计算机视觉可以是不同规模的机器学习应用的重要组成部分,从价值20,000美元的特斯拉机器人或自动驾驶汽车到智能门铃和吸尘器。这也是一个具有挑战性的任务,因为与云基础设施相比,在“真实”的边缘设备上,硬件规格通常更加受限。
YOLO(You Only Look Once,你只需看一次)是一个流行的目标检测库;它的第一版是在2015年制作的。YOLO对于嵌入式设备特别有趣,因为它几乎可以在任何地方运行;不仅有Python版本,还有C++(ONNX和OpenVINO)和Rust版本可用。一年前,我在树莓派4上测试了YOLO v8。现在,许多事情都发生了变化——新的树莓派5已经可用,而且更新的YOLO v10也已经发布。因此,我期望在新硬件上的新模型能够更快、更精确地工作。
本文中介绍的代码是跨平台的,所以没有树莓派的读者也可以在Windows、Linux或OS X电脑上运行它。

树莓派
对于可能从未听说过树莓派的人来说,让我们做一个简短的介绍。树莓派是一个小型信用卡大小的单板计算机,拥有4-8GB的RAM,并且能够运行完整的Linux版本:

树莓派小巧、安静且相对便宜,价格约为100美元。它还有很多端口(USB、GPIO、SPI/I2C、HDMI等)与不同的硬件通信。树莓派不仅被业余爱好者广泛使用,而且在工业中也有应用(树莓派计算模块专门为嵌入式应用设计)。这就是为什么看到我们可以使用最新的YOLO模型在最新的树莓派上获得什么样的性能是很有趣的。
安装
要在树莓派上运行YOLO,我将使用Ubuntu 64位。这是最简单的方式,因为Ubuntu不仅是最受欢迎的Linux发行版,而且也是官方认证适用于树莓派的。64位的Raspbian操作系统也应该可以工作,但在上面安装最新的库和框架可能具有挑战性。上次我尝试时,很多库和组件都过时了,而且apt仓库中没有最新版本。32位操作系统根本不支持Python YOLO版本,因为PyTorch(依赖项之一)不再支持32位架构。
在编写代码之前,让我们准备树莓派上的虚拟环境(这里,我使用“pi”作为树莓派用户的默认名称):
mkdir /home/pi/Documents/YOLO
cd /home/pi/Documents/YOLO
python3 -m venv yolo
source yolo/bin/activate现在,我们准备安装所需的库:
sudo apt install libgl1
pip3 install opencv-python ultralytics supervision不同的YOLO模型可用,我们可以从GitHub下载它们。我将使用YOLO v10 Large (x)、Medium (m)和Nano (n)模型:
wget https://github.com/THU-MIG/yolov10/releases/download/v1.0/yolov10n.pt
wget https://github.com/THU-MIG/yolov10/releases/download/v1.0/yolov10m.pt
wget https://github.com/THU-MIG/yolov10/releases/download/v1.0/yolov10x.pt基本使用
当模型加载后,我们可以使用Python。要获得结果,我们只需要几行代码:
from ultralytics import YOLO
model = YOLO("yolov10m.pt")
results = model.predict("image.jpg",
save=False, save_txt=False,
verbose=False, conf=0.75)
results[0].show()在这里,我指定了75%的置信度阈值。库为我们做了所有必要的工作,在屏幕上显示了注释后的图像。输出看起来像这样:

我们还可以得到文本形式的数据,这对于没有屏幕的“无头”系统可能有用:
model = YOLO("yolov10m.pt")
results = model.predict("image.jpg",
save=False, save_txt=False,
verbose=False, conf=0.75)
boxes = results[0].boxes
confidence, class_ids = boxes.conf, boxes.cls.int()
rects = boxes.xyxy.int()
for ind in range(boxes.shape[0]):
print(model.names[class_ids[ind].item()],
confidence[ind].item(),
rects[ind].tolist())在那种情况下,输出看起来像这样:
car 0.9247599244117737 [561, 311, 719, 420]
car 0.9067108035087585 [464, 303, 554, 380]
car 0.9027121663093567 [402, 300, 481, 367]
car 0.8614686727523804 [524, 310, 592, 396]
bicycle 0.8476000428199768 [181, 321, 241, 400]
person 0.8029575347900391 [71, 271, 126, 421]
person 0.7965097427368164 [186, 278, 237, 381]
bicycle 0.7882957458496094 [111, 330, 156, 414]自定义注释
正如我们从前面的示例中看到的,results[0].show()方法正在做添加框架和标签到输出图像所需的工作。在Supervision库的帮助下,我们可以使用更复杂的自定义注释:
import supervision as sv
img = cv2.imread('image.jpg')
results = model.predict(img, ...)
detections = sv.Detections.from_ultralytics(results[0])
# Add Boxes
sv.BoxCornerAnnotator(thickness=2).annotate(
scene=img,
detections=detections
)
# Add Labels
labels = []
for ind, class_id in enumerate(detections.class_id):
labels.append(f"{model.model.names[class_id]}: {detections.confidence[ind]:.2f}")
sv.LabelAnnotator().annotate(
scene=img,
detections=detections,
labels=labels
)
# Show
cv2.imshow("Image", img_out)
cv2.waitKey(0)
cv2.destroyAllWindows()在这里,我首先创建了一个标签列表,然后使用了LabelAnnotator和BoxCornerAnnotator类在图像上绘制结果。输出看起来像这样:

摄像头流
在前面的示例中,我使用了一个静态的JPEG图像。这对于测试很好,但在实际应用中,来自USB摄像头的实时流可能更有用。
我们可以使用OpenCV轻松获取摄像头流,并使用与之前相同的代码:
def predict_and_annotate(model: YOLO, img: Any):
""" Predict the labels and return the annotated image """
results = model.predict(source=img,
save=False, save_txt=False, verbose=False,
conf=0.75)
detections = sv.Detections.from_ultralytics(results[0])
...
img = img.copy()
sv.LabelAnnotator().annotate(
scene=img,
detections=detections,
labels=labels
)
return img
# Run the camera stream
model = YOLO("yolov10m.pt")
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 1280)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 720)
while True:
ret, frame = cap.read()
frame = predict_and_annotate(model, frame)
cv2.imshow("WebCam", frame)
if cv2.waitKey(30) == 27: # Stop with Escape key
break
cap.release()
cv2.destroyAllWindows()显然,除了cv2.imshow调用之外,还可以使用其他数据处理。
结果
最后,我们拥有了所有需要的代码,是时候看看结果了!正如文章开头所写的,在过去的一年中,有两件事发生了变化:发布了新的YOLO v10模型,并且新的树莓派5也变得可用。因此,分别检查这些因素是有意义的。
准确性
为了比较准确性,我使用相同的图像运行了YOLO v8和v10 Medium模型:

正如我们所看到的,结果几乎相同。然而,YOLO v10模型错过了一个被v8检测到的人。显然,一张图片不足以作为“基准”,读者欢迎使用自己的数据进行更多测试。
性能
首先,比较YOLO v10与v8的性能很有趣。正如YOLOv10论文中所写,“我们从效率和准确性的角度全面优化了YOLO的各种组件”,所以我期望新模型更快。树莓派没有GPU,所以我在桌面上进行了这个测试:
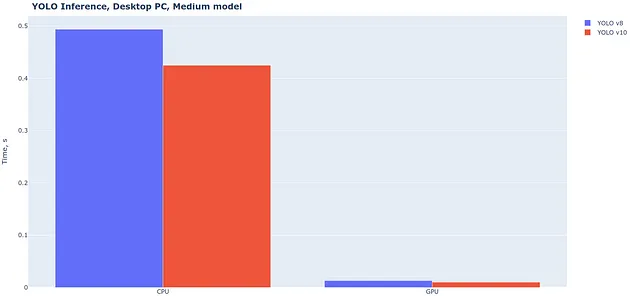
确实,YOLO v10稍微(5-15%)更快,这是一个不错的改进。其次,看看YOLO v10模型(Nano、Medium和X-Large)在不同版本的树莓派上的表现也很有趣:

结果很有趣。确实,树莓派5比树莓派4快了2倍以上。在树莓派5上,使用最小的Nano模型,单张图像处理大约需要0.6秒。然而,这台微型计算机与全尺寸桌面PC相比,计算能力仍然要小得多。
结论
在本文中,我测试了最新的(在撰写本文时)YOLO v10模型,该模型于2024年5月发布,结果很有趣。
首先,与一年前可用的新YOLO v10模型相比,速度略快,这是一个不错的改进。其次,树莓派5也比前一个模型更快,我们可以使用最小的“Nano”模型从摄像头流中实现大约0.6秒每张图像的性能。一般来说,0.6秒的处理时间还不错。树莓派是一台小型且低成本的计算机;它不足以用于实时应用,如街道导航,但可以足够好,例如,用于检测停车场上的汽车或通过每分钟拍照来估计商店中的人数。如果我们想要更快的速度,可以使用像NVIDIA Jetson这样的板子;它们更强大,但也更昂贵。