那咱们先来聊聊,为啥之前查询那么慢呢?其实啊,原因也简单,就是因为数据量太大了。你想啊,一个表里有几千万条数据,每次查询还得关联十几个子表,每个子表的数据也是上亿条,这能不慢吗?咱们虽然用了索引、优化了SQL,但效果还是不明显。这就像是你让一个胖子去跑马拉松,他跑得动吗?跑不动啊!
所以啊,咱们就得想办法给这个“胖子”减减肥,这就是查询分离的思路啦。咱们在写数据的时候,顺便把数据发到一个消息队列(MQ)里,然后异步地写到Elasticsearch(ES)里去。这样,查询的时候就不去主表凑热闹了,直接去ES里查,那速度可就快多了。
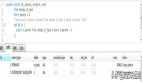
那具体怎么实现呢?咱们来看看代码。假设咱们用的是Java,首先,咱们得在写数据库的时候,把数据也发到MQ里去。这里咱们用RabbitMQ作为例子:
这段代码就是往MQ里发消息的。咱们在写数据库的时候,调用这个send方法,把数据作为消息发出去。
然后,咱们得有个消费者来监听这个MQ,把消息异步地写到ES里去。这里咱们用Elasticsearch的Java客户端来操作ES:
这段代码就是往ES里写数据的。咱们在MQ的消费者里,拿到消息后,调用这个writeToEs方法,把数据写到ES里去。那这样,查询的时候咱们就不去主表查了,直接去ES里查。那速度,嗖嗖的,500毫秒就出结果了。
但是啊,这里有个问题,就是数据还没同步到ES的时候,立马去查,查不到怎么办?这个嘛,咱们也有办法。咱们可以在数据库里加个字段,比如叫es_synced,表示数据是否已经同步到ES了。ES消费者写入ES后可以更新一下这个字段,查询单条数据的时候,咱们先查这个字段,如果已经同步了,就直接去ES里查;如果还没同步,就等一会儿再查,或者从主表里查。
如果是批量查多条数据那就不用做这个处理了,只允许查出来已经同步到ES的数据就可以了!
那历史数据怎么迁移呢?这个其实也不难。咱们可以写个脚本,把主表里的数据分批查出来,然后发到MQ里去,让消费者异步地写到ES里去。这样,历史数据也就迁移到ES里了。
总的来说啊,这个查询分离的思路还是挺实用的。它就像是一个减肥的方法,让咱们的“胖子”数据库跑得快了起来。当然啦,这个方法也不是万能的,比如如果数据量实在太大了,写入速度也会受影响。但是啊,对于大部分场景来说,这个方法还是挺好用的。
好啦,今天咱们就聊到这里啦。如果你也有类似的困扰,不妨试试这个方法~