随着多代理系统的出现,强化学习的复杂性不断增加。为了管理这种复杂性,像 TorchRL 这样的专门工具提供了一个强大的框架,可以开发和实验多代理强化学习(MARL)算法。本文将深入探讨如何使用 TorchRL 解决 MARL 问题,重点关注多代理环境中的近端策略优化(PPO)。
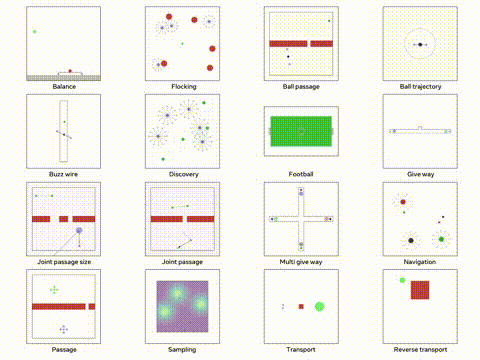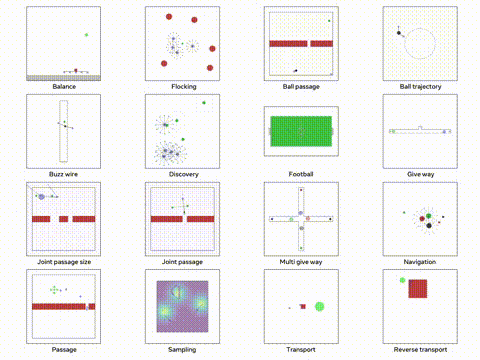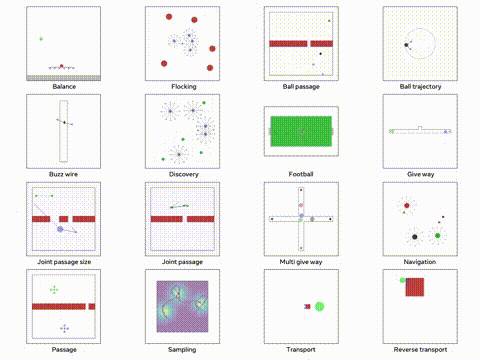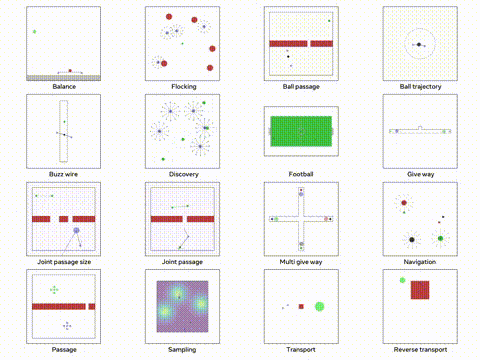
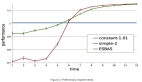
我们将使用 VMAS 模拟器,这是一个多机器人模拟器并且可以在 GPU 上进行并行训练。他的主要目标多个机器人必须导航到各自的目标,同时避免碰撞。
依赖
在开始之前,请确保安装以下依赖项:
理解近端策略优化 (PPO)
PPO 是一种策略梯度算法,它迭代地从环境中采样数据,并直接使用这些数据来优化策略。这个过程包括采样和训练两个阶段,数据在收集后立即进行训练更新。这种在线方法确保策略根据与环境最近的交互持续改进。

在线学习
在 PPO 中,学习过程依赖于一个评论家(critic),它评估策略所采取行动的质量。评论家估计给定状态的价值,通过比较预期回报与实际结果来指导策略优化。
在多代理设置中,我们部署多个策略,每个代理一个,通常以分散的方式运作。每个代理的策略仅根据其局部观察来决定其行动。但是评论家可以是集中的或分散的:
- MAPPO : 评论家是集中的,以全局观察或连接的代理观察作为输入。这种方法在可获得全局状态信息的集中式训练场景中有益。
- IPPO : 评论家是分散的,仅依赖于局部观察。这种设置支持分散式训练,代理只需要局部信息。
集中式评论家有助于缓解多个代理同时学习时出现的非平稳性问题,但可能因输入的高维度性而面临挑战。
TorchRL
TorchRL是一个基于PyTorch的强化学习(Reinforcement Learning, RL)库,专为研究人员和开发者设计,旨在提供一个灵活、高效的框架来实现和实验各种RL算法。
- 与PyTorch深度集成:TorchRL充分利用了PyTorch的生态系统,使用户能够无缝地将RL算法与深度学习模型结合。
- 模块化设计:库提供了可组合的组件,允许用户轻松构建和定制RL算法。
- 高性能:TorchRL注重效率,支持GPU加速和并行化,以加快训练和推理速度。
- 多环境支持:兼容多种RL环境,包括OpenAI Gym、DeepMind Control Suite等。
- 丰富的算法实现:内置多种流行的RL算法,如DQN、PPO、SAC等。
- 扩展性:易于扩展和添加新的算法、环境和功能。
下面代码我们将使用TorchRL来完成我们的目标
1、设置超参数
我们从定义 MARL 设置的超参数开始。这些参数控制模拟和训练过程的各个方面,如设备类型、批量大小、学习率和 PPO 特定设置。
2、创建环境
TorchRL 与 VMAS 的集成允许我们高效地创建和管理多代理环境。在我们环境中多个代理必须在 LIDAR 传感器的引导下导航到各自的目标,同时避免碰撞。
3、策略设计
策略网络在 PPO 中至关重要,它负责根据代理观察生成动作。鉴于环境中的连续动作空间,我们将使用 Tanh-Normal 分布来模拟动作,这样还可以决定是否在代理之间共享参数,在计算效率和行为多样性之间权衡。
4、评论家网络设计
评论家网络评估状态值,指导策略更新。可以根据使用 MAPPO 还是 IPPO 来选择集中式或分散式评论家。在代理之间共享参数可以加速训练,但是可能导致同质化策略。
5、数据收集
TorchRL 中的数据收集通过设计用于自动处理环境重置、动作计算和环境步进的类得到简化。所以我们可以直接使用 SyncDataCollector 来收集训练数据。
6、训练循环
训练循环将环境、策略、评论家和数据收集器结合在一起,通过采样和训练阶段的迭代来优化代理的性能。
这样我们完整的代码就完成了,可以看到通过TorchRL,可以减少我们很多的代码开发工作。
总结
本文提供了使用 TorchRL 和 PPO 实现 MARL 解决方案的全面指南。通过这些步骤,可以在多代理环境中训练代理以导航复杂任务,同时利用 GPU 加速模拟和并行计算的力量。无论选择集中式还是分散式评论家,TorchRL 都提供了设计和实验不同 MARL 架构,可以帮助你解决多代理强化学习的复杂性。