一、背景
OLAP场景是大数据应用中非常重要的一环,能够快速、灵活地满足业务各种分析需求,提供复杂的分析操作和决策支持。B站主流湖仓使用Iceberg存储,通过建表优化可以实现常规千万级的指标统计秒级查询,这样就能快速搭建可视化报表,但当数据量达到亿级、需要交叉分析维度复杂多表情况下,想要支持秒级就变得困难。因此B站数据分析或者数据开发同学为了能有秒级响应的报表,需要通过ETL grouping sets 提前设计要参与多维分析的维度和指标,然后在ADS层离线计算好对应的数据cube。这有点类似Kylin的预计算模式,区别是查询效率和查询SQL复杂度要更高,毕竟Kylin底层是KV存储并且做了SQL解释器,而原始grouping sets模式得让下游自己选cube切片。比如Push业务DWB表几十亿数据量,想要快速支持十几个维度和十几个指标秒级交叉分析,只能开发提前配置好要参与分析的维度组合,在可视化界面也需要提前说明只支持这几个维度组合。
OLAP引擎中Kylin 也逐渐被淘汰了,因为只能预计算而不能现算,要满足新的分析维度视角和指标得重新配置和数据同步成本巨大,当然ETL grouping sets这种更原始的方式成本只会更大,以下列举了数据平台ETL任务中用到grouping sets 预计算所使用资源开销:
ETL种类 | 任务数 | CPU开销/cpu_vcore_d | 内存开销/mmr_tb_d |
多维分析任务 | 563(0.7%) | 4448.90(10.8%) | 5.43(33.2%) |
当前多维分析的任务只占总任务数不到1%,却贡献了10.8%的CPU日开销和33.2%的内存日开销,实属浪费,下游ADS报表使用极其繁琐,运维成本较大。
B站当前主流OLAP引擎是ClickHouse,和主流引擎Doris、StarRocks一样,ClickHouse同样采用MPP架构和列式存储格式,可以满足亿级数据量的秒级甚至亚秒级查询,其专注于OLAP场景优化,但在join操作和读QPS上不如Doris、StarRocks高效。报表场景下对QPS要求不高,但join能力要能跟上,而小数据量join 性能影响就不大了,为此我们计划将大表加工成聚合小表,即满足多维分析场景,也能满足外部扩展join场景。
为了保证指标和维度一致性,避免重复加工和数据冗余、歧义,我们将这种ClickHouse聚合加速功能集成在指标服务平台(OneService,OS),由OS统一做加速配置、API注册、SQL查询解析。此外,聚合加速的难点在于对去重指标的处理,因此除了涉及聚合数据模型设计、数据同步、OS工程集成,本文还会详细阐述如何将字符串的去重实体转化为ClickHouse的去重聚合实体集合 groupBitmap(即RoaringBitmap,RBM),如何生成映射字典去满足多个RBM能够快速交并差运算。
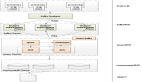
二、总体架构设计图
 图片
图片
三、数据方案设计
3.1 模型设计
多维分析加速的核心是如何设计数据聚合方案,满足多维快速分析场景。按照指标是否去重,所有的多维聚合分析指标按照其所在数仓模型可以被拆分成两部分:一、无需去重计算,即所需要的指标直接在需要分析的维度上进行聚合处理,比如max、count、sum等,这类对应数仓模型通常无需关注实体或者实体粒度唯一;二、 需要去重计算,例如UV(Unique Vistor)、PU(Paid User)、RU(Revenue User)、DAU(Daily Active User)等,如果所在模型粒度不是要去重的实体,则必须使用distinct去重运算 。实际数仓模型设计中两者皆有的情况占大多数,即实体不唯一,而实体产生的业务指标又可累加,因此需要同时设计两种聚合模式。以播放为例,假如有张播放DWB表,每日1亿条记录,定义如下:
Play_dwb_tbl(
uid bigint comment '用户ID'
,deviceID string comment '设备ID'
,area_id bigint comment '分区ID'
,area_name string comment '分区名'
,uid_city string comment '用户自填城市'
,uid_gender string comment '用户自填性别'
,play_duration bigint commnet '播放时长'
,dt string '统计日期'
)想要统计在不同维度组合的播放时长、播放用户数、播放设备数。
直接聚合模式,即对无需去重的指标组合其维度生成聚合表。以上面案例举例,播放时长指标不依赖实体可直接累加,生成如下表:
Play_dwb_tbl_aggr_directly(
area_id bigint comment '分区ID'
,area_name string comment '分区名'
,uid_city string comment '用户自填城市'
,uid_gender string comment '用户自填性别'
,paly_duration bigint commnet '播放时长'
,dt string '统计日期'
)结果每日大概1万条记录,将这1万条记录导入到OLAP引擎可以快速满足任意多维分析需求。这种模式比较简单和传统,本文重点讲另一种模式。
去重聚合模式,即对需要去重的指标生成聚合表。以上面案例举例,播放用户数、播放设备数就是分别对用户和设备两种不同实体的聚合。分析其ER关系可知,性别、城市由uid唯一映射,但同一个设备可能有多个uid,因此不能被设备ID唯一映射;分区ID和分区名属于联合维度,一一对应不可分割。根据ER关系划分维度组合,相同维度分析不同指标底层的实现复杂度相差极大。对于播放设备数,uid和分区是其必要维度,uid虽然是实体不需要参与分析,但其关联维度需要放入,最终全维度放入聚合维度池;对于播放用户数,由于存在实体的唯一映射,可以划分3个维度组合(dt、uid_city)、 (dt、uid_gender)、 (dt、area_id、area_name) 放入聚合维度池,可以利用三个维度对应实体集合交并实现多维分析(这里实体集合的生成涉及字典服务,后文会详解),相对于全维度组合其组合枚举值大大减少。去重聚合模式的维度划分逻辑如下图所示:
 图片
图片
对于entityM,根据ER关系中有多少个唯一映射就可以拆多少个维度集合,剩下不能再唯一映射的维度当成实体关联维度打包成一个维度集合。
通过以上实例分析,不管哪种聚合模式都可能存在维度组合爆炸情况,极端情况其聚合模型的记录数和原模型一致,就没有聚合加速的优势。实际情况下我们的聚合模型是要面向可视化报表、面向实际业务分析场景,不可能需要到实体粒度的维度组合展现,因此在生产聚合模型的时候系统会自动检查参与分析的维度组合数量是不是超标。此外还有一些其他规则,比如日期维度需要强制选择,去重实体在字典服务中存在映射字典等等。整体数据流程见下图:
 图片
图片
接下来重点讲下去重聚合模式(RBM aggr)在ClickHouse中的的设计、同步实现和查询。
3.2 Schema设计
 图片
图片
dim_name和dim_value包含多种维度组合,分别代表维度名和维度值。实际查询中必用ind_name,dim_name大部分场景都会使用, 因此设计成LowCardinality(String)意味着它可以有效地压缩重复字符串值,从而减少存储空间的使用,其使用的字典编码还可以提高查询的性能。在统计每日的去重实体数时不需要ind_name,这也是很频繁的场景,因此我们还添加了Projection操作预计算:
PROJECTION projection_logdate (
SELECT dt, ind_name, groupBitmapOrState(ind_rbm) ,count(1)
GROUP BY dt, ind_name
)这样就没必要扫描所有dim_name去重复统计(每个dim_name算出的来的去重实体数必然一样),另外在执行'!='操作的时,完全可以拿这个预计算结果和右边的维度值对应的ind_rbm做差集马上可以得到结果,性能和算'='一样。此外dim_value添加布隆过滤索引,针对多维筛选可以加速分析。
3.3 数据同步
 图片
图片
完整的数据同步图如上图所示。dwb_tbl为待同步的原始数据模型,sync_tbl为待同步到ClickHouse的数据模型,和目标表的Schema一样,整个过程核心包含三个步骤,以下详述S1, S2, S3三个步骤的内容。
S1:产出预加工模型,其结构如下:
Temp_1(
dt string comment '日期'
,ind_name string comment '指标名'
,ind_value string comment '实体值'
,dims_map map<string,string> comment '{dim_name:dim_value}'
)目标是将不同的原数据模型加工成统一模型表以适配后续流程。用户选择要分析的维度和指标,而这些维度和指标在OS上可以二次定义或者衍生,OS自动生成产出这些维度和指标的SQL,之后统一封装成预加工模型。这里ind_value为要去重指标的实体值,这个实体值不管是数值还是字符串,统一存储为字符串格式。dims_map聚合了后续需要的dim_name和dim_value,目的是保证ind_value粒度,后续转化字典的时候不需要重复请求,降低计算成本。
S2:获取映射字典,即将ind_value转化为预设的稠密字典值,实现字符转数字。通过OS拿到指标实体所用的字典,这里优先会请求已有的离线映射字典表(若未就绪自动取最新分区数据),如果获取不到再请求字典服务申请新的字典,新的记录后续会离线存放到映射字典表中,避免后续再重复请求,降低字典服务压力,让亿级别数据量能分钟级生成字典。
S3:产出要同步到ClickHouse的数据模型。由于目标表是分布式CK聚合表,这里需要根据实体的字典值映射到要写入的shard,按照指标名+维度+shard粒度对这些字典值进行RBM聚合操作。
3.4 数据查询
查询场景有很多,这里主要说明下多维分析在已知筛选条件下的查询实现。以上述播放数据为例,对应ClickHouse本地表为Play_ck_tbl_local,分布式表为Play_ck_tbl,分别查询某日的上海用户在分区ID为1下的播放指标:
-- example1.查询播放用户数
select
sum(`播放用户数`)
from cluster('XXX', view(
select
bitmapAndCardinality(a.ind_rbm, b.ind_rbm) AS `播放用户数`
from(
select
ind_rbm
from Play_ck_tbl_local
where dt='XX' and ind_name='播放用户数' and dim_name='uid_city' and dim_value[1]='上海'
)a join (
select
ind_rbm
from Play_ck_tbl_local
where dt='XX' and ind_name='播放用户数' and dim_name='area_id' and dim_value[1]='1'
)b on 1=1
)tmp
-- example2.查询播放设备数
select
bitmapCardinality(groupBitmapOrState(ind_rbm)) `播放设备数`
from Play_ck_tbl
where dt='XX' and ind_name='播放设备数' and dim_name = 'area_id,area_name,uid_city,uid_gender'
and dim_value[1]='1' and dim_value[3]='上海'两个指标维度一样,但查询逻辑有很大不同。播放用户数指标对应多个维度集合存储,需要将涉及到的维度集取出后做关联取交集运算,由于本地表是按照实体字典做了分shard处理,因此只要实现本地Colocate Join逻辑后求和即可得到结果。播放设备数指标只有一个维度集合,这个维度集合包含了想要参与多维分析的所有维度值组合,因此只要限制维度值数组指定位置取值为筛选条件即可。
需要注意的是前面限制维度基数的原因在这里可以体现。如果有多个维度集合需要join运算,要求每个维度集合不能太多,我们利用的是ClickHouse小数据量join能力,如果太大会带来性能损耗,无法满足秒级查询要求。
四、字典服务方案的优化演进
4.1 基于Snowflake算法的字典服务
Snowflake是Twitter开源的一种分布式ID生成算法。基于64位数实现,下图为Snowflake算法的ID构成图:
 图片
图片
- 第1位置为0。第2-42位是相对时间戳,通过当前时间戳减去一个固定的历史时间戳生成。第43-52位是机器号workerID,每个Server的机器ID不同。第53-64位是自增ID。通过时间+机器号+自增ID的组合来实现完全分布式的ID下发
- Leaf提供了Java版本的实现,同时对Zookeeper生成机器号做了弱依赖处理,即使Zookeeper有问题,也不会影响服务。Leaf在第一次从Zookeeper拿取workerID后,会在本机文件系统上缓存一个workerID文件。即使ZooKeeper出现问题,同时恰好机器也在重启,也能保证服务的正常运行。这样做到了对第三方组件的弱依赖,一定程度上提高了SLA。
4.2 用离散数据构建Bitmap的问题
基于snowflake算法生成的字典值在连续数值空间上的分布是相对离散的,所以基于snowflake字典构建的bitmap中的数据也是比较离散的。ClickHouse使用RoaringBitmap存储bitmap数据,而由于RoaringBitmap的结构设计,使其并不适合用于存储和计算由离散数据构建而成的bitmap。下面我们从RoaringBitmap的结构原理出发,阐述离散数据分布下bitmap存储和计算所面临的问题。
一个32位RoaringBitmap的内部结构如下图:
 图片
图片
首先以数字的高16位来确定分桶,然后低16存储到对应container中。
根据存储数据的数量和分布情况,会使用不同种类的container来使计算更加高效。
- Array Container:桶内数据小于4096个,计算效率低
- Bitmap Container:桶内数据大于4096个,计算效率高
- Run Container:对连续数字使用RLE编码来压缩空间,最省空间
针对64位的bitmap,则是先将64位整型的高32位分桶,低32位则使用RoaringBitmap32表示。
通过上述对RoaringBitmap结构的分析,我们可以看出,存入bitmap的数据连续性越高,则bitmap的存储空间就越小,计算效率也越高。
基于Snowflake算法生成的字典值连续性低,高位稠密,低位稀疏,导致生成的roaring bitmap中包含大量的array container,从而导致bitmap计算消耗大量内存资源,且计算效率非常低。
4.3 ClickHouse稠密字典编码服务体系
为了解决RoaringBitmap因数据连续性低而导致存储计算效率低的问题,我们围绕ClickHouse建设了一套稠密字典编码服务体系。
术语说明:
- 正向查询:用原始key值查询对应的字典值value。
- 反向查询:用字典值value查询对应的原始key。
4.3.1 架构设计图
 图片
图片
4.3.2 功能模块简介
稠密字典编码服务体系包括以下几个模块:
- ClickHouse字典编码模块:在ClickHouse内部新增BidirectionalDictionary功能支持,同时支持了各种dictionary functions,从支持数据在写入过程中在ClickHouse内部完成字典编码与转换,最终生成连续字典值的bitmap数据。
- Dict Service:提供字典管理(新建,删除等),字典keyToValue,valueToKey查询代理,查询缓存,批量查询等功能。既可供ClickHouse内部生成字典值bitmap数据使用,也可通过Dict Client, Dict UDF供外部数据同步组件用于生成bitmap数据后导入ClickHouse。
- Dict Client:Dict Service的客户端,用于连接Dict Service完成字典正向查询/更新和字典反向查询,同时提供查询缓存,批量查询等功能。
- Dict UDF:为数据同步组件提供Spark UDF/UDAF用于字典值转换及bitmap数据生成,以便在ClickHouse之外预先生成字典编码的bitmap数据。
- Distribute KV:基于RocksDB的分布式KV存储,用于存储正反向字典数据,同时提供全局自增器生成自增的字典值。
4.3.3 Dict Service实现方案详述
Dict Service维护了所有的字典元数据,客户端连接Dict Service做字典正向和反向查询。Dict Service的运行实例是无状态无锁的,所以Dict Service可以做分布式可扩展部署,状态同步完全依靠分布式KV存储进行,通过各种容错机制保证字典数据的正确性。
字典正向查询与更新流程图:
 图片
图片
字典正向查询与更新流程步骤说明:
- 输入的keys,首先会查询正向字典,如果能够全部命中,则向客户端返回values。
- 对于未命中的keys,首先将其进行排序去重,然后使用全局自增器分配映射值。
- 将完成映射的values → keys批量写入反向字典。
- 使用CAS操作,将keys → values写入正向字典,若发生CAS冲突,则将该key的value替换为old value。
- 向客户端返回values。
- 回收掉由于CAS冲突而未使用到的values,用于下次分配。
对于字典值,我们在KV存储中采用大端方式表示,这样可以使得反向查询效率更高,原因如下:
Dict Service应用于bitmap计算场景,用户在反向查询时,从bitmap读取数值序列并请求Dict Service做批量查询,取出的查询目标数值序列是有序的,而使用大端方式存储字典值能够保证字典值在KV存储中也是按照数值顺序排序的,这样查询目标数值序列和存储的字典值序列就都是按同样顺序排好序的,这对于使用LSM结构的RocksDB而言查询会更加高效。
4.4 bitmap计算的优化效果
基于B站真实用户行为数据,我们分别基于Snowflake算法字典服务和ClickHouse稠密字典编码服务对用户设备id做字典编码后,对比了两者在bitmap计算场景下的性能差异:

说明:测试数据为用户行为表连续七天某一时间段的所有数据,用户设备id基数约为1000万。
五、工程应用接入
5.1 前置工作
逻辑模型定义
用户期望对于已有的明细表进行物化加速, 首先需预先定义好数据模型, 包括模型中包含的指标维度, 其中
- 指标定义: 对某实体进行去重计数来计算指标, 则较为适用于rbm加速方案。反之则使用原有的聚合计算加速方式即可, 如sum, max, min, count等计算指标等。
- 如对[播放记录表]中设备与用户进行去重计数计算, 可产出[播放设备数]及[播放用户数]指标。
 图片
图片
- 实体定义: 一般来说会对, 例如: 设备id, 用户id等一系列id类信息进行去重计数, 此类信息字段即为计算实体, 并会在后续流程中, 通过字典服务将实体转换为稠密的bitmap结构(rbm)。
- 维度定义: 在模型中定义, 按某些维度对相关指标进行分析。简单理解就是需要对于哪些维度进行分组聚合(group by)。
- 主键维定义: 对于需要计算的实体字段, 必须是模型定义中的[主键]或[与某些维度组合后为主键]进行rbm数据生产, 否则会出现指标计算出现误差。
- 此处设计是基于上文[数据设计]部分所阐述的[维度组合]方案的一种让步, 考虑到用户对于维度组合的理解成本过高, 且产品交互设计复杂, 进行了一定的取舍。通过主键维定义的方式解决计算误差问题, 虽会牺牲一定的查询性能与更多的数据存储, 但对于用户来说设置主键维更好理解, 操作也更便捷。未来支持维度组设置, 也可依据一定的策略规则自动识别维度组, 减少用户配置成本。
- 用户开启rbm加速开关, 并设置合理的主键信息, 即可使用rbm的加速特性
 图片
图片
主键维定义case
假设我们有如下数据, 其中buvid在pid维度下唯一, 并对 pid, is_new 2个维度字段产出dau指标(对buvid进行去重计数计算)

当我们要分析, pid = 'android' and is_new = 'n' 维度下的dau时
- 常规sql分析方式:
select pid, is_new, count(distinct buvid) as dau
from tbl where pid = 'android' and is_new = 'n'- 产出结果为 dau=1, 其中命中此条件的buvid为'b'
- 未定义主键维方式:
- 对 pid = 'android' 与 is_new = 'n' 的2个rbm交集计算后得出的rbm为 [a=1, b=1]
- 产出的结果为 dau=2, 可见这个结果是错误的
- 定义主键维方式:
- 定位到 [pid, is_new] = [android, n] 的rbm为 [a=0, b=1]
- 产出的结果为 dau=1, 符合预期
示例:
假设我们已经定义好一个模型
 图片
图片
5.2 数据加速
在进行完模型定义后, 就可对其数据进行加速处理, 我们选择将加速数据写入olap引擎clickhouse中。
去重计数指标
首先对于需要去重计数的指标, 通过以上模型定义, 系统自动翻译出如下SQL, 提供至[数据同步]S1部分阐述的任务。
其中需要查询出每个实体命中各维度的维度值有哪些。
SELECT
log_date AS log_date,
CASE WHEN grouping(`dau`) = 0 THEN 'dau' END AS ind_name, -- 指标名
CASE WHEN grouping(`dau`) = 0 THEN `dau` END AS ind_value, -- 指标对应实体值,如此例中的buvid
map_group(dim_map) AS dims_map -- 分组聚合所有map中的元素,即为实体命中各维度的维度值
FROM
(
SELECT
log_date AS log_date,
COALESCE(CAST(dau AS string), '') AS dau,
map(
'pid',
COALESCE(CAST(pid AS string), ''), -- 实体命中的pid
'pid,device_brand', -- 主键维列表 拼接 单个非主键维
CONCAT_WS(',',
COALESCE(CAST(pid AS string), ''), -- 实体命中的pid
COALESCE(CAST(device_brand AS string), '') -- 实体命中的设备品牌
),
... -- 主键维列表 拼接 其余单个非主键维
) AS dim_map
FROM
( ... ) l1 -- 模型定义标准化
) l2
GROUP BY
log_date,
dau
GROUPING SETS((log_date, `dau`)) -- 按不同指标计算grouping setsSQL查询出的结果样例如下, 其中ind_name表示指标名, ind_value是产出此指标的某个实体, dims_map则是该实体命中各维度的维度值。
 图片
图片
例如: 第一行中的buvid命中的pid=1124, device_brand=official, is_new_user=0。
又因主键维定义, 实际会将device_brand, is_new_user维度分别与pid主键维进行组合处理, log_date本身是单独的分区字段, 则无需再进行组合。
[数据同步]任务获取到数据后, 即会进行实体字段转换并将数据写入ck聚合表中, 具体结构见上文[Schema 设计], 此处不再赘述。
ck聚合表数据样例如下, 通过bitmapCardinality函数可计算出rbm的基数值, 业务含义上即为该维度下DAU指标。后续进行多维分析时, 针对rbm进行交并计算即可得到期望值。
 图片
图片
非去重计数指标
本样例中即为vv指标, 通过模型定义中的维度, 简单分组聚合计算加速即可, SQL样例如下:
SELECT
log_date, pid, device_brand, is_new_user, -- 分析维度
SUM(vv) AS vv -- sum计算指标
FROM
( ... ) l1 -- 模型定义标准化
GROUP BY
log_date, pid, device_brand, is_new_user -- 分析维度物化模型
数据服务对于逻辑模型加速后的数据, 会对应生成物化模型的定义信息。rbm加速与聚合加速会分别创建2个物化模型定义, 两者包含的维度一致, 而指标不同。定义对比如下:
逻辑模型 | 聚合物化模型 | rbm物化模型 | |
维度 | pid, device_brand, is_new_user | ||
指标 | dau, vv - 包含所有指标 | vv - 包含非去重计数指标 | dau - 仅包含去重 |
 图片
图片
5.3 查询分析
基于以上物化加速后的数据, 数据服务即可通过物化模型定义, 翻译出对应的查询SQL。其中应用了[星座模型]的查询特性, 将2个物化模型, 分别作为2个事实表模型对待, 进行处理。复用了OneService原有的多模型查询能力。
SQL对比
rbm物化表对于查询SQL的翻译与普通数据表存在差异, 以下对比了2种不同SQL的处理特点:
 图片
图片
以下以最复杂的 [主键维+多维非主键维分析dau与vv指标] 查询模式举例:
维度过滤 log_date = '20240609' and pid = 13 and is_new_user = 1
SELECT
xxx, -- 分析维度
0 AS vv, sum(dau) AS dau -- rbm物化模型不产出vv指标,产出去重计数指标dau,此处应用ck的shard特性,对多shard间的rbm基数进行sum计算
FROM
cluster('xxx', view( -- ck多shard查询优化
SELECT
cast(device_brand AS String) AS device_brand, xxx, -- 由于rbm物化表中维度值均为string类型,需将其转换回原始类型
ind_name AS ind_name, sum(bitmapAndCardinality(device_brand_tbl.ind_rbm, is_new_user_tbl.ind_rbm)) AS ind_rbm, -- ck特性,先统一取交计算好各非主键维下rbm,提升查询性能
if(ind_name = 'dau', ind_rbm, 0) AS dau, if(ind_name = 'xxx', ind_rbm, 0) AS xxx -- 若有,可计算其他去重计数指标
FROM
( SELECT
dim_value[2] AS device_brand, dim_value[1] AS pid, -- 对应dim_name='pid,device_brand'顺序,数组第二位为device_brand,数组第一位为pid
ind_name AS ind_name, groupBitmapOrState(ind_rbm) AS ind_rbm -- 同维度rbm进行并集计算
FROM rbm_physics_tbl_local -- 查询rbm_physics_tbl分shard后的local表,性能优化
WHERE (ind_name in ('dau')) -- 指标选择
AND (log_date = '20240609') AND (dim_name = 'pid,device_brand') AND (dim_value[1] = '13') -- 维度过滤,此处等价于log_date=20240609 and pid=13
GROUP BY ind_name, dim_value[2], dim_value[1] -- 等价于ind_name, device_brand, pid -- 多维分组
) AS device_brand_tbl -- 定义device_brand维度逻辑视图
-- pid与is_new_user维度对应逻辑视图
INNER JOIN ( xxx ) AS is_new_user_tbl ON is_new_user_tbl.ind_name = device_brand_tbl.ind_name -- 多逻辑视图必须按ind_name条件join,否则会出现笛卡尔积
AND is_new_user_tbl.pid = device_brand_tbl.pid -- 多逻辑视图公共维join条件
-- 若有其他非主键维逻辑视图,以相同规则进行join
INNER JOIN ( xxx ) ON xxx
GROUP BY device_brand, is_new_user, pid, ind_name -- 按分析维+ind_name分组
)) v
GROUP BY device_brand, is_new_user, pid -- 多维分组sql逻辑说明:
1.最内层处理
a. 维度过滤需要通过对dim_value数组进行转换, 保证语义与普通where过滤一致, 并对映射后的分析维+指标名进行分组, 聚合同维度下rbm进行并集计算
b. 对于非主键维, 需定义不同子查询, 同时进行inner join操作, join键为指标名+分析维度中的公共维, 需要分析N个非主键维就需要join N-1次。若分析维度中仅包含主键维, 则无需进行join操作, 定位到dim_name='主键维'即可
c. 由于经过了底层一系列的join操作, 若分析维度或过滤条件设置不当, 可能造成join后维度基数爆炸, 会引起较为严重的影响, 具体在后文[稳定性保障]部分进行说明
2.第二层处理
a. 由于rbm加速物化表中的维度值均是以string类型进行存储, 而转换前的原表字段有对应的实际类型, 在join逻辑后需要进行反转
b. 在此层, 利用ck特性, 先统一取交计算好各非主键维下rbm基数和, 可有效提升查询性能。若直接获取rbm基数进行指标转换, 也可达成相同效果, 但查询耗时会随着非主键维数量, 乘倍上升
3.第三层处理
a. 利用ck分片特性, 进行local本地计算rbm基数合后, 再对各分片基数求和, 最终产出对应指标值
4.跨模型指标处理-可选
a. 应用[星座模型]查询实现, 分别将 [聚合物化模型]中非rbm加速的普通计算指标vv 与 [rbm物化模型]中rbm加速的去重计数指标dau, 通过union方式聚合到相同维度下, 最终返回完整结果集
性能对比
以下统计的响应时间不包含数据传输的io耗时

维度基数对于性能的影响
如下可观察到, 耗时随维度基数增加而线性增加
 图片
图片
 图片
图片
稳定性保障
加速保障: 对维度基数过大的数据进行加速, 会生成非常多的rbm结构数据。不仅加速过程中需要消耗平台极多的资源, 加速时间很长, 同时查询时的性能提升也极为有限。此类情况在用户配置加速时, 会进行数据探查校验, 并在准入阶段进行拦截。
查询保障: 为保障对rbm加速数据查询的稳定性, 避免单次查询中涉及交并计算的rbm过多, 加载大量数据至内存引起集群稳定性下降。我们在实际查询数据前, 先对数据进行了一次基数探查, 对于基数大于某阈值的查询, 直接进行拦截阻断, 避免对集群造成过多压力, 此类查询本身消耗资源较多, 且多数情况也无法在要求的时间内响应数据。基数探查是通过count计算出部分维度组合的数量, 查询性能较好, 一般在1s内能响应, 实际数据查询通常是秒级返回, 1s内的耗时损耗还是在接受范围内, 且用户体感也不十分明显, 是必要的前置校验保障。
六、未来展望
工程化支持[维度组合]方式加速rbm结构, 将能定位唯一粒度实体维度组合以最小组合方式建立, 可有效减少rbm结构数据的数量。节省存储的同时, 也提升查询性能。
目前bitmap数据主要是在离线链路生成完后写入clickhouse,后续将基于ClickHouse 字典服务构建bitmap数据生成与更新的实时链路,提升整体产品的实时分析场景能力。
引用
- Roaring Bitmaps: Implementation of an Optimized Software Library(https://arxiv.org/pdf/1709.07821)
- WeOLAP 亚秒级实时数仓 —— BitBooster 10倍查询优化实践(https://mp.weixin.qq.com/s/tJQoNRZ5UDJ_IASZLlhB4Q)