













正则化是一种强大的技术,通过防止过拟合来提高模型性能。本文将探索各种XGBoost中的正则化方法及其优势。

为什么正则化在XGBoost中很重要?
XGBoost是一种以其在各种机器学习任务中的效率和性能而闻名的强大算法。像任何其他复杂模型一样,它可能会过拟合,特别是在处理噪声数据或过多特征时。XGBoost中的正则化有助于通过以下方式缓解这一问题:
- 降低模型复杂度: 通过惩罚较大的系数,正则化简化了模型。
- 改善泛化能力: 确保模型在新数据上表现良好。
- 防止过拟合: 防止模型过度适应训练数据。
下面我们介绍在XGBoost中实现正则化的方法
1. 减少估计器的数量
减少估计器的数量可以防止模型变得过于复杂。两个关键超超参数包括:
n_estimators: 设置较低的树的数量可以帮助防止模型学习训练数据中的噪声。n_estimators的高值会导致过拟合,而低值可能导致欠拟合。
early_stopping_rounds: 这种技术在验证集上的性能停止改善时停止训练过程,防止过拟合。
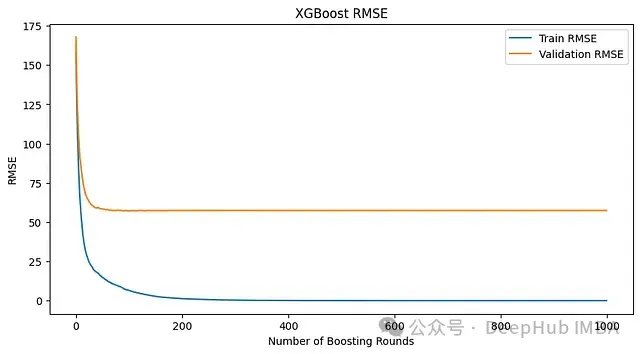
上图为没有早停的模型指标
上面的模型中,即使损失不再下降,训练也会继续。相比之下,使用early_stopping_rounds=10,当连续10轮损失没有改善时,训练就会停止。
# 初始化带有早停的XGBoost回归器
model = xgb.XGBRegressor(n_estimators=1000, learning_rate=0.1, max_depth=5)
# 使用早停训练模型
model.fit(X_train, y_train,
eval_set=[(X_test, y_test)],
early_stopping_rounds=10,
verbose=True)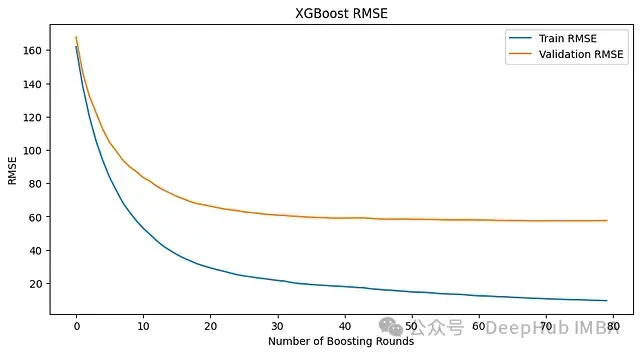
使用early_stopping_rounds=10的模型指标
2. 使用更简单的树
简化每棵树的结构也可以帮助正则化模型。关键参数包括:
gamma: 在叶节点上进行进一步分区所需的最小损失减少。较高的值会导致更保守的模型。
下面是XGBoost的目标函数。如果增加gamma,叶节点的数量(T)就会减少。gamma惩罚T并帮助防止树变得过于复杂。
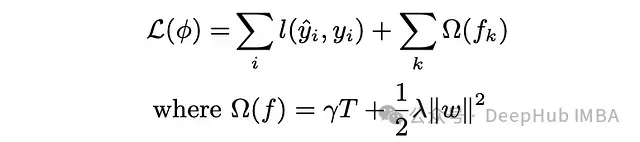
Gamma是一个后剪枝参数。以下复杂公式表示在每次分裂时计算的增益。第一、第二和第三项分别是左子节点、右子节点和父节点的相似度分数。Gamma(最后一项)是增益的阈值。
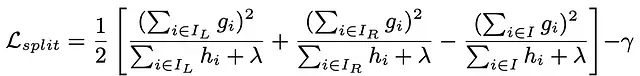
在下面的例子中,每个节点内的值代表不包含gamma项的增益。当gamma设置为400时,最底部的分支被删除,因为它不满足阈值标准,这样树就变得更简单了。
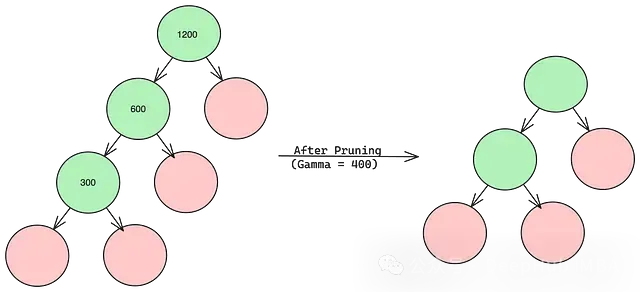
那么问题来了:gamma的最佳值是多少?答案在于超参数调优。
# 获取树的详细转储,包括统计信息
tree_dump = model.get_booster().get_dump(dump_format='text', with_stats=True)
# 打印树的转储以查看详细信息,包括每个节点的增益
for tree in tree_dump:
print(tree)上面的代码将显示所有决策树的转储。通过观察所有节点的增益,我们可以尝试不同的gamma值。
import xgboost as xgb
# Gamma的实现
model = xgb.XGBRegressor(n_estimators=3, random_state=42, gamma = 25000)但是有一点,gamma值过高会导致欠拟合,因为它减少了树的深度,而gamma值过低会导致过拟合。
max_depth: 限制树的最大深度。较低的值可以防止模型学习过于具体的模式。这是一个预剪枝参数。
思考题1:当我们有gamma时,为什么还需要max_depth?(答案在最后)
min_child_weight: 要解释这个参数就要先了解什么是cover。
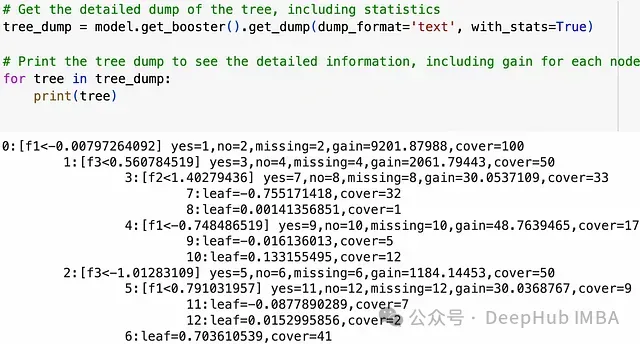
当我们进行树转储时,我们会看到所有节点的cover值。Cover是hessians的总和,而hessian是损失函数相对于预测值的二阶导数。
我们以一个简单的损失为例,对于均方损失函数的回归问题,hessian的值为1。所以在这种情况下,cover基本上是每个节点中的数据点数量。因此min_child_weight是每个节点中应该存在的最小数据点数量。它对每个节点设置以下条件:cover > min_child_weight。
xgboost中回归问题的min_child_weight类似于决策树中的min_sample_split。
import xgboost as xgb
# min_child_weight的例子
model = xgb.XGBRegressor(n_estimators=100, learning_rate=0.1, max_depth=5, min_child_weight=10, gamma=1, random_state=42)对于分类问题,理解这一点有点棘手,但是简单来说分类中min_child_weight的一句话描述是:它为数据点的重要性设置了一个阈值。
所以我们只要记住min_child_weight是一个预剪枝参数。增加min_child_weight会减少过拟合。
3. 采样
采样涉及在数据的子集上训练模型,这可以通过引入随机性来减少过拟合。
subsample: 用于训练每棵树的训练数据的百分比。较低的值可以防止过拟合。子采样使每个决策树成为数据子集的专家,遵循"群众的智慧"原则。根据数据的不同,0.5到0.8的范围通常会给出良好的结果。
colsample: 用于训练每棵树的特征的百分比。这也可以用来引入随机性并防止过拟合。colsample有以下三种类型,它们的值范围从0到1。这些按引入随机性的增加顺序排列如下。假设我们的数据中有10个特征,所有这些超参数的值都设置为0.5:
- colsample_bytree : 为每棵树随机选择5个特征,并根据这些特征进行分裂。
- colsample_bylevel : 为每个级随机选择5个特征,并根据这些特征进行分裂。
- colsample_bynode : 为每个节点随机选择5个特征,并根据这些特征进行分裂。
import xgboost as xgb
# subsample和colsample的例子
model = xgb.XGBRegressor(n_estimators=100, subsample=0.8,
max_depth=5, colsample_bytree=0.5,
colsample_bylevel=0.5, colsample_bynode=0.5)4. 收缩
收缩减少了每棵单独树的影响,使模型更加稳健:
learning_rate (收缩): 减少每棵树的影响。较低的值意味着模型构建更多的树,但不太可能过拟合。0.3是许多模型的合适学习率。
lambda和alpha: L2(岭)和L1(Lasso)正则化项,惩罚大系数。

当增益小于gamma时,该节点就会被剪枝。当lambda增加时,过拟合减少,欠拟合增加。Lambda与gamma一起用于正则化。
思考题2:当我们有gamma时,为什么还需要lambda?
import xgboost as xgb
# reg_lambda是lambda的超参数,reg_alpha是alpha的超参数
model = xgb.XGBRegressor(n_estimators=3, learning_rate=0.3, reg_lambda=100, reg_alpha=100, gamma=10000)思考题答案
1、XGBoost中即使有了gamma参数,我们仍然需要max_depth参数。
在XGBoost中,gamma和max_depth虽然都用于控制树的生长,但它们的工作方式和目的略有不同:
- gamma(最小分裂损失):
- gamma是一个后剪枝参数。
- 它控制节点分裂时所需的最小损失减少量。
- 如果分裂导致的损失减少小于gamma,那么这个分裂就不会发生。
- gamma更关注的是分裂的质量。
- max_depth(最大树深):
- max_depth是一个预剪枝参数。
- 它直接限制了树可以生长的最大深度。
- 无论分裂的质量如何,一旦达到max_depth,树就会停止生长。
- max_depth更关注的是树的整体结构。
为什么两者都需要:
1.不同的控制粒度:
- gamma提供了一种基于性能的细粒度控制。
- max_depth提供了一种简单直接的粗粒度控制。
2.计算效率:
- 只使用gamma可能导致在某些情况下树过度生长,增加计算复杂度。
- max_depth可以有效地限制计算资源的使用。
3.模型可解释性:
- 过深的树可能难以解释,即使每次分裂都是有意义的。
- max_depth可以保持树的结构相对简单。
4.处理不同类型的数据:
- 对于某些数据集,基于gamma的剪枝可能不够,树仍然可能过度生长。
- max_depth提供了一个绝对的上限。
5.互补作用:
- 两个参数一起使用可以更灵活地控制模型的复杂度。
- 它们共同作用,可以在模型性能和复杂度之间取得更好的平衡。
总之,gamma和max_depth在控制树的生长方面起着互补的作用。gamma关注分裂的质量,而max_depth确保树不会变得过于复杂。同时使用这两个参数,可以更好地平衡模型的性能、复杂度和可解释性。
2、为什么在XGBoost中即使有了gamma参数,我们仍然需要lambda参数。
在XGBoost中,gamma和lambda虽然都用于正则化,但它们的工作方式和目的是不同的:
- gamma(最小分裂损失):
- gamma主要用于控制树的生长。
- 它设置了节点分裂所需的最小损失减少量。
- 如果分裂导致的损失减少小于gamma,那么这个分裂就不会发生。
- gamma更关注的是树的结构和复杂度。
- lambda(L2正则化项):
- lambda是应用于叶子权重的L2正则化项。
- 它直接惩罚模型的权重。
- lambda帮助防止模型对个别特征过度依赖。
- 它可以使模型更加稳定和泛化能力更强。
为什么两者都需要:
- 不同的正则化目标:
- gamma主要影响树的结构。
- lambda主要影响叶子节点的权重。
- 模型复杂度的不同方面:
- gamma通过限制树的生长来减少复杂度。
- lambda通过缩小权重来减少复杂度。
- 处理不同类型的过拟合:
- gamma可以防止模型学习训练数据中的噪声。
- lambda可以防止模型对某些特征过度敏感。
- 互补作用:
- 同时使用这两个参数可以更全面地控制模型的复杂度。
- 它们一起工作可以在模型的结构和权重上都实现正则化。
- 灵活性:
- 在某些情况下,你可能想要一个深度较大但权重较小的树,或者相反。
- 有了这两个参数,你可以更灵活地调整模型以适应不同的数据集和问题。
- 收缩效果:
- 如之前提到的,lambda还有一个额外的作用,就是对树的输出进行收缩。
- 这种收缩效果可以进一步帮助防止过拟合,特别是在梯度提升的早期阶段。
gamma和lambda在XGBoost中起着互补的作用。gamma主要控制树的结构,而lambda主要控制叶子节点的权重和树的输出。同时使用这两个参数,可以更全面、更灵活地控制模型的复杂度,从而在不同层面上防止过拟合,提高模型的泛化能力。这种多层面的正则化策略是XGBoost强大性能的关键因素之一。




















