Attention is all you need.
至少在矩阵这儿是。
Mamba架构最新进展:仅需1%计算量,新模型性能达SOTA。
能做到这一点,还多亏了Transformer。
 图片
图片
通过将Transformer模型中的知识有效迁移到Mamba等替代架构中,模型能在保持较低计算成本的同时,性能更好。
这就是由Mamba主创之一Albert Gu领衔的最新成果。
值得一提的是,这种方法还适用于Mamba以外的非Transformer架构。
从Transformer到SSMs
Transformer由于依赖二次自注意力机制,所需计算量很大。
二次自注意力机制能让模型在处理序列数据时有效捕捉序列内部的长距离依赖关系,但是由于二次时间复杂度(如果输入规模翻倍,模型计算所需时间增加4倍),导致处理长序列的计算成本很高。
为了解决这个问题,学界提出了很多新架构,比如Mamba、RWKV等,它们的微调和推理成本更低。
考虑到Transformer模型预训练已经投入了大量计算资源,研究人员想到,为什么不能在此基础上进行提升?
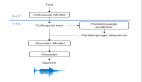
所以在本项研究中,他们提出了一种蒸馏方法MOHAWK,利用Transformer预训练模型来训练SSMs模型。
其核心在于注意力机制、线性注意力、Mamba的结构化掩码注意力SMA等,都是跨输入长度维度的序列转换。因此它们都有各自的矩阵混合器,比如softmax。
 图片
图片
通过将注意力和SSMs视为通过应用不同类别的矩阵来混合不同token嵌入的序列变换,序列模型架构可以分解为独立序列混合和通道混合块。
比如Transformer由注意力(序列混合器)和MLP(通道混合器)块组成,使用这种分解可以蒸馏模型的每个元素。
具体蒸馏分为三个阶段:
第一阶段:矩阵对齐(Matrix Orientation)。对齐序列变换矩阵本身。
第二阶段:隐藏状态对齐(Hidden-State Alignment)。对齐网络每个单独层的隐藏状态表示,且不牺牲预先学习的表示。
第三阶段:权重转移和知识蒸馏(Weight-Transfer and Knowledge Distillation)。通过一个端到端训练阶段,将权重转移,最终使用只有一小部分训练数据来蒸馏网络的最终输出。
利用这个方法来实际修改一个模型,比如Phi-Mamba。
 图片
图片
它结合了Mamba-2和Phi-1.5。
通过MOHAWK方法,该模型从预训练的Transformer模型中学习,同时作为状态空间模型,它在处理长序列上比传统Transformer架构更高效。
该模型仅使用3B token进行蒸馏,数据量为从头训练模型的1%,但是性能达到开源非Transformer架构中的SOTA。
 图片
图片
实验发现,隐藏状态对齐更好,可以提高后续阶段的性能。
 图片
图片
研究团队也发布了混合Phi-Mamba-1.5B,通过5B token蒸馏,模型与类似混合模型表现相当,但是注意力层只用了4层。
 图片
图片
值得一提的是,这种蒸馏方法不止适用于Mamba。
 图片
图片
该研究由CUM助理教授、Cartesia AI联合创始人及首席科学家Albert Gu领衔。
去年,他和FlashAttention作者Tri Dao一起提出了Mamba,成为第一个真正实现匹配Transformer性能的线性时间序列模型。
论文地址:https://arxiv.org/abs/2408.10189