什么是模型量化?
模型量化是一种模型压缩技术,其核心思想是将原本使用浮点数表示的模型参数转换为整数表示,以此来减少模型的存储空间需求并加速计算过程。
具体来说,量化可以将原本使用float32类型的数据转换为int8类型的数据,这意味着每个权重值占用的空间从32位减少到8位,不仅减少了模型的大小,也降低了计算所需的带宽和计算资源。

为什么需要进行量化?
随着深度学习技术在多个领域(如CV、NLP、语音等)的快速应用,模型的规模越来越大,复杂度也越来越高。这导致了模型在内存占用、计算资源以及能耗方面的需求也随之增加。如需将这些复杂的模型部署在一些低成本的手机、平板等嵌入式设备中,往往难以满足。
「模型量化应运而生,它可以在损失少量精度的前提下对模型进行压缩,使得原本只能在高性能服务器或GPU上运行的大模型能够在资源受限的嵌入式设备上运行。」
模型量化分类
根据映射函数是否是线性可以分为两类——即线性量化和非线性量化,本文主要研究的是线性量化技术。
1.线性量化
线性量化的过程可以用以下数学表达式来表示:

其中,
- q表示原始的浮点数值(通常是Float32)。
- Z表示浮点数值的偏移量(通常称为 Zero Point)。
- S表示浮点数值的缩放因子(通常称为Scale)。
- Round(⋅)表示四舍五入近似取整的数学函数,也可以使用向上或向下取整。
根据参数Z是否为零可以将线性量化分为两类——即对称量化和非对称量化。
「对称量化」

对称量化,即使用一个映射公式将输入浮点数据映射到[-128,127]的范围内,图中-max(|Xf|)表示的是输入数据的最小值,max(|Xf|)表示输入数据的最大值。
对称量化的一个核心即零点的处理,映射公式需要保证原始零点(即输入浮点数中的0)在量化后依然对应于整数区间的0。总而言之,对称量化通过映射关系将输入数据映射在[-128,127]的范围内,对于映射关系而言,我们需要求解的参数即Z和S。
在对称量化中,r是用有符号的整型数值(int8)来表示的,此时Z=0,且q=0时恰好有r=0。S的计算公式如下:

其中:
- n表示用来表示该数值的位宽。
- max(|x|)表示数据集中所有样本的绝对值的最大值。
「非对称量化」
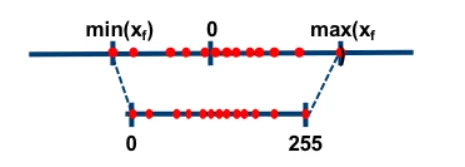
非对称量化,即使用一个映射公式将输入数据映射到[0,255]的范围内,图中min(Xf)表示的是输入数据的最小值,max(Xf)表示输入数据的最大值。
对称量化通过映射关系将输入数据映射在[0,255]的范围内,对于映射关系而言,我们需要求解的参数即Z和S。
在非对称量化中,r 是用有符号的整型数值(uint8)来表示的。可以取Z=min(x),S的计算公式如下:

2.逐层量化、逐组量化和逐通道量化
根据量化的粒度(即共享量化参数的范围),可以将量化方法分为逐层量化、逐组量化和逐通道量化。
- 逐层量化:以一个层为单位,整个层的所有权重上使用相同的缩放因子 S 和偏移量 Z 。
- 逐组量化:将权重按组划分,每个group使用一组S和Z。
- 逐通道量化:以通道为单位,每个channel单独使用一组S和Z。
当 group=1 时,逐组量化与逐层量化等价;当group=num_filters (即dw卷积)时,逐组量化逐通道量化等价。
3.在线量化与离线量化
根据激活值的量化方式,可以分为在线量化和离线量化两种方法。这两种方法的主要区别在于量化参数(缩放因子S和偏移量Z)是否在实际推理过程中动态计算。
- 在线量化:指在实际推理过程中,根据实际的激活值动态计算量化参数S和Z。
- 离线量化:离线量化是指提前确定好激活值的量化参数S和Z。这样,在实际推理时就可以直接使用这些预计算好的参数,而不需要动态计算,从而提高了推理速度。
离线量化通常采用以下几种方法来确定量化参数:
- 指数平滑法:将校准数据集送入模型,收集每个量化层的输出特征图,计算每个batch的S和Z值,并通过指数平滑法来更新S和Z值。
- 直方图截断法:在计算量化参数S和Z的过程中,考虑到有些特征图可能会出现偏离较远的奇异值,导致最大值非常大。可以采用直方图截取的形式,比如抛弃最大的前 1% 数据,以前 1% 分界点的数值作为最大值来计算量化参数。
- KL 散度校准法:通过计算量化前后的两个分布之间的 KL 散度(也称为相对熵)来评估这两个分布之间的差异,以搜索并选取KL散度最小的量化参数Z和S作为最终的结果。
4.比特量化
根据存储一个权重元素所需的位数,可以将其分为8bit量化、4bit量化、2bit量化和1bit量化。
- 二进制神经网络:即在运行时具有二进制权重和激活的神经网络,以及在训练时计算参数的梯度。
- 三元权重网络:即权重约束为+1,0和-1的神经网络。
- XNOR网络:即过滤器和卷积层的输入是二进制的。XNOR网络主要使用二进制运算来近似卷积。
模型量化原理详解
1.原理详解
模型量化桥接定点和浮点,建立一种有效的数据映射关系。要弄懂模型量化的原理就要弄懂这种数据映射关系。浮点与定点数据的转换公式如下:

其中:
- R表示输入的浮点数据
- Q表示量化之后的定点数据
- Z表示零点(Zero Point)的数值
- S表示缩放因子(Scale)的数值
根据S和Z这两个参数来确定这个映射关系。求解 S 和 Z 有很多种方法,这里列举中其中的一种求解方式(MinMax)如下:

其中,
- max(R)表示输入浮点数值的最大值。
- min(R)表示输入浮点数值的最小值。
- max(Q)表示量化之后的整数数值的最大值(127/255)。
- min(Q)表示量化之后的整数数值的最小值(-128/0)。
每通道或每张量的权重用int8进行定点量化的可表示范围为[-127,127],且zero-point就是量化值0。
每张量的激活值或输入值用int8进行定点量化的可表示范围为[-128,127],其zero-point在[-128,127]内依据公式求得。
2.具体案例
在这个案例中,我们将展示如何根据给定的激活值范围 [-2.0, 6.0] 使用 int8 类型进行定点量化的过程。
步骤1: 计算量化尺度S和zero-point Z。
量化尺度S的计算公式为:

Zero-point Z的计算公式为:
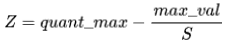
代入给定的值:
- 激活值范围 [-2.0, 6.0],因此 max_val = 6.0 和 min_val = -2.0
- 定点量化值范围 [-128, 127],因此 quant_max = 127 和 quant_min = -128
计算得到:

步骤 2: 对激活值进行量化。
使用计算出的 S 和 Z 值对一个具体的激活值进行量化。假设有一个真实的激活值R = 0.28,则量化后的值 Q为:

代入S和Z的值:

模型量化实现步骤
模型量化具体的执行步骤如下所示:
- 在量化前,需要先统计出输入数据(通常是权重或者激活值)中的最小值 min_value 和最大值 max_value。
- 根据模型的需求选择合适的量化类型,常见的有对称量化(int8)和非对称量化(uint8)。
- 根据选择的量化类型,计算量化参数 Z(Zero point)和 S(Scale)。
- 根据计算出的量化参数 Z 和 S,对模型执行量化操作,即将 FP32 数据转换为 INT8 数据。
- 验证量化后的模型性能是否满足要求。如果不满足,可以尝试使用不同的方式计算 S 和 Z,然后重新执行量化操作。
Pytorch模型量化详解
PyTorch提供了三种量化模型的方法,具体包括训练后动态量化、训练后静态量化和训练时量化。
1.训练后动态量化
训练后动态量化(Post Training Dynamic Quantization,PTDQ)是最简单的量化形式,其中权重被提前量化,而激活在推理过程中被动态量化。这种方法用于模型执行时间由从内存加载权重而不是计算矩阵乘法所支配的情况,适合批量较小的LSTM和Transformer模型。步骤如下:
- 准备模型:将模型设置为评估模式 (model.eval()),对于需要动态量化的模型,通常不需要添加额外的量化或反量化模块。
- 量化模型:使用 torch.quantization.quantize_dynamic() 函数来量化模型,这个函数会自动识别模型中适合动态量化的层,并将其转换为量化版本。
2.训练后静态量化
训练后静态量化(Post-Training Static Quantization, PTQ)是最常用的量化形式,其中权重是提前量化的,并且基于在校准过程中观察模型的行为来预先计算激活张量的比例因子和偏差。CNN是一个典型的用例,训练后量化通常是在内存带宽和计算节省都很重要的情况下进行的。训练后量化的步骤如下:
- 准备模型:添加 QuantStub 和 DeQuantStub 模块,以指定在何处显式量化和反量化激活值。确保不重复使用模块。将需要重新量化的任何操作转换为模块的模式。
- 融合操作:将诸如 conv + relu 或 conv + batchnorm + relu 之类的组合操作融合在一起,以提高模型的准确性和性能。
- 指定量化配置:例如选择对称或非对称量化以及MinMax或L2Norm校准技术。
- 使用 torch.quantization.prepare() 函数来插入观察模块,以便在校准期间观察激活张量。
- 使用校准数据集对模型执行校准操作。
- 使用 torch.quantization.convert() 函数来转换模型。包括计算并存储每个激活张量要使用的比例和偏差值,并替换关键算子的量化实现。
3.训练时量化
在某些情况下,训练后量化不能提供足够的准确性,这时可以使用训练时量化(Quantization-Aware Training,QAT)。步骤:
- 准备模型:添加 QuantStub 和 DeQuantStub 模块,以指定在何处显式量化和反量化激活值。确保不重复使用模块。将需要重新量化的任何操作转换为模块的模式。
- 将诸如 conv + relu 或 conv + batchnorm + relu 之类的组合操作融合在一起,以提高模型的准确性和性能。
- 指定伪量化配置:例如选择对称或非对称量化以及MinMax或L2Norm校准技术.
- 用 torch.quantization.prepare_qat() 函数来插入伪量化模块,以便在训练过程中模拟量化。
- 使用标准训练流程训练或微调模型。
- 使用 torch.quantization.convert() 函数来转换模型,包括计算并存储每个激活张量要使用的比例和偏差值,并替换关键算子的量化实现。
「示例代码」
下面是一个简单的示例,展示了如何使用PyTorch进行模型量化。
# 导入第三方的库函数
import os
from io import open
import time
import torch
import torch.nn as nn
import torch.quantization
import torch.nn.functional as F
# 创建LSTM模型类
class LSTMModel(nn.Module):
"""整个网络包含一个encoder, 一个recurrent模块和一个decoder."""
def __init__(self, ntoken, ninp, nhid, nlayers, dropout=0.5):
super(LSTMModel, self).__init__()
# 预定义一些网络层
self.drop = nn.Dropout(dropout)
# 嵌入层
self.encoder = nn.Embedding(ntoken, ninp)
# LSTM层
self.rnn = nn.LSTM(ninp, nhid, nlayers, dropout=dropout)
# 线性层
self.decoder = nn.Linear(nhid, ntoken)
self.init_weights()
self.nhid = nhid
self.nlayers = nlayers
def init_weights(self):
'''
初始化模型权重
'''
initrange = 0.1
self.encoder.weight.data.uniform_(-initrange, initrange)
self.decoder.bias.data.zero_()
self.decoder.weight.data.uniform_(-initrange, initrange)
def forward(self, input, hidden):
'''
搭建网络并执行前向推理
'''
emb = self.drop(self.encoder(input))
output, hidden = self.rnn(emb, hidden)
output = self.drop(output)
decoded = self.decoder(output)
return decoded, hidden
def init_hidden(self, bsz):
'''
初始化hidden层的权重
'''
weight = next(self.parameters())
return (weight.new_zeros(self.nlayers, bsz, self.nhid),
weight.new_zeros(self.nlayers, bsz, self.nhid))
# 创建一个词典类,用来处理数据
# 构建词汇表,包括词到索引的映射和索引到词的映射
class Dictionary(object):
def __init__(self):
self.word2idx = {}
self.idx2word = []
def add_word(self, word):
'''
在词典中添加新的word
'''
if word not in self.word2idx:
self.idx2word.append(word)
self.word2idx[word] = len(self.idx2word) - 1
return self.word2idx[word]
def __len__(self):
'''
返回词典的长度
'''
return len(self.idx2word)
# Corpus 类:处理文本数据,包括读取文件、构建词汇表和将文本转换为索引序列
class Corpus(object):
def __init__(self, path):
self.dictionary = Dictionary()
# 分别获取训练集、验证集和测试集
self.train = self.tokenize(os.path.join(path, 'train.txt'))
self.valid = self.tokenize(os.path.join(path, 'valid.txt'))
self.test = self.tokenize(os.path.join(path, 'test.txt'))
def tokenize(self, path):
"""对输入的文件执行分词操作"""
assert os.path.exists(path)
# 将新的单词添加到词典中
with open(path, 'r', encoding="utf8") as f:
for line in f:
words = line.split() + ['<eos>']
for word in words:
self.dictionary.add_word(word)
# 标记文件的内容
with open(path, 'r', encoding="utf8") as f:
idss = []
for line in f:
words = line.split() + ['<eos>']
ids = []
for word in words:
ids.append(self.dictionary.word2idx[word])
idss.append(torch.tensor(ids).type(torch.int64))
ids = torch.cat(idss)
return ids
# 设置模型的路径
model_data_filepath = 'data/'
corpus = Corpus(model_data_filepath + 'wikitext-2')
ntokens = len(corpus.dictionary)
# 搭建网络模型
model = LSTMModel(
ntoken = ntokens,
ninp = 512,
nhid = 256,
nlayers = 5,
)
# 加载预训练的模型权重
model.load_state_dict(
torch.load(
model_data_filepath + 'word_language_model_quantize.pth',
map_location=torch.device('cpu')
)
)
# 将模型切换为推理模式,并打印整个模型
model.eval()
print(model)
# 获取一个随机的输入数值
input_ = torch.randint(ntokens, (1, 1), dtype=torch.long)
hidden = model.init_hidden(1)
temperature = 1.0
num_words = 1000
# 遍历数据集进行前向推理并将结果保存起来
with open(model_data_filepath + 'out.txt', 'w') as outf:
with torch.no_grad(): # no tracking history
for i in range(num_words):
output, hidden = model(input_, hidden)
word_weights = output.squeeze().div(temperature).exp().cpu()
word_idx = torch.multinomial(word_weights, 1)[0]
input_.fill_(word_idx)
word = corpus.dictionary.idx2word[word_idx]
outf.write(str(word.encode('utf-8')) + ('\n' if i % 20 == 19 else ' '))
if i % 100 == 0:
print('| Generated {}/{} words'.format(i, 1000))
with open(model_data_filepath + 'out.txt', 'r') as outf:
all_output = outf.read()
print(all_output)
bptt = 25
criterion = nn.CrossEntropyLoss()
eval_batch_size = 1
# 创建测试数据集
def batchify(data, bsz):
# 对测试数据集进行分块
nbatch = data.size(0) // bsz
# 去掉多余的元素
data = data.narrow(0, 0, nbatch * bsz)
# 在bsz批处理中平均划分数据
return data.view(bsz, -1).t().contiguous()
test_data = batchify(corpus.test, eval_batch_size)
# 获取bath块的输入数据
def get_batch(source, i):
seq_len = min(bptt, len(source) - 1 - i)
data = source[i:i+seq_len]
target = source[i+1:i+1+seq_len].view(-1)
return data, target
def repackage_hidden(h):
"""
用新的张量把隐藏的状态包装起来,把它们从历史中分离出来
"""
if isinstance(h, torch.Tensor):
return h.detach()
else:
return tuple(repackage_hidden(v) for v in h)
# 评估函数
def evaluate(model_, data_source):
# 打开评估模式
model_.eval()
total_loss = 0.
hidden = model_.init_hidden(eval_batch_size)
with torch.no_grad():
for i in range(0, data_source.size(0) - 1, bptt):
# 获取测试数据
data, targets = get_batch(data_source, i)
# 执行前向推理
output, hidden = model_(data, hidden)
hidden = repackage_hidden(hidden)
output_flat = output.view(-1, ntokens)
# 获取训练loss
total_loss += len(data) * criterion(output_flat, targets).item()
return total_loss / (len(data_source) - 1)
# 初始化动态量化模块
quantized_model = torch.quantization.quantize_dynamic(
model, {nn.LSTM, nn.Linear}, dtype=torch.qint8
)
print(quantized_model)
def print_size_of_model(model):
torch.save(model.state_dict(), "temp.p")
print('Size (MB):', os.path.getsize("temp.p")/1e6)
os.remove('temp.p')
print_size_of_model(model)
print_size_of_model(quantized_model)
torch.set_num_threads(1)
# 评估模型的运行时间
def time_model_evaluation(model, test_data):
s = time.time()
loss = evaluate(model, test_data)
elapsed = time.time() - s
print('''loss: {0:.3f}\nelapsed time (seconds): {1:.1f}'''.format(loss, elapsed))
time_model_evaluation(model, test_data)
time_model_evaluation(quantized_model, test_data)