













作为英伟达GPU技术大会上的绝对明星,今年英伟达为我们带来了 “Blackwell”数据中心GPU硬件,即将在2025年新平台中担当基石角色的“Grace”CPU、NVLink Switch 5芯片、Bluefield-3 DPU以及更多其他组件。而在本周的Hot Chips 2024大会上,英伟达再次对新一波硬件组合做出了详尽介绍。
很多朋友可能还不熟悉英伟达的NIM策略,即强调帮助开发人员更轻松、更快捷地创建AI应用程序。虽然会上也有讨论英伟达推理微服务的声音,但面对Blackwell这样的重量级新成果,没有任何其他议题能够真正夺走它的风头。
但也必须承认,NIM策略对于英伟达通过聊天机器人等生成式AI工具帮助用户开发AI软件的整体计划有着至关重要的作用。英伟达方面表示,NIM提供了软件工程师所需要的一切,其被安置在类似容器的环境当中,并以预构建的微服务形式交付,可被部署在云端、数据中心乃至工作站等系统之上。在Kubernetes之上构建的NIM容器将囊括开源大语言模型、云原生技术栈、英伟达TensorRT及TensorRT-LLM、其Triton推理服务器与标准API等等,将成为英伟达AI
Enterprise整体战略中的关键组成部分。

根据英伟达企业AI软件产品副总裁Justin Boitano所言,NIM是所谓第二波生成式AI技术蓝图的一部分。这股新趋势将发生在企业当中,使得企业能够利用自有知识来经营业务、与客户交互并加快创新节奏。此前的第一波浪潮,是由OpenAI于2022年11月下旬推出ChatGPT之后激发的市场热情所推动、并由基础模型开发者引领,主要探索如何将生成式AI融入互联网服务,从而通过撰写语言和代码来提高个人生产力水平。
Boitano在本周于加利福尼亚州召开的Hot Chips展会的会前简报中向记者和分析师们强调,在这新一波浪潮当中,“生成式AI技术将帮助团队推理复杂的业务流程与供应链依赖关系,以前所未有的速度将新产品和服务推向市场。这波浪潮的开端实际上源自Meta Platforms的Llama 3.1等开放模型的发布。这些模型代表着惊人的AI技术进步,将企业的智能化水平提升到了新的层面,而几年之前大多数人还无法想象能够将这些模型运行在数据中心之内。”
他同时提到,NIM的建立是为了实现对这些模型的大规模、生产级安全运行,并补充称英伟达目前正在与一系列AI模型构建组织合作,利用NIM使其模型在性能与运行时效率方面更上一层楼。
Boitano介绍称,“这些NIM提供了性能优化,使得token吞吐效率比其他解决方案快2到5倍。因此企业在英伟达系统上运行生成式AI时,可获得更好的总体拥有成本。另外通过与社区模型构建者、专有模型构建商以及我们自己的模型所共同构成的生态系统合作,英伟达能够确保任何业务下的任何模式间均可无缝协作,从而为使用英伟达AI Enterprise的客户提供最佳token处理效率。”
在Hot Chips上,英伟达正通过NIM迈出新的一步,为想要创建自定义生成式AI应用程序的开发者们提供NIM Agent Blueprints。这一方案参考的是AI工作流,包括基于NIM及合作伙伴微服务的示例应用程序、参考代码、一份概述自定义机制与Helm图表(用于具体解释并打包Kubernetes集群资源的应用程序文件)以实现应用程序部署。开发人员还可以对此蓝图做出灵活修改。
Boitano解释道,“这是一份不断增长的参考应用目录,专为各类常见用例而创建,其中整合了英伟达与早期采用者在合作当中总结出的最佳实践。英伟达NIM Blueprints是一种可运行的AI工作流,针对特定用例进行了预训练,而且任何开发人员都可灵活修改。这些蓝图将成为企业中各类最核心业务任务的执行起点。”
除了加快模型部署之外,NIM Blueprints还属于英伟达规划的“数据飞轮”项目的一部分。这些蓝图能够增强模型功能并实现模型定制,从而满足组织中特定用例的实践需求。Boitano表示在飞轮理念之下,当AI应用程序运行并与用户产生交互时,它们就会生成数据、将数据反馈至流程当中,最终用于在持续学习周期内改进模型性能。
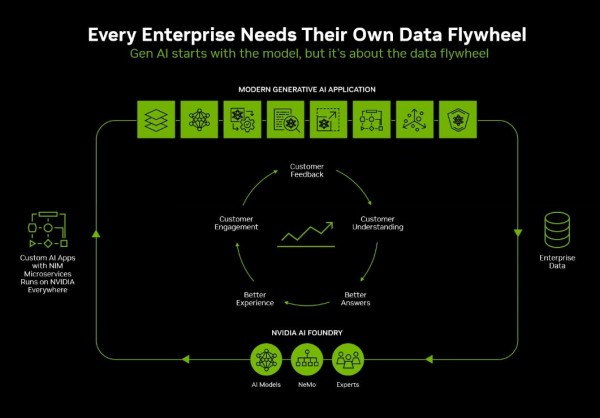
Boitano指出,“英伟达NeMo正是运行这套飞轮的引擎,英伟达AI Foundry则是运行NeMo飞轮的工厂。这些定制化生成式AI应用程序将帮助企业以更卓越、质量更高的体验吸引客户和员工。”
他同时补充称,“应用程序的构建过程实际上是从NIM开始的。但为了构建数据飞轮,英伟达NeMo框架会介入其间以支持数据管理、模型定制和性能评估,并用于增强应用程序以使其更好地融入生产流程。NeMo加快了生成式AI应用程序整个开发生命周期当中的一切计算密集型阶段。我们还拥有广泛的合作伙伴生态系统,他们以NeMo和NIM为基础,使得企业能够轻松开发出自己的生成式AI应用程序。”

自从最初的生成式AI热潮以来,各类组织一直在讨论如何将业务数据纳入训练和推理组合,借此定制属于自己的一套AI运作体系。而这方面需求最终催生出的成果,就是检索增强生成(RAG)。
英伟达最初发布了三种场景的蓝图,分别是用于客户体验的数字人(即创建能够与用户交互的3D数字人)以实现多渠道交互并接入RAG系统。其二是用于企业RAG的多模态PDF数据提取。“企业每年都会生成数万亿份PDF,这些PDF文件中包含多种数据类型,包括文本、图像、图表和表格。多模态PDF数据提取蓝图能够帮助组织准确从海量业务数据中提取出所包含的知识,使得用户通过聊天界面高效访问这些数据,亦可快速将数字人转化为任意主题方面的专家,帮助员工做出更明智、更迅捷的决策。”
最后一类应用,则是加快药物发现,即使用生成式AI模拟具备靶向性与可结合性的蛋白质分子。

英伟达还携手埃森哲、德勤、SoftServe、Quantiphi以及World Wide Technology共同参与开发NIM Agent Blueprints,同时力邀Dataiku和DataRobot参与模型的微调和监控,协同LlamaIndex和Langchain建立工作流,配合Weights & Biases公司开展应用程序评估,并与CrowdStrike、Datadog、Fiddler AI、New Relic和Trend Micro一道探索网络安全之道。此外,Nutanix、红帽和博通的企业级产品组合也将支持英伟达交付的蓝图。
这些蓝图还将运行在思科、戴尔科技、HPE以及联想等OEM厂商的系统,以及亚马逊云科技、Google Cloud微软Azure以及甲骨文云基础设施等超大规模系统之上。


















