













今天给大家分享常见的 7 种权重初始化方法
初始化深度学习模型的权重是影响模型训练速度、稳定性以及最终性能的重要因素。
以下是常见的 7 种权重初始化方法,每种方法都有其适用的场景和特性。
1. 零初始化(Zero Initialization)
将所有权重初始化为零。这是最简单的初始化方法,但通常不适用于深度神经网络。
优点
实现简单,易于理解。
缺点
这种初始化方法的问题在于,会导致所有的神经元在每一层都学习到相同的特征。
因为对于对称的权重,反向传播更新时会导致相同的梯度,这使得所有的神经元在训练过程中没有差异化,从而丧失了模型的学习能力。
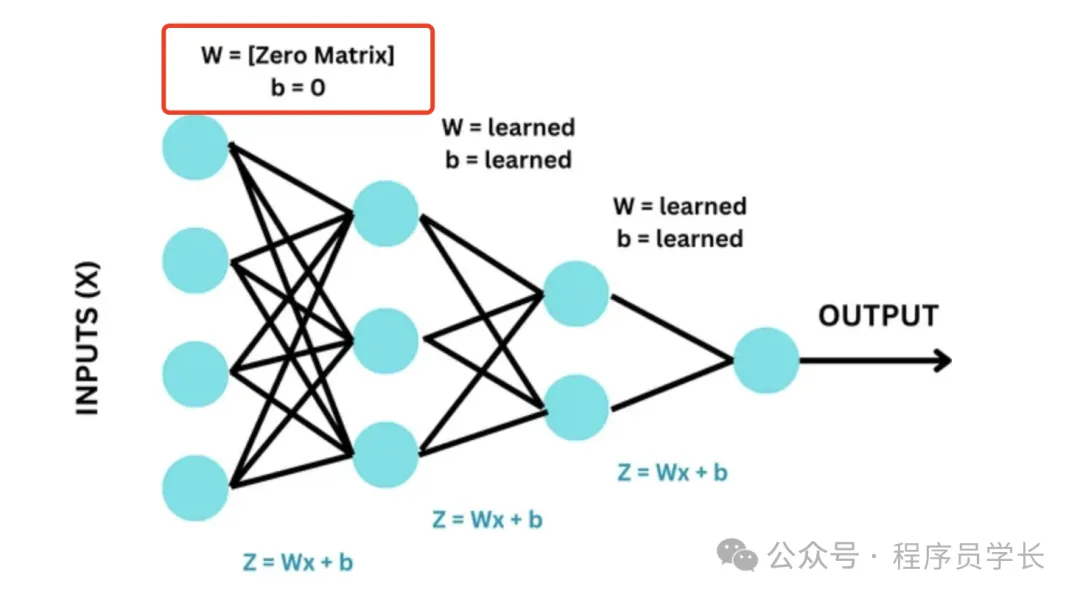
2.随机初始化(Random Initialization)
权重随机初始化为一个较小的随机数。通常,这些随机数从均匀分布或正态分布中采样。
优点:
可以打破对称性,避免零初始化带来的问题。
缺点:
需要小心选择随机数的范围,太大可能导致梯度爆炸,太小则可能导致梯度消失。
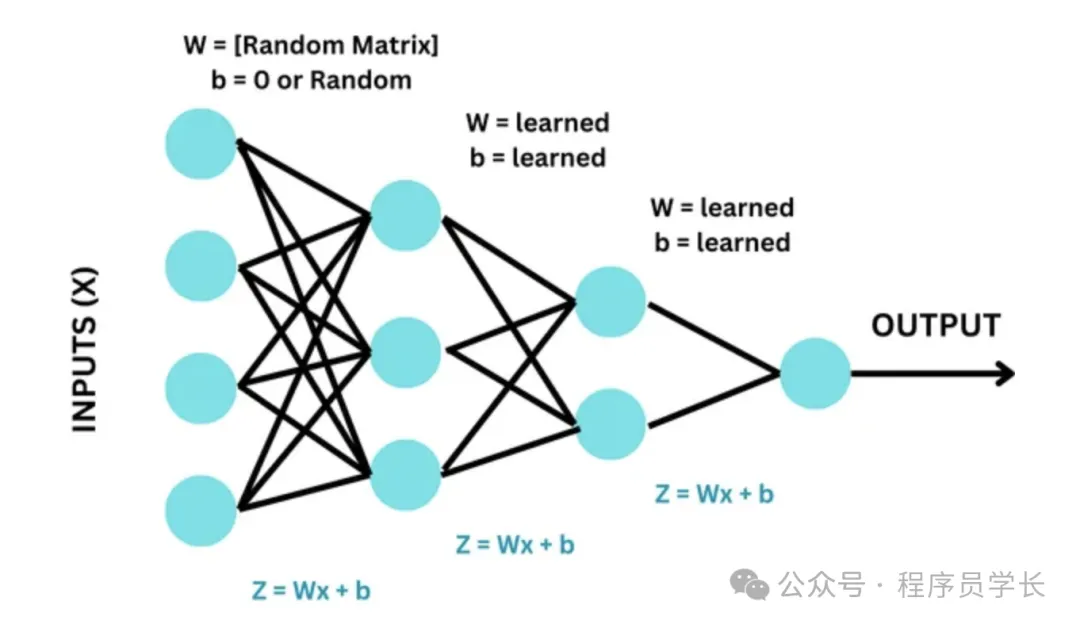
3.Xavier 初始化(Xavier Initialization)
Xavier 初始化方法根据输入和输出的节点数来选择权重的初始值范围,使得网络中每一层的输入和输出的方差保持一致,避免梯度爆炸或消失。
公式
- 若使用均匀分布:
- 若使用正态分布:
优点
- 在深层网络中,Xavier 初始化可以平衡前向和反向传播中的信号,从而加速收敛。
- 适用于Sigmoid 和 tanh激活函数的网络。
缺点
对于激活函数是ReLU的网络,Xavier 初始化可能不够有效。
4.He初始化(He Initialization)
He 初始化是专门为 ReLU 及其变体(如Leaky ReLU)激活函数设计的初始化方法。
它在Xavier初始化的基础上,将方差放大,以适应ReLU激活函数。
公式
- 若使用正态分布:
- 若使用均匀分布:
优点
更适合ReLU激活函数,能有效避免梯度消失问题。
缺点
对于其他非ReLU激活函数,可能不如Xavier初始化效果好。
5.LeCun 初始化(LeCun Initialization)
LeCun 初始化是一种专门为特定激活函数(如 tanh 和 Leaky ReLU)设计的权重初始化方法。
它的目标是确保在前向传播和反向传播中,网络中信号的方差能够保持稳定,从而避免梯度消失或爆炸问题。
公式
LeCun 初始化的方法是基于正态分布对权重进行初始化,其标准差与输入神经元的数量 相关
优点
能有效保持网络中信号的方差一致,适用于特定的激活函数。
缺点
对于其他激活函数效果有限。
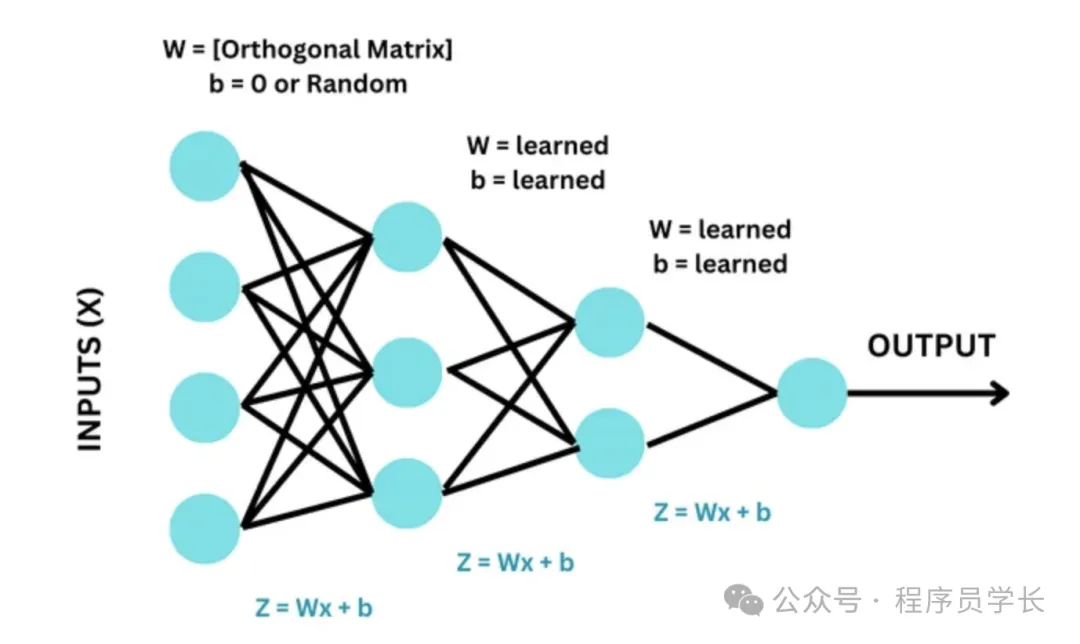
6.Orthogonal初始化(Orthogonal Initialization)
Orthogonal 初始化是将权重矩阵初始化为一个正交矩阵。
正交矩阵的特性使得其转置矩阵也是其逆矩阵,从而在反向传播中能够很好地保持信号的流动。
优点
能有效避免梯度消失和梯度爆炸问题,特别适用于深度神经网络。
缺点
计算复杂度较高,适用范围有限。
7.Variance Scaling 初始化
Variance Scaling 初始化是一种基于方差缩放的权重初始化方法。
它是为了解决在深度网络中,由于不当的权重初始化导致的梯度消失或梯度爆炸问题。
Variance Scaling 初始化通过缩放初始化权重的方差,使得每一层的输出方差保持一致,从而稳定模型的训练过程。
Variance Scaling 初始化通常使用以下公式定义:
其中:
- W 是初始化后的权重矩阵。
- 是当前层的输入单元数(即输入特征的数量)。
- 是一个可调参数,用于缩放权重的方差。常见的缩放参数有 1、2、 等。
- 表示均值为 0、方差为 的正态分布。
优点
- 通用性强,Variance Scaling 初始化是一种非常通用的初始化方法,可以适应不同的网络结构和激活函数。
- 避免梯度消失/爆炸,通过合适的方差缩放,Variance Scaling 初始化能够有效避免梯度消失或爆炸问题。
缺点
- 参数选择复杂,需要根据具体的激活函数和网络结构选择合适的缩放因子,这增加了使用的复杂性。












