Python 是初学者易于学习的一门语言,并且提供了大量的第三方库。超过230,000个用户贡献的包使得Python功能强大且广受欢迎。在本文中,我重点介绍了15个最有用的包,详细说明了它们的功能和特性。

Dash

Dash 是一个相对新的包,非常适合使用纯 Python 构建数据可视化应用程序。它对于任何处理数据的人都非常适合。Dash 结合了 Flask、Plotly.js 和 React.js。
Pygame
Pygame 是 SDL 多媒体库的 Python 包装器,这是一个跨平台的开发库,提供低级别的访问权限:
- 音频
- 键盘
- 鼠标
使用 OpenGL 和 Direct3D 的游戏手柄和图形硬件 Pygame 高度便携,几乎可以在每个平台和操作系统上运行。除了它全面的游戏引擎外,你还可以使用这个库直接从 Python 脚本播放 MP3 文件。
Pillow
Pillow 专门用于图像处理。你可以创建缩略图,转换文件格式,旋转,应用过滤器,显示图像等等。非常适合批量处理多张图片。这里有一个快速示例来加载和渲染一张图片:
from PIL import Image
im = Image.open("kittens.jpg")
im.show()
print(im.format, im.size, im.mode)
# 输出: JPEG (1920, 1357) RGBColorama
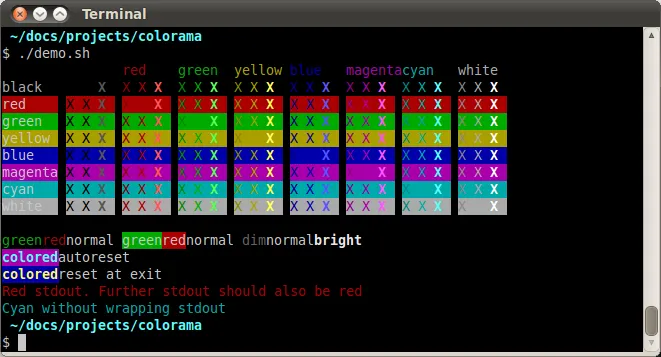
Colorama 允许你在终端中使用颜色。它非常适合 Python 脚本,文档简洁有趣,可在 Colorama PyPI 页面上找到。
JmesPath
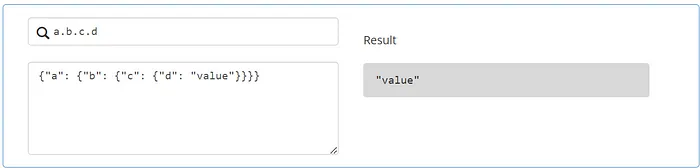
由于 Python 字典的出色映射,Python 中使用 JSON 变得简单。Python 的内置 json 库非常适合解析和创建 JSON。JMESPath 使得 Python 中处理 JSON 更加容易,允许你清晰地指定如何从 JSON 文档中提取元素。以下是一些基本示例:
import jmespath
# 获取特定元素
d ={"foo": {"bar": "baz"}}
print(jmespath.search('foo.bar', d))
# 输出: baz
# 使用通配符获取所有名称
d ={"foo": {"bar": [{"name": "one"}, {"name": "two"}]}}
print(jmespath.search('foo.bar[*].name', d))
# 输出: ["one", "two"]Requests
Requests 建立在 urllib3 库之上,使 web 请求变得简单、强大且多功能。这里有一个快速示例,展示了 Requests 的易用性。
import requests
r = requests.get('https://api.github.com/user', auth=('user', 'pass'))
r.status_code
# 200
r.headers['content-type']
# 'application/json; charset=utf8'
r.encoding
# 'utf-8'
r.text
# u'{"type":"User"...'
r.json()Requests 可以处理高级任务,例如:
- 认证
- Cookies
- POST, PUT, DELETE 请求
- 自定义证书
- 会话
- 代理
Simplejson
Python 的内置 json 模块没有问题!实际上,Python 的 json 是基于 simplejson 的。
try:
import simplejson as json
except ImportError:
import jsonSimplejson 有一些优势:
- 适用于更多 Python 版本。
- 更新频率比 Python 内置版本更频繁。
- 有可选的 C 部分以提高速度。
除非你需要:
- 速度
- 标准库中没有的功能
Simplejson 因为实现了一些关键部分的 C 语言,所以速度快得多。然而,这种速度优势只有在处理数百万 JSON 文件时才会显现。
Emoji

Emoji 库对于涉及 emoji 的媒体数据分析来说既有趣又有用。这里有一个简单的示例:
import emoji
result = emoji.emojize('Python is :thumbs_up:')
print(result)
# 'Python is 👍'
# 也可以反向操作:
result = emoji.demojize('Python is 👍')
print(result)
# 'Python is :thumbs_up:'Chardet
Chardet 可以检测文件或数据流的字符集,在分析大量随机文本时非常有用。它在处理远程数据下载时,当字符集未知时也非常有用。
Python-dateutil
Python-dateutil 强大地扩展了标准 datetime 模块。当常规 Python datetime 功能结束时,python-dateutil 就开始发挥作用。你可以用这个库做很多很棒的事情。以下是我发现特别有用的示例:在日志文件中模糊解析日期:
from dateutil.parser import parse
logline ='INFO 2020-01-01T00:00:01 Happy new year, human.'
timestamp = parse(logline, fuzzy=True)
print(timestamp)
# 2020-01-01 00:00:01有关更多特性,请查看完整文档:
- 计算相对差异(下个月,明年,下周一,月份的最后一周)以及两个给定日期对象之间的相对差异。
- 使用 iCalendar 标准超集的根据复发规则计算日期。
- 基于 tzfile 文件、TZ 环境字符串、iCalendar 格式文件、给定范围、本地时区、固定偏移时区、UTC 和基于 Windows 注册表的时区的时区(tzinfo)实现。
- 基于 Olson 数据库的最新世界时区信息。
- 使用西方、东正教或朱利安算法计算任何给定年份的复活节星期日。
进度条:progress 和 tqdm
这有点作弊,因为这是两个包,但忽略任何一个都是不公平的。创建自己的进度条可能很有趣,但使用 progress 或 tqdm 包更快且更少出错。使用 progress,你可以轻松创建进度条。
from progress.bar import Bar
bar = Bar('Processing', max=20)
for i inrange(20):
# 做一些工作
bar.next()
bar.finish()
Tqdm 提供了类似的功能,看起来更新更频繁。以下是一些开始的 gif 演示:

IPython
你可能知道 Python 的交互式 shell,这是运行 Python 的一种很好的方式。但你知道 IPython shell 吗?如果你经常使用交互式 shell 但还没有尝试过 IPython,你应该去看看!IPython 的一些增强功能包括:
- 综合的对象内省。
- 输入历史记录,在会话之间持久。
- 在会话期间输出结果缓存并自动引用。
- 标签补全 Python 变量、关键字、文件名和函数关键字。
- 控制环境和执行与 IPython 或 OS 相关的许多任务的“魔法”命令。
- 会话日志记录和重新加载。
- 集成访问 pdb 调试器和 Python 分析器。
- 一个鲜为人知的特性:IPython 的架构还允许并行和分布式计算。
IPython 是 Jupyter Notebook 的核心,Jupyter Notebook 是一个开源的 web 应用程序,用于创建和共享带有实时代码、方程、可视化和叙述文本的文档。
Home Assistant
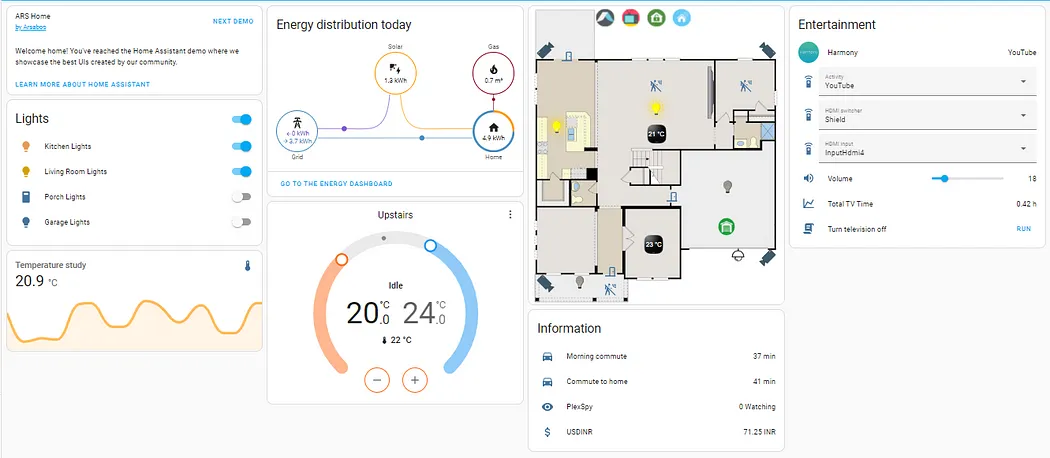
我使用 Home Assistant 将我们房子里的所有系统集成在一起:
- 它是一个完整的应用程序,但你也可以将其作为 Python PyPI 包安装。
- 我们的大部分灯和百叶窗都是自动化的。
- 我监控我们的燃气使用、电力消耗和生产(太阳能电池板)。
- 我可以追踪大多数手机的位置,并在进入某个区域时触发动作,比如当我到家时打开车库灯。
- 它控制了我们所有的娱乐系统,如三星电视和 Sonos 扬声器。
- 它可以自动发现网络上的大多数设备,使设置变得容易。
- 我已经连续三年每天使用 Home Assistant。它仍在测试中,但这是我尝试过的最好的平台。
- 它集成和控制各种设备和协议,全部免费且开源。
Flask

Flask 是我创建快速 web 服务或简单网站的 go-to 库。它是一个微框架,意味着 Flask 旨在保持核心简单但可扩展。有超过 700 个官方和社区扩展。如果你知道自己将开发一个大型 web 应用程序,你可能想看看一个更全面的框架。这一类中最受欢迎的是 Django。
BeautifulSoup
从网站提取 HTML 时,你需要解析它以获取你想要的内容。Beautiful Soup 是一个 Python 库,用于从 HTML 和 XML 文件中提取数据。它提供了简单的方法来导航、搜索和修改解析树。它非常强大,可以处理各种 HTML,即使是损坏的 HTML。一些关键特性如下:
- Beautiful Soup 自动将传入的文档转换为 Unicode,将传出的文档转换为 UTF-8。你不需要担心编码问题。
- Beautiful Soup 位于流行的 Python 解析器之上,如 XML 和 html5lib,给你尝试不同解析策略的灵活性。
- Beautiful Soup 会解析你提供的任何内容,并为你完成树遍历工作。你可以告诉它“找到所有的链接”或者“找到加粗的表格