在介绍字典的底层结构时我们看到,当已使用的 entry 数量达到总容量的 2/3 时,会发生扩容。
而在早期,哈希表只使用一个键值对数组,这个键值对数组不仅要存储具体的 entry,还要承载哈希索引数组的功能。本来这个方式很简单,但是内存浪费严重,于是后面 Python 官方就将一个数组拆成两个数组来实现。
不是说只能用 2/3 吗?那就只给键值对数组申请 2/3 容量的空间,并且只负责存储键值对。至于索引,则由哈希索引数组来体现。通过将 key 映射成索引,找到指定的哈希槽,再根据槽里面存储的索引,找到键值对数组中存储的 entry。
因此减少内存开销的核心就在于,避免键值对数组的浪费。
所以哈希索引数组的长度就可以看成是哈希表的容量,而键值对数组的长度本身就是哈希索引数组的 2/3、或者说容量的 2/3。那么很明显,当键值对数组满了,就说明当前的哈希表要扩容了。
扩容之后的新哈希表的容量要大于等于 ma_used * 3,注意:是大于等于 ma_used * 3,不是 dk_nentries * 3。因为 dk_nentries 还包含了被删除的 entry,但哈希表在扩容的时候会将其丢弃,所以扩容之后新哈希表的容量取决于 ma_used。
当然啦,哈希表的容量还要等于 2 的幂次方,所以有两个条件:
- 大于等于 ma_used * 3;
- 等于 2 的幂次方;
基于以上两个限制条件,取到的最小值便是扩容之后的容量。为此 Python 底层专门提供了一个 calculate_log2_keysize 函数,看一下它的逻辑。
只不过返回的不是扩容之后的字典的容量,而是以 2 为底、容量的对数。
然后我们来看看扩容对应的具体逻辑。
所以核心在于 dictresize 函数,但这个函数比较长,在看它的内部实现之前,先来回顾一下基础知识。
 图片
图片
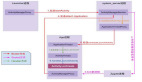
以上是字典的底层结构,假设变量 mp 指向了 PyDictObject 实例,那么可以得到如下信息。
- mp->ma_keys->dk_indices 便是哈希索引数组,它的长度便是哈希表的容量。
- mp->ma_keys->dk_entries 便是键值对数组,里面的一个 entry 就是一个键值对。
- 如果字典使用的是结合表,那么 entry 的 me_key、me_value 字段负责存储键和值,此时 mp->ma_values 为 NULL。
- 如果字典使用的是分离表,那么 entry 的 me_key 字段负责存储键,me_value 字段则始终为 NULL,此时由 mp->ma_values 负责存储值,这种做法可以让多个字典共享一组 key,从而节省内存。
因为分离表是 Python 针对实例对象的属性字典单独设计的,我们平时创建的都是结合表,所以一开始并没有讨论分离表。但分离表其实非常简单,这里来补充一下吧,我们看一下 ma_values 是怎么定义的。
结构非常简单,就是维护了一个数组,保存所有的 value。另外我们发现字段 values 是一个数组,而不是指向数组首元素的二级指针,这就说明使用分离表的字典的容量是固定的,如果要扩容,那么结构会发生改变,分离表会重构为结合表。
现在假设有一个字典,里面有三个键值对 "a": 1, "b": 2, "c": 3,我们看一下分别使用结合表和分离表存储时,字典的结构是什么样子。
结合表:
 图片
图片
分离表:
 图片
图片
所以结合表是键和值存在一起,分离表是键和值分开存储,非常好理解。我们自己创建的字典,使用的都是结合表,分离表是为了减少对象属性字典的内存使用而专门引入的。
然后是字典(哈希表)的三种形式:
- Unicode split table:分离表,key 全部是字符串。
- Unicode combined table:结合表,key 全部是字符串。
- Generic combined table:结合表,key 的类型没有限制。
所以对于一个分离表而言,它的 key 一定都是字符串,否则不可能是分离表。而如果 key 都是字符串,那么既可以是分离表,也可以是结合表。
但如果不满足 key 都是字符串,或者说 key 没有类型限制,那么一定是结合表。所以 Generic combined table 里面的 combined 可以省略,因为当 key 的类型是 Generic 时,哈希表一定是 combined。
接着是转换关系:
- split 可以转成 combined,但反过来不行。
- unicode 可以转成 generic,但反过来不行。
好,最后我们看一下 dictresize 函数。
因为要对哈希表的种类分情况讨论,所以导致代码有点长,但逻辑不难理解:
- 首先确定哈希表的容量,它要满足 2 的幂次方,并且大于等于 ma_used * 3。
- 为 ma_keys 重新申请内存。
- 根据哈希表的种类分情况讨论,但核心都是将老的没有被删除的 entry 搬过去。
- 释放 ma_keys,如果字典之前是分离表,还要释放 ma_values。
以上就是哈希表的扩容,或者说字典的扩容,我们就介绍到这儿,下一篇文章来介绍字典的缓存池。