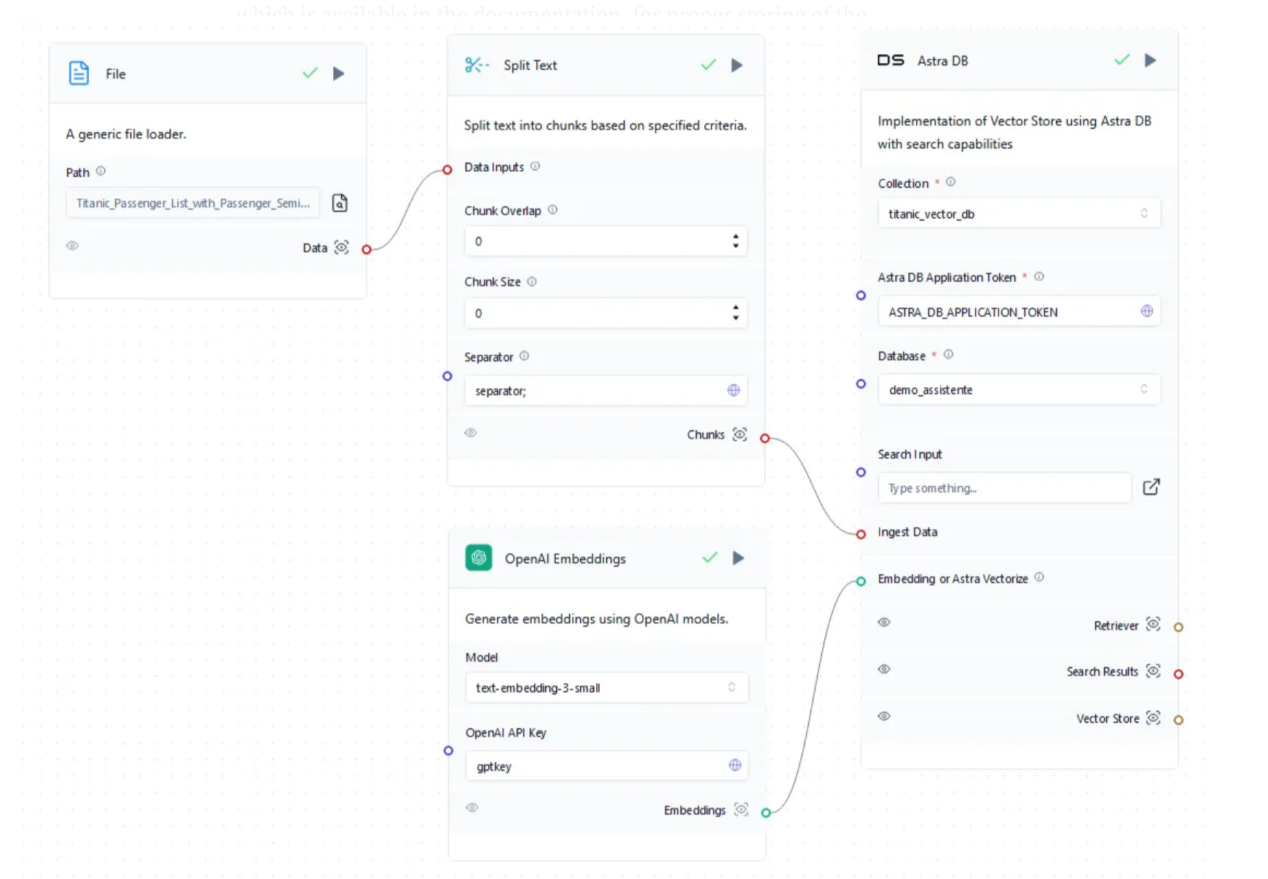
图3:泰坦尼克号数据集的检索流程
用于增强聊天机器人上下文的数据集是Titanic数据集(https://www.kaggle.com/datasets/yasserh/titanic-dataset?resource=download,CC0许可证)。在RAG流程结束时,聊天机器人应该能够提供具体的细节并回答有关乘客的复杂问题。但首先,我们需要在通用文件加载器对象上更新文件,然后使用全局变量“separator;”对其进行拆分,因为原始格式是CSV。此外,块重叠和块大小需要设置为0,因为通过使用分隔符,每个块都将描述为一个乘客对应数据。如果输入文件是纯文本格式,那么,有必要应用块重叠和大小设置来正确创建嵌入。为了完成流程,向量存储在demo_assistente数据库的titanic_vector_db中。
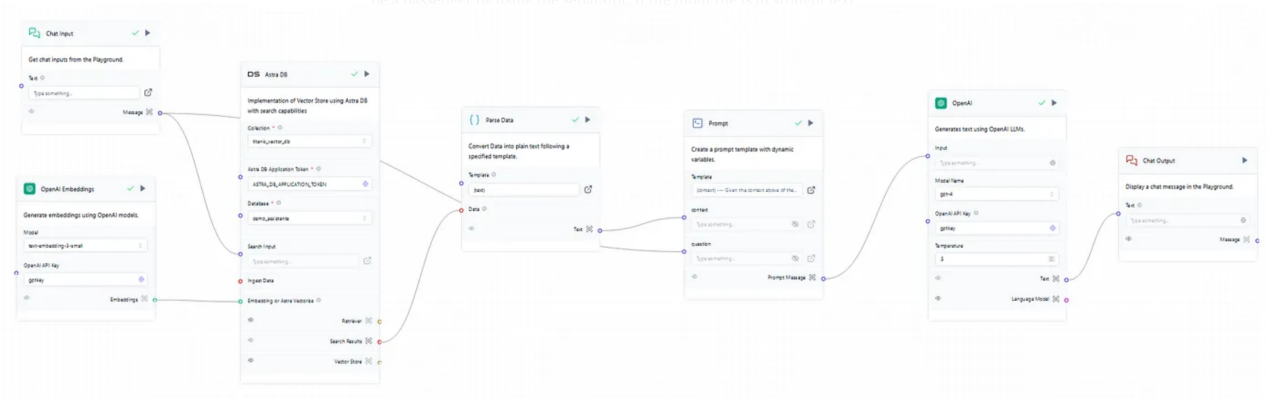
图4:完整的生成流程
接下来,让我们转到RAG的生成流程,如图4所示,它是由聊天中的用户输入触发的,然后搜索到数据库中,为以后的提示提供上下文。因此,如果用户在输入中询问与名称“Owen”相关的内容的话,搜索将在向量数据库的集合中运行,寻找与“Owen“相关的向量,然后检索并通过解析器运行它们以便将其转换为文本,最后获得稍后提示所需的上下文。图5显示了相应的搜索结果。

图5:在向量数据库中进行搜索以获取上下文的结果
回到一开始,使用检索流中的相同模型将嵌入模型再次连接到向量数据库以运行有效搜索也是很关键的一步;否则的话,由于检索和生成流中使用的嵌入模型的不同,会导致检索结果内容总是空的。此外,这一步证明了在RAG中使用向量DB的巨大性能优势,在RAG中将上下文快速检索并传递给提示,然后才能对用户做出任何类型的响应。
在图6所示的提示中,上下文来自已转换为文本的解析器,问题来自原始用户输入。下图显示了如何构建提示,并将上下文与问题结合起来。

图6:将传递给AI模型的提示信息
提示写好后,是时候使用文本生成模型了。在此流程中,我们选择使用GPT4模型,其温度参数(temperature)设置为0.5,这是聊天机器人的标准推荐参数值。温度参数将控制着LLM预测的随机性。一个较低数值的温度参数将产生更确定和直接的答案,从而产生更可预测的文本。相对来说,一个较高数值的温度参数将产生更具创造性的输出——尽管这个参数值太高时,模型很容易产生幻觉并产生不连贯的文本。最后,只需使用全局变量和OpenAI的API键设置API键,这一步就很容易了。接下来,是时候运行完整的流程并在Playground交互环境上检查一下运行结果了。

图7:Playground交互环境显示RAG聊天机器人的运行结果
图7中的对话清楚地表明,聊天机器人能够正确地获取上下文,并正确地回答了有关乘客的详细问题。尽管发现泰坦尼克号上没有罗斯或杰克可能会令人失望,但不幸的是,这是真的。现在,RAG聊天机器人已经创建结束;我们还可以继续增强其功能以提高会话性能并覆盖一些可能的“误解”,但是本文主要展示Langflow框架如何轻松地适应和定制LLM。
小结
最后,我们来介绍一下流部署的问题。当前,存在多种可以供参考的部署方案。HuggingFace Spaces是一种部署RAG聊天机器人的简单方法,它具有可扩展的硬件基础设施和本地Langflow,不需要任何安装。当然,Langflow也可以通过Kubernetes集群、Docker容器安装和使用,也可以通过VM和Google Cloud Shell直接在GCP中安装和使用。有关部署的更多信息,请参阅此框架有关文档(https://docs.langflow.org/deployment-hugging-face-spaces)。
总之,新时代即将到来,低代码解决方案开始为人工智能在不久的将来在现实世界中的发展定下基调。本文介绍了Langflow如何通过直观的UI和模板集中多种集成来彻底改变人工智能。如今,任何具备人工智能基础知识的人都可以构建一个复杂的应用程序——这种程序的开发在本世纪初的话需要大量的编码和深度学习框架专业知识。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Creating a RAG Chatbot with Langflow and Astra DB,作者:Bruno Caraffa