上一篇文章讲了表设计的18条军规,其中讲到了唯一索引的坑,今天就来细说一下。
在之前的工作中,遇到过一次唯一索引的 Bug,今天就分享分享,省的有同兄弟踩坑里。
为众人抱薪者,不可使其冻毙于风雪。兄弟们一键三连啊!!!感谢!

一、现场还原
先看表结构,其中 name、age、city 三个字段创建一个联合唯一索引。
CREATE TABLE `test` (
`id` int NOT NULL,
`name` varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL,
`age` int DEFAULT NULL,
`city` varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `name` (`name`,`age`,`city`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;如果在这三个字段上创建一个联合唯一索引,那么就不会存在两行数据在这三个字段上的值完全相同。
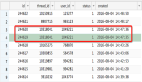
下面来看一组数据。

通过上图可以看到,北京的张三有多个,毕竟年龄可以不一样吗,其中有两个 age 为空的,同样上海的李四也有多个。
有的同学可能会说了,是不是唯一索引没生效啊,那我们现在试一下唯一索引的生效情况。
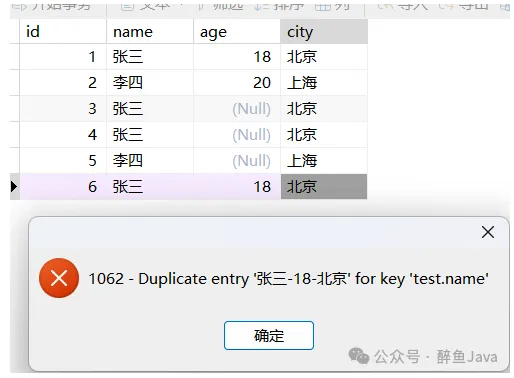
可以看到已经报错,对于这个唯一索引已经出现了重复的数据,那么究竟是什么造成了唯一索引的失效呢?
二、原因分析
就是因为我们插入的数据中 age 为 Null 导致的。在 MySQL 官方文档中也有说明,Null 与任何值都不相等,包括与另一个 Null 比较。
MySQL 关于Null 描述地址:https://dev.mysql.com/doc/refman/8.4/en/problems-with-null.html
所以结论就是:当多个字段一起创建唯一索引时,需要设置每一项字段非空,如果其中一项出现 Null 值,MySQL 的唯一索引会失效。
三、逻辑删除
说到唯一索引,就要想到有逻辑删除这个东西,对于现在的系统来说,10个系统里面8个是用逻辑删除。
对于系统中记录的删除,一般是两种,一种是物理删除,也就是使用delete语句进行删除。另一种就是使用逻辑删除,在表中增加一个删除标记字段,比如deleted,默认0,当需要删除时改为1。
通过物理删除的数据,在表中是查询不出来的,不过可以通过 binlog 进行恢复,如果你感兴趣,欢迎评论区留言,下一篇咱就讲一下如何还原数据。
通过逻辑删除的数据,在表中还是存在的,只是删除标记deleted变成了1。
我们还拿上面那张表举例,假如我们删除了张三、18、北京这条记录,如果后面再次插入张三、18、北京这条数据是无法插入的,因为我们创建的唯一索引是name、`age、city三个字段。
那么这种情况我们可以怎么解决呢?
有的同学可能就会说了,在上面name、`age、city唯一索引的基础上,增加deleted,创建4个字段的唯一索引不就行了。
那么真的可以吗?
还是那句话,用上面的表举个栗子:
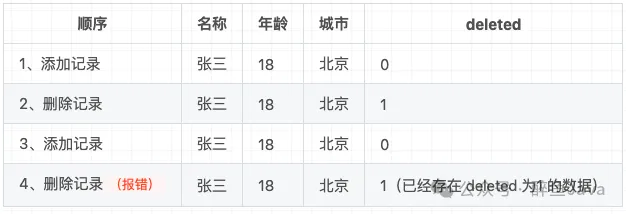
下面跟我一起来看下如何解决?
四、删除状态加1
第一种方式就是删除状态加1,现在我们表中deleted默认0,如果删除了之后就是1,那么我们更改为,deleted默认0,删除之后获取当前相同记录的最大删除状态,然后加1。
举个栗子:
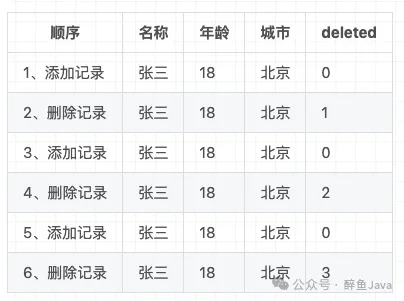
通过上面的例子可以看出来,每次删除记录,当前记录的删除标记deleted都会获取当前相同记录的最大删除状态,然后加1进行删除。
这样deleted 每次删除的时候都是不一样的,所以可以保证唯一索引的生效。
使用这种方案的缺点就是需要修改代码中的sql逻辑,比如查询deleted为1的删除数据时需要改为deleted>1。
五、增加时间戳
除了上面这种对删除状态进行加1的方式外,还可以增加一个时间戳字段,创建name、`age、city、timestamp四个字段的联合唯一索引。
时间戳一般精确到秒,如果并发高,还是可能生成重复数据,那么时间戳的话可以精确到毫秒。
然后设置时间戳字段默认值为1,当进行逻辑删除删除时,直接插入当前时间的时间戳。
这种方案的优点就是不用修改原来代码逻辑,缺点就是极限情况下还是可能会产生重复数据。
六、增加删除ID
我们还可以使用增加删除ID的方法来进行去重。
创建唯一索引name、`age、city、deleted_id。
插入数据时deleted_id默认1,当进行逻辑删除时修改为当前记录的主键ID。
这种方法与增加时间戳字段类似,优点就是可以解决时间戳字段的重复数据问题,并且无需修改现有系统的删除逻辑,也可以保证数据的唯一,所以如果再有逻辑删除的表中,推荐使用这种方式。
七、历史数据加唯一索引
在上面的几个方案中,都是对新表添加的唯一索引,现在有一张历史数据表,其中还有重复数据,那么我们该如何添加索引呢?
我们使用deleted_id的方案,首先获取出相同记录的最大ID,然后将这些记录的deleted_id设置为1,然后其他的记录deleted_id就是当前记录的主键,这样我们就可以区分表中的重复数据了。
当表中的deleted_id都有值之后,创建唯一索引name、`age、city、deleted_id。
八、大字段添加唯一索引
创建索引的要求大家应该都知道,字段不可以太大,因为索引本身大了之后检索的效率也是很低的。
关于MySQL 中 InnoDB 引擎的限制可以查看这个链接:https://dev.mysql.com/doc/refman/8.4/en/innodb-limits.html
对于大的字段添加唯一索引,可以使用hash算法,创建一个hash字段,将大字段进行Hash运算之后的结果保存到 hash 中,然后创建唯一索引name、age、city、hash。
用到Hash算法,肯定就会有Hash冲突,所以这种方案会带来一个问题就是不同的值Hash却相同。
所以创建多列的联合唯一索引时需要在增加一个其他的字段进行区分。
还有一种方案就是不使用唯一索引,使用唯一索引的目的就是去重,直接代码层面MQ、单线程处理等。

总结
本文通过还原唯一索引失效的场景,得出当多列唯一索引中的某一列有为Null的值时,唯一索引会失效。
总结出在有逻辑删除的业务表中,可以通过删除状态值加1、增加时间戳字段、增加删除ID字段三种方式进行添加多列唯一索引。
最后还给出了如何对历史重复数据添加唯一索引以及使用hash给大字段添加唯一索引的方式。