














译者 | 李睿
审校 | 重楼
Meta公司发布的对象分割模型SAM 2可以执行实时图像和视频分割,并且可以应用于许多领域,而无需对特定数据进行微调。
Meta公司日前发布了其新的Segment Anything Model 2 (SAM 2),由于目前人们主要关注的是大型语言模型(LLM),因此并没有得到应有的关注。SAM 2可以进行实时图像和视频分割,并且可以应用于许多领域,而无需对特定数据进行微调。

图1使用Meta的SAM 2模型进行对象分割
Meta公司已经发布了模型权重、代码和用于训练它的数据集,这将对研究和开发社区非常有用。以下是SAM 2的工作原理及其对许多工业应用程序(包括未来几代LLM)可能产生的影响。
从SAM到SAM 2
对象分割是一项复杂的任务,需要识别图像中属于对象的所有像素。传统上,创建对象分割模型是一项非常复杂的任务,需要专业技术知识、目标应用程序的大量注释数据以及成本昂贵的机器学习训练基础设施。
Meta公司于2023年发布的SAM改变了这一现状,它提提供了一种可以开箱即用的模型来处理许多用例。SAM可以接受“提示”,提示可以包括点、边界框或文本,并检测哪些像素属于与提示对应的对象。这相当于LLM的对象分割,它可以在不进行再训练的情况下完成许多任务。
SAM的工作原理是学习匹配输入图像的编码,并为每个对象提示转换为彩色像素。该模型在SA-1B上进行训练,SA-1B是一个包含10亿张注释图像的数据集。关于数据注释过程的一个有趣的事实是,研究人员使用了一个迭代过程。
他们首先在一组带注释的示例上训练了初始版本的SAM。然后,使用该模型来帮助注释者加快下一组示例的注释过程。他们利用新的数据对SAM进行微调,提高其性能,并以更快的速度重复这个循环。
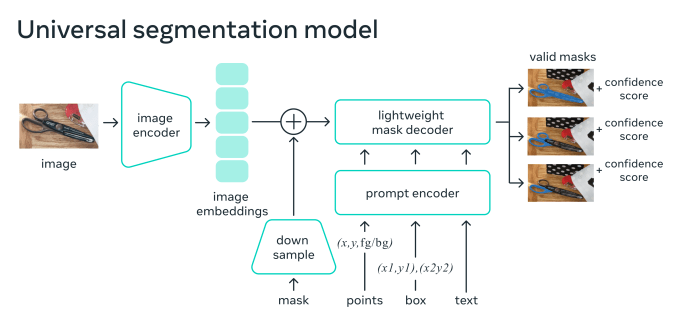
图2 SAM架构
SAM已经被用于各种用途,从Instagram等消费者应用程序到科学和医学应用程序。SAM也成为图像标记过程的重要组成部分,帮助机器学习团队加快为其专业分割模型创建训练示例的过程。
SAM 2通过添加一些组件来改进SAM,使其更适合检测视频中的同一对象。视频中对象分割的挑战在于对象可能会变形、遮挡或在不同帧中从不同角度显示。SAM 2添加了内存组件,使模型能够确保跨帧的一致性。
记忆机制由记忆编码器、记忆库和记忆注意力模块组成。当应用于静止图像时,内存组件是空的,模型的行为类似于SAM。当模型用于视频时,内存组件存储有关对象和用户先前提示的信息。用户可以在视频的不同部分添加或删除提示,以改进模型的输出。在每一帧中,记忆信息都会根据前一帧的信息来调整模型的预测。

图3 Meta SAM 2架构
SAM 2还附带了SA-V,这是一个全新的数据集,具有更大、更丰富的训练示例集。SA-V在大约51,000个视频中包含60多万个注释图像。这些视频展示了从全球47个国家收集的真实场景。注释包括整个对象、对象部分以及具有挑战性的场景,例如对象部分被遮挡的实例。
与其前身一样,SA-V在模型本身的帮助下进行了注释。注释者使用SAM 2的早期版本来注释示例,然后人工纠正注释并重新训练模型。通过重复这个过程,他们改进了模型,提高了自动注释的速度和质量。
Meta公司表示,“使用我们的工具和循环中的SAM 2的注释大约比每帧使用SAM快8.4倍,也比将SAM与现成的跟踪器结合起来快得多。”
SAM – 2的实际应用
根据Meta公司研究团队发布的报告,在17个零样本视频数据集上,SAM 2在交互式视频分割方面明显优于以前的方法,并且需要的人机交互减少了大约三倍。SAM 2还提供每秒约44帧的近实时推理。
研究人员已经根据Apache 2.0许可证提供了SAM 2的代码和权重,这意味着用户可以免费将其用于商业目的。他们还发布了SA-V数据集。此举是Meta公司最近推动将其人工智能研究、模型和工具开源的一部分,以应对OpenAI、Anthropic和谷歌等公司的封闭发布。
很多开发人员和研究人员将这种模型重新用于专门的用例。该模型已经非常高效,有39兆字节到224兆字节四种大小,足以在笔记本电脑和智能手机等许多边缘设备上运行。但是,通用模型将在非常专业的应用程序或内存和计算受限的设备上遇到障碍。SAM 2和SA-V将如何帮助企业为特定工厂生产线上的对象检测等专门应用创建微小对象分割模型令人感兴趣。它对自动驾驶行业也非常有用,因为自动驾驶行业需要大量的注释数据,而注释速度的任何百分比的提高都是明显的胜利。
同样有趣的是,如何将SAM 2等模型与语言模型相结合以用于更复杂的应用程序。目前,大多数视觉语言模型(VLM)都是用于处理原始像素数据和文本。而了解可以用基于对象分割模型输出或原始像素和粒度对象分割组合的VLM来实现什么,这将是一件有趣的事情。这可能对机器人技术尤其有用,因为视觉语言模型(VLM)和更新的视觉-语言-行动(VLA)模型正在这一领域取得进展。
至于Meta公司,可以期待SAM 2、Llama 3和下一代人工智能创新将在该公司一些最雄心勃勃的项目中找到自己的方式,包括增强现实眼镜。
原文标题:Meta SAM 2 is the most impressive object segmentation model,作者:Ben Dickson























