译者 | 布加迪
审校 | 重楼
本文揭示了聚类分析在分割、分析和洞察相似数据组方面具有的潜力。
机器学习不仅仅涉及做预测,还涉及其他无监督过程,其中聚类尤为突出。本文介绍了聚类和聚类分析,着重表明了聚类分析在分割、分析和洞察相似数据组方面具有的潜力。
什么是聚类?
简单来说,聚类就是将相似的数据项分组在一起,这好比在杂货店里将相似的水果蔬菜摆放在一起。
不妨进一步阐述这个概念:聚类是一种无监督学习任务,涉及一系列广泛的机器学习方法,假设数据未标记或未先验分类,旨在发现其底层的模式或洞察力。具体来说,聚类的目的是发现有相似特征或属性的数据观测组。
以下是聚类在众多机器学习技术中所处的位置:

为了更好地理解聚类概念,不妨想想在超市中寻找有相似购物行为的客户群,或者将电子商务门户网站中的大量产品分门别类,这些是涉及聚类方法的真实场景的常见例子。
常见的聚类技术
数据聚类的方法有好多种,最流行的三种方法如下:
- 迭代聚类:这些算法将数据点迭代分配(有时重新分配)给各自的聚类,直到它们收敛于一个“足够好”的解决方案。最流行的迭代聚类算法是k-means,它通过将数据点分配给由代表性点(聚类中心)定义的聚类来进行迭代,并逐渐更新聚类中心,直到实现收敛。
- 分层聚类:顾名思义,这种算法使用自上而下的方法(分割一组数据点,直到拥有所需数量的子组)或自下而上的方法(将相似的数据点像气泡一样逐渐合并到越来越大的组中),构建基于分层树的结构。AHC(聚合式分层聚类)是自下而上的分层聚类算法的常见例子。
- 基于密度的聚类:这些方法识别数据点的高密度区域以形成聚类。DBSCAN(基于密度的噪声应用空间聚类)是属于这一类的一种流行算法。
聚类和聚类分析一样吗?
- 眼下最紧迫的问题可能是:聚类和聚类分析指同一个概念吗?
- 毫无疑问,两者非常密切相关,但不是一回事,两者存在细微的差异。
- 聚类是对相似数据进行分组的过程,以便同一组或聚类中的任何两个对象比不同组中的任何两个对象更相似。
- 聚类分析是一个更广泛的术语,不仅包括对数据进行分组(聚类)的过程,还包括在特定领域上下文对获得的聚类进行分析、评价和解释。
下图表明了这两个经常混淆的术语之间的区别和关系。

实际例子
不妨现在开始关注聚类分析,为此举一个实际的例子:
- 分割一组数据。
- 分析得到的数据片段。
注意:本例中附带的代码,假设你熟悉Python语言的基础知识和一些库,比如Sklearn(用于训练聚类模型)、Pandas(用于数据整理)和Matplotlib(用于数据可视化)。
我们将使用帕尔默群岛企鹅(https://www.kaggle.com/datasets/parulpandey/palmer-archipelago-antarctica-penguin-data)数据集阐述聚类分析,该数据集含有对阿德利企鹅、巴布亚企鹅和帽带企鹅三种不同物种的数据观测。这个数据集在训练分类模型方面非常流行,但在寻找数据聚类方面也颇有用处。加载数据集文件后,我们要做的就是假设“species”类属性是未知的。
import pandas as pd
penguins = pd.read_csv('penguins_size.csv').dropna()
X = penguins.drop('species', axis=1)我们还将从数据集中删除描述企鹅性别和观测到该物种所在岛屿的两个类别特征,留下其余的数字特征。我们还将已知的标签(species)存储在一个单独的变量y中:它们便于稍后将获得的聚类与数据集中实际的企鹅分类进行比较。
X = X.drop(['island', 'sex'], axis=1)
y = penguins.species.astype("category").cat.codes使用下面几行代码,我们就可以运用Sklearn库中可用的k -means聚类算法,在我们的数据中找到k个聚类。我们只需指定我们想要找到的聚类的数量,在本文中,我们将数据分成k=3聚类:
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 3, n_init=100)
X["cluster"] = kmeans.fit_predict(X)上面最后一行代码存储了聚类结果,即分配给每个数据实例的聚类的id,存储在名为“cluster”的新属性中。
接下来可以生成聚类的一些可视化图来分析和解释它们了!下面的代码片段有点长,但可以归结为生成两个数据可视化图:第一个显示了两个数据特征(喙长culmen length和前肢长flipper length)周围的散点图以及每个观测值所属的聚类,第二个可视化图显示了每个数据点所属的实际企鹅物种。
plt.figure (figsize=(12, 4.5))
# Visualize the clusters obtained for two of the data attributes: culmen
length and flipper length
plt.subplot(121)
plt.plot(X[X["cluster"]==0]["culmen_length_mm"],
X[X["cluster"]==0]["flipper_length_mm"], "mo", label="First cluster")
plt.plot(X[X["cluster"]==1]["culmen_length_mm"],
X[X["cluster"]==1]["flipper_length_mm"], "ro", label="Second cluster")
plt.plot(X[X["cluster"]==2]["culmen_length_mm"],
X[X["cluster"]==2]["flipper_length_mm"], "go", label="Third cluster")
plt.plot(kmeans.cluster_centers_[:,0], kmeans.cluster_centers_[:,2], "kD",
label="Cluster centroid")
plt.xlabel("Culmen length (mm)", fontsize=14)
plt.ylabel("Flipper length (mm)", fontsize=14)
plt.legend(fontsize=10)
# Compare against the actual ground-truth class labels (real penguin
species)
plt.subplot(122)
plt.plot(X[y==0]["culmen_length_mm"], X[y==0]["flipper_length_mm"], "mo",
label="Adelie")
plt.plot(X[y==1]["culmen_length_mm"], X[y==1]["flipper_length_mm"], "ro",
label="Chinstrap")
plt.plot(X[y==2]["culmen_length_mm"], X[y==2]["flipper_length_mm"], "go",
label="Gentoo")
plt.xlabel("Culmen length (mm)", fontsize=14)
plt.ylabel("Flipper length (mm)", fontsize=14)
plt.legend(fontsize=12)
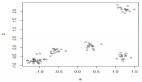
plt.show以下是可视化图:

通过观测这些聚类,我们可以得出第一个结论:
- 在分配给不同聚类的数据点(企鹅)之间有一种微妙的,但不是很清楚的分离,发现的子组之间有一些轻微的重叠。这不一定会让我们得出聚类结果是好还是坏的结论:我们已经对数据集的几个属性运用了k-means算法,但这个可视化图显示了聚类上的数据点如何仅根据两个属性“culmen length”和“flipper length”来定位。可能存在其他属性对,根据这些属性对,聚类在可视化图上被表示为更清晰地彼此分开。
这就引出了一个问题:如果我们尝试根据用于训练模型的任何其他两个变量可视化我们的聚类会怎么样?
不妨可视化企鹅的体重(克)和喙长(毫米)。
plt.plot(X[X["cluster"]==0]["body_mass_g"],
X[X["cluster"]==0]["culmen_length_mm"], "mo", label="First cluster")
plt.plot(X[X["cluster"]==1]["body_mass_g"],
X[X["cluster"]==1]["culmen_length_mm"], "ro", label="Second cluster")
plt.plot(X[X["cluster"]==2]["body_mass_g"],
X[X["cluster"]==2]["culmen_length_mm"], "go", label="Third cluster")
plt.plot(kmeans.cluster_centers_[:,3], kmeans.cluster_centers_[:,0], "kD",
label="Cluster centroid")
plt.xlabel("Body mass (g)", fontsize=14)
plt.ylabel("Culmen length (mm)", fontsize=14)
plt.legend(fontsize=10)
plt.show
这个似乎非常清楚!现在我们把数据分成了易于辨别的三组。进一步分析我们的可视化图,我们可以从中获得更多的发现:
- 发现的聚类与“体重”和“喙长”属性的值之间存在密切的关系。从图的左下角到右上角,第一组企鹅的特点是体型小,因为它们的“体重”值低,但喙长变化很大。第二组企鹅体型中等,喙长中偏高。最后,第三组企鹅的特点是体型更大,喙更长。
- 还可以观测到有少数异常值,即非典型值偏离大多数对象的数据观测。这一点在可视化区域最上方的点上体现得尤为明显,这表明在所有三组中,一些观测到的企鹅的喙都过长。
结语
本文阐述了聚类分析的概念和实际应用,即在数据中找到有相似特征或属性的元素子组,并分析这些子组从中获取有价值或可操作的洞察力。从市场营销、电子商务到生态项目,聚类分析被广泛应用于众多实际领域。
原文标题:Using Cluster Analysis to Segment Your Data,作者:Ivan Palomares Carrascosa