一、EasyRec 训练推理架构

在介绍 EasyRec 的训练推理架构之前,先来谈谈推荐模型的发展趋势和面临的挑战。近年来,推荐模型的发展呈现出以下一些趋势:首先,特征数量越来越多,从几百个增加到上千个,还有许多交叉特征;同时,Embedding 变得越来越大,序列越来越长,Dense 层也越来越复杂,从简单的 MLP 发展为 MMOE、MaskNet、PLE 等复杂结构。由此带来的最大挑战就是算力不足,另外训练推理成本很高,推理超时严重。

EasyRec 推荐算法训练整体框架主要包括:数据层、Embedding 层、Dense 层和输出层。这个架构可以在多种平台上运行,包括 MaxComput、开源大数据平台 EMR 和深度学习的容器平台 DLC。
此架构的优势是支持配置化、组件化,包括深度支持 Keras 组件,能自定义组件,并通过配置接入各种模型。它还支持大规模分布式训练、ODL,以及基于 NNI 的自动调参,搜索最优超参数,和自动特征选择。支持推荐模型中的常用功能,如 MultiOptimizer,设定 Embedding 和 DNN 层不同学习率和优化器,以及特征热启动,大规模负采样等。如果模型训练中断,可以使用 Work Queue 从断点恢复训练,显著提升了大型任务的训练成功率。此外,在 TF 框架上扩展了分布式 Evaluator,支持大数据量的模型评估。

接下来介绍推理框架 PAI-REC 引擎,这是整个推荐链路的一个重要部分。PAI-REC 引擎串联推荐业务的各个阶段,常见的阶段包括召回、排序、重排和打散。PAI-Rec 引擎基于 go 语言编写,具有比较高的效率,同时也是模块化的,因此具有比较强的扩展性,进一步还提供了用户友好的界面,方便用户配置 ab 实验,做特征一致性诊断,分析特征和实验效果等关键功能。
与 EasyRec 相关的是 EasyRecProcessor,负责精排和召回模型的在线推理。主要包括三个部分:item 的 Feature Cache,Feature Generator 和 TF Model。EasyRecProcessor 进行了大量的 CPU 和 GPU 推理优化,如通过 item 特征缓存减少 item 静态特征带来的网络传输压力,通过增量更新加快模型传输和部署的速度,在 Feature Generator 和 TF Model 模型推理上也有很多优化,下面进行详细介绍。

EasyProcessor 支持在 PAI-EAS 平台上一键部署。该框架已经在阿里云上得到了广泛应用,已服务数百家客户,覆盖电商、直播、文章分享、视频分享、广告和社区等多种业务。同时,在阿里内部也有很多客户在使用该框架。

我们曾服务过一个电商导购案例,通过优化,不仅提升了效果,还显著降低了成本,我们针对推荐的各个链路都进行了升级和优化。
二、EasyRec 训练优化

接下来讲一下 EasyRec 在训练方面的优化。随着 sequence 长度的增加,算力、存储和网络开销显著增大。我们发现一次曝光会下发很多 item,而这些 item 的 SequenceFeature 大多相同。通过去重操作,例如一个 8192 的 batch_size,去重后可能只剩下原来的 5% 到 10%。因此,对 SequenceFeature 进行去重,只存 request_id,再通过 iGraph 查找 SequenceFeature,经过 embedding layer 和 deunique 处理,得到 batch seq_embedding。这个优化提升了系统吞吐量 20%。考虑到可迁移性,我们目前的 unique 实现基于 Python,若改用 C++,性能将进一步提升。

另一个优化是 EmbeddingParallel,即 embedding 分片优化。以往多采用 PS-Worker 模式,尽管扩展性好,但存在问题,如 ps 通信量大,算力不足,以及 embedding 划分不均匀影响训练效率。算子 placement 不当,如 unique 算子被错误地放在 ps 上,也会造成瓶颈。All-Reduce 模式是另一种选择,所有 Worker 存储相同参数,避免了 ps 的通信和计算瓶颈。但这种架构的问题是 embedding 容量受单机内存限制,难以实现多机扩展。

EmbeddingParallel 优化中,每个 Worker 独立存储 dense 参数,但 Sparse 参数分片存储在每个 Worker 上,避免了 All-Reduce 模式的内存瓶颈。dense 参数通过 All-Reduce 更新,小型和桶化的 embedding 也是如此,大型 embedding 则通过 AllToAll 更新。
在 CPU上,我们采用 DeepRec 的 lock-free hash table,比 google 的 dense hash table 效率更高。在 GPU 上,采用 hugectr 的 sok embedding,通过 GPU 缓存的方式加载热点 embedding,减少 embedding h2d 的开销。在训练效果上,MMOE 和 PPNet 模型的对比显示,PS 模式下每秒约 3.5 步,而 EmbeddingParallel 架构显著提升了训练速度。由于参数保存在不同 Worker 上,需额外工作聚合 embedding,导出单机可 serving 的模型。EasyRec 框架已实现这一功能,直接可用。

我们在 CPU 上的另一个训练优化,针对仍使用 CPU 架构进行训练和推理的客户。推荐模型的 Dense 层越来越复杂,导致计算量大增。分析模型时间线发现,MatMul 占据 60% 以上的计算时间。为提升 MatMul 这类算力密集型算子的性能,我们与英特尔合作,利用 AMX 计算能力,进行矩阵 BF16 加速,其算力比普通 CPU 高约 16 倍。在实际模型训练中,采用 AMX 功能优化,显著提升了训练速度。
三、EasyRec 推理优化

接下来介绍一下 EasyRec 推理方面的优化。首先是 Embedding 部分的优化,大部分 Embedding 仍然放在 CPU 上。如果用 TF 的 feature column 构造 embedding layer,会发现存在很多小的算子,如 unique 和 SparseSegmentMean,这些小算子带来大量启动开销,影响整体性能.
针对常用的 Embedding 模式,做了一些融合算子优化,并通过 AVX 进行并行加速。比如一个 sequence 算子,可能包含几百个小算子,优化后变成一个算子,计算开销降低且通过 AVX 加速,性能大幅提升。实际应用中,算子数量减少 50% 以上,响应时间(RT)也减少一半以上。

我们发现半精度计算可以加速推理并减少内存占用,尤其对大模型的内存开销影响显著。实验表明,大部分模型将模型量化为 BF16 对 AUC 基本没有影响。在 BF16 到 float 的转换中,原生 TensorFlow 的转换速度较慢,我们尝试用 AVX 进行加速,结果显示 QPS 和 RT 显著提升。基于此,我们进一步尝试了 AMX 的矩阵乘法加速,能够进一步提升约 10% 以上。

接下来介绍一下我们在 Feature 层的优化。很多算子用 string 表示,如 look up feature 会解析 string 并构建 map,带来开销。我们用 AVX 优化了 StringSplit。在构建 HashMap 时,默认使用 MurmurHash,虽然冲突概率小,但特征解析时,HashMap 规模不大且用时短。采用更高效的 CrcHash 和 XorHash,均用 AVX 实现,替换 MurmurHash 后,RT 降低 5% 以上。
另外是 SequenceFeature 优化,使用 item feature cache,减少了远程网络访问开销,提高了 sequence 在推理侧的性能,但是带来了一个新问题:内存占用较大。我们设计了一种紧凑的存储格式,内存开销相比普通的存储方式降低了 80% 以上。进一步我们将 Feature 处理算子封装为 TensorFlow op,支持并行执行,复用 TensorFlow 线程池,实现 feature generation 和 embedding look up 的 overlap 执行,并减少减少数据序列化和网络传输的开销。整体优化后,RT 减少 20%,QPS 显著增加。

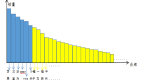
这是实际采集的 timeline,显示优化前的情况,其中很多时间花在 match feature,字符串解析、拼接和 tensor 填充上,开销较大。优化后,这些额外的解析和拼接操作都消除了,主要只剩下 match feature 本身的开销。

接下来讲常用的 user feature tile 优化。许多 user feature 和 sequence feature 在一次请求中只需计算一次,但导出模型时,算法同学未考虑这个情况。因此,我们在 processor 侧进行 tile 优化(自动 broadcast)。在输入层补齐 user feature 并做 tile 的效率有限。
进一步提升是在 embedding look up 后进行自动 broadcast,节省计算开销。实际测试中,QPS 显著提升 30% 到 50%。整个优化流程是找到需要 broadcast 的算子,很多算子可自动 broadcast,但 select 和 concat 等特殊算子需要对输入进行 broadcast 处理以确保正确执行。找到这些候选算子后进行 top 排序,再对排序后的算子逐一 Tile。Tile 过程中,部分算子 Tile 后使其他算子无需再 Tile,因此只需选择未 Tile 的算子继续 Tile,实现自动 broadcast。我们通过分析全图来将 tile 尽可能后置,以最大化的降低计算量。

接下来讲 GPU 上的优化,GPU 优化最重要的是 Placement 优化。GPU 的算力强吞吐高,但启动开销高。通常我们会把 embedding 放在 CPU 上,因为 OP 数目多且单个 OP 计算量小,放在 GPU 开销大于执行时间。这样用 GPU 反而不如 CPU 效率,加上 CPU 侧有很多 AVX 优化,要 GPU 超过 AVX 的效率就更难了。
GPU 主要负责 Dense 计算。Dense 计算量大,OP 执行时间超过 kernel launch 开销,所以用 GPU 性能提升显著。除 kernel launch 外,还要考虑数据拷贝,embedding 到 Dense 的拷贝次数和数据量对性能影响大。我们用 Min-Cut 方法在图中找到最优分割点,将 Embedding Lookup 部分放在 GPU 上,后续 Dense 计算前面在 CPU,后面在 GPU,减少 H2D Memcpy 开销。

即使进行了 placement 优化,但发现仍有一些模型的 GPU 利用率很高,达到百分之八九十,但整体吞吐仍然不理想。主要原因在于 GPU 的算子,比如 MatMul 和许多 elementwise 算子(如 batch_norm、sigmoid、softmax),在 CPU 上计算效率较高。这些算子属于访存密集型算子,访存和调度开销较大,不能充分发挥 GPU 的计算能力。因此,我们考虑使用 XLA 进行算子融合,减少 kernel launch 开销,提升系统吞吐。
XLA 主要是 TF to XLA,包含以下流程:自动圈图(AutoCluster),将目标算子圈出,生成 function library;然后 TF2XLA Compiler 优化,转为 HLO 的 XLA 表示;最后通过 LLVM 编译优化到 Cuda。
我们遇到的问题主要是 Dynamic shape,采用的方法是对 XlaRun 的 OP 进行 Padding,执行后再剪切出有效的部分,以减少编译优化导致的动态重编译问题。优化后效果显著。优化前 RT 高,QPS 不高;优化后 RT 显著下降,QPS 提升。即使在一些 GPU 利用率不高的场景下,XLA 融合后 RT 也明显下降。

刚刚讲了 XLA 存在动态形状的问题,随后我们尝试了 TRT(dense layer optimization)优化。TRT 的流程类似,先拆分部分 OP 进行 cast 圈图,再转成 TRT 表示,最后用 TRTEngineOp 执行。TRT 对 BatchNorm、Add、ReLU 等 elementwise 算子进行了深入融合。一个优势是对 dynamic shape 有支持,可以指定 range,在一定范围内避免重编译。另一个优势是 TRT 支持量化,如 BF16 转换。
我们在算力密集的 Dense 层进行了实验,QPS 提升明显。TRT 的缺点是作为闭源系统,问题排查较困难。所以我们结合 XLA 和 TRT 进行模型优化。
关于 dynamic shape,更加优雅的解决方案是 blade-disc,现有的使用方式是离线将模型转成 ONNX 后,用 blade-disc 优化并加载。实时优化尚未实现,未来我们会逐步在 EasyRec Processor 中引入 blade-disc compiler 的 dynamic shape 功能。

在广告场景中,实际的 batch size 较小,即使进行了 XLA 优化,吞吐量仍然不理想。单个 Batching 执行时,kernel launch 的开销仍然较大。
我们进行了 batch 优化,将多个小 batch 组装在一起,由 GPU 执行。embedding lookup 之前,每个 batch 仍单独在 cpu 上执行,lookup 之后组装成一个大 batch 提交到 gpu 上执行。Batch 模式的一个差异是在 feature tile 层需要进行更多的 broadcast 操作。像 Add、Sum、Mul 这些 OP 在 batch 处理后无法自动 broadcast,因此在 feature tile 层对这些 OP 进行处理,使其在多个小 batch 上也能自动 broadcast。broadcast 完成后,再 concat 并交由 GPU 执行大的 batch。
在广告场景中,这种优化显著提升了 QPS,尤其在 CVR 和 CTR 方面效果明显。

接下来介绍我们在网络直连和请求压缩方面的优化经验。之前在 PAI-EAS 上部署 EasyRec 推理服务时,通过 Client 请求 Nginx 网关负载均衡,会增加一次网络转发。改用直连方式后,客户端定期刷新 pod 的 IP,减少一次网络转发,RT 降低约 5 毫秒。
另一个问题是在客户和我们机房之间做专线连接时,请求流量较大,高 QPS 场景下流量可能达到几十 Gbps,给专线带来压力。我们考虑请求压缩,尝试了 gzip、snappy 和 zstd 等方式,最终选择 snappy 和 zstd,既对 RT 影响小,又显著降低流量压力,10Gbps 流量大约减少了五倍,大大减轻了专线压力。
四、实时学习 Online Learning

接下来介绍我们在 online learning 上的工作。Online learning 现在应用非常广泛,尤其在新品上架和热点更新等需要及时响应的场景中。此外,大促活动时样本分布变化快,需要 embedding 参数和 dense 参数快速更新。online learning 的核心步骤包括:流失样本、流失训练和增量参数更新。

这是在 EasyRec 中使用 online learning 进行实时更新的主要流程。首先,我们通过 PAI-REC 实时回流日志和特征到 SLS 日志系统,并通过特征埋点回流到 Datahub 中间件。我们在 Flink 上构建了一套完整的样本聚合和 label 生成流程,支持配置化的方式构建流式训练:从日志生成训练样本,聚合 Datahub 埋点特征,最终生成实时训练样本并存储在 Datahub 中间件和实时消息队列中,推送到实时训练系统。
实时训练系统定期从 Datahub 拉取训练样本进行训练。训练完成后,会定期保存增量参数到 OSS,并同步到 EAS 的 Processor。我们在稳定性和一致性方面做了优化,通过特征埋点提高特征一致性,并采用 flink 的 gemini kv 分离方式提升样本和特征 join 性能。我们还对特征进行 Lz4 压缩,提高 join 的稳定性和效率。
针对实时场景中的异常数据,我们进行了过滤和去重,如处理延迟或异常上报的 timestamp 和重复调用的 callback。对于延迟到达的正样本,进行延迟下发校正训练。这些优化在新品和内容场景中效果显著。

这是一些参考文献,包括 EasyRec 和 Processor 的一些文档,以及全链路推荐系统 PAI-REC 和特征工程的相关文档,这些都是构建整个阿里云上推荐系统的主要组成部分。