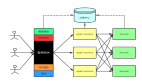
这个问题是我在知乎上看到的,答案并不是一边倒,还是存在争议性的。
其中,一些持反方观点同学的理由如下:
(1)从硬件成本和维护成本上看,反而应该多个微服务尽可能地共用中间件和数据库。
(2)微服务的独立数据库是指逻辑独立,而不是物理独立,在物理层面上是可以共用数据库的。
btw:有点儿像《非诚勿扰》中葛优对舒淇说的话:“那你能允许我心在你这,身体上开点儿小差吗”?
(3)你把数据库也看做一个微服务就好理解了,微服务之间本身就是多对多的关系,公用有何不可呢?
抛出我的观点吧,我完全支持每个微服务都要有自己独立的数据库,但每个数据库是否使用独立的服务器,这个需要视业务情况而定。
具体原因请见下图:
 图片
图片
系统可用性
说说我当年的情况吧,当时我在一个在线教育公司,该公司早期的系统是一个单体架构,一个大的后端工程,并对应一个大的数据库。
后来人越招越多,业务也越来越复杂,几十人的研发团队共同在一个大的单体服务中进行开发,这是明显不现实的。
于是,研发团队便按照组织结构进行服务拆分,将那个大的单体服务拆分为学生端服务、教师端服务、管理端服务和销售端服务。
 图片
图片
随后,我们的学生端服务又按照业务领域,拆分出来了学生课表、积分商城和学生运营活动服务。
其中,学生课表服务的重要等级是P0(最重要的),因为学生是以课表为入口进入教室上课的,也就是说,如果课表服务挂了就会导致无法上课,会给公司带来重大经济损失。
积分商城服务,是学生通过积分兑换学习用品的,如果服务挂了会影响用户体验,但不会造成经济损失,因此重要等级为P1。
而运营活动服务的主要功能为,公司的运营人员会创建一些活动来增加学生在平台上的活跃度,比如:学生将自己创作的作品,发到朋友圈中收集点赞,被点赞最多的学生获得小礼品,等等。
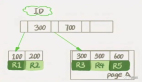
但当时的情况是,学生课表、积分商城和学生运营活动这三个服务拆出来了,还是共用了一个学生端的数据库。
有一天晚上,正好是学生上课的高峰期,忽然收到一通报警,学生端数据库的负载竟然达到了200多,CPU使用率也被干到了100%。
紧接着,公司的大群中就有好几个业务同事发消息说,学生投诉说课表看不到了,不能进入教室上课了。
我们听了之后,赶紧登录监控系统去查看学生课表服务的相关接口,发现由于不显示课表学生反复刷新页面的原因,接口的QPS确实比正常情况下高了好几倍,但都被Sentinel限流掉了,不应该造成影响才对。
正在一筹莫展之际,我忽然发现在监控系统上,学生运营活动服务的接口QPS和TPS同样高得离谱,比平时高十几倍,且彪高的起始时间要比学生课表接口早一两分钟。
这就证明了,很大可能是学生运营活动服务的流量彪高,且学生运营活动服务上的接口没有做限流保护,造成了服务共用的学生端数据库扛不住了,从而影响了学生课表服务。
 图片
图片
于是,我们赶紧启动降级机制,关闭了所有的学生运营活动服务的接口。没过一会儿,学生课表可以正常访问了。
接下来,我们和DBA连夜把学生课表服务所对应的数据表单独拆分出来,迁移到一个新的数据库服务器上进行独享。
嗯,重要等级高的微服务不但要有自己独立的数据库,且必须是独立的数据库服务器,通过链路隔离的方式提升系统可用性。
当然,一些重要等级不高的服务独立数据库即可,并不需要独立数据库服务器,这样可以节省硬件成本。
架构贯彻性
我们都知道,微服务架构之间是通过RPC调用来进行业务串联的。
以常见的电商场景举例,需要给用户展示他所购买的订单列表,此时订单中心会调用商品中心的API获取商品数据,然后再跟订单数据进行merge,返回给前端用户。
如果此时商品中心和订单中心所对应的数据表放在一个数据库中,可以预见的情况就是,研发人员会把订单表和商品表进行多表关联的方式来代替RPC调用+ 数据merge,因为这样做非常省事。
如下图所示:

而一旦破了这个口子,就会形成“破窗效应”,系统架构就变成分布式单体架构。
有人说,可以靠口头约束的方式来规避这种情况,我并不认同。
想象一种场景,如果一个同学赶项目工期,半夜12点还在那挑灯夜战呢。此时,如果有一种方式让他快速写完代码回家睡觉,他会毫不动心一丝不苟地“按照规律办事”?
研发效率
微服务独立数据库的另一个好处就是,读写入口收敛,这样是可以提升研发效率的。
举个例子,如果我们把商品表进行垂直拆分,拆分成商品表 + 商品详情表,如果按照标准的独立数据库方式,只需要商品中心来进行对应的代码变更就可以了,这对依赖商品中心的其他服务来讲是透明的。
而非独立库模式就比较蛋疼了,每个去直接查询商品表的服务都需要改一遍。
如下图所示:
 图片
图片
上述例子属于读入口收敛的范畴,而写入口不收敛,在多个服务中对一张数据表进行写入的话,则带来的问题同样不少。
问题包括:
(1)表结构变更问题,如果增加一个非空字段,那么所有写入口的代码全部需要变更,且这种“散弹式”修改非常容易遗漏。
(2)问题排查难,一旦发现写入了问题数据,那各个写入口全部需要进行排查,工作量大且复杂。
除了读写入口收敛问题,再有就是,如果形成了上文中所说的“分布式单体架构”,那接下来再想进行优化改善的话,将会是一件工作量极大的事情,所以不如一次做好。
结语
综上所述,我认为如果选择了微服务架构,那每个微服务独立数据库完全是个必选项,独立数据库服务器则是个可选项,需要兼顾可用性和硬件成本。