大语言模型 (LLM) 经历了重大的演变,最近,我们也目睹了多模态大语言模型 (MLLM) 的蓬勃发展,它们表现出令人惊讶的多模态能力。
特别是,GPT-4o 的出现显著推动了 MLLM 领域的发展。然而,与这些模型相对应的开源模型却明显不足。开源社区迫切需要进一步促进该领域的发展,这一点怎么强调也不为过。
本文 ,来自腾讯优图实验室等机构的研究者提出了 VITA,这是第一个开源的多模态大语言模型 (MLLM),它能够同时处理和分析视频、图像、文本和音频模态,同时具有先进的多模态交互体验。
研究者以 Mixtral 8×7B 为语言基础,然后扩大其汉语词汇量,并进行双语指令微调。除此以外,研究者进一步通过多模态对齐和指令微调的两阶段多任务学习赋予语言模型视觉和音频能力。
VITA 展示了强大的多语言、视觉和音频理解能力,其在单模态和多模态基准测试中的出色表现证明了这一点。
除了基础能力,该研究在提升自然多模态人机交互体验方面也取得了长足进步。据了解,这是第一个在 MLLM 中利用非唤醒交互和音频中断的研究。研究者还设计了额外的状态 token 以及相应的训练数据和策略来感知各种交互场景。
VITA 的部署采用复式方案,其中一个模型负责生成对用户查询的响应,另一个模型持续跟踪环境输入。这使得 VITA 具有令人印象深刻的人机交互功能。
VITA 是开源社区探索多模态理解和交互无缝集成的第一步。虽然在 VITA 上还有很多工作要做才能接近闭源同行,但该研究希望 VITA 作为先驱者的角色可以成为后续研究的基石。

- 论文地址:https://arxiv.org/pdf/2408.05211
- 论文主页:https://vita-home.github.io/
- 论文标题:VITA: Towards Open-Source Interactive Omni Multimodal LLM

在上述视频中,用户可以和 VITA 进行无障碍的沟通,看到用户穿的白色 T 恤后,会给出搭配什么颜色的裤子;在被问到数学题时,能够实时查看题目类型,进行推理,然后给出准确的答案;当你和别人讲话时,VITA 也不会插嘴,因为知道用户不是和它交流;出去旅游,VITA 也会给出一些建议;在 VITA 输出的过程中,你也可以实时打断对话,并展开另一个话题。

在这个视频中,用户拿着一个饼干,询问 VITA 自己在吃什么,VITA 给出在吃饼干,并给出饼干搭配牛奶或者茶口感会更好的建议。
健身时,充当你的聊天搭子:

注:上述视频都是实时 1 倍速播放,没有经过加速处理。
根据用户提供的流程图,VITA 就能编写代码:

提供一张图片,VITA 也能根据图片内容回答问题:

还能观看视频回答问题,当用户抛出问题「详细描述狗的动作」,VITA 也能准确给出答案:

方法介绍
如图 3 所示,VITA 的整体训练流程包括三个阶段:LLM 指令微调、多模态对齐和多模态指令微调。

LLM 指令微调
Mixtral 8x7B 的性能属于顶级开源 LLM 中一员,因此该研究将其作为基础。然而研究者观察到官方的 Mixtral 模型在理解中文方面的能力有限。为了注入双语(中文和英文)理解能力,该研究将中文词汇量扩展到基础模型,将词汇量从 32,000 个增加到 51,747 个。在扩展词汇量后,研究者使用 500 万个合成的双语语料库进行纯文本指令微调。
多模态对齐
为了弥合文本和其他模态之间的表征差距,从而为多模态理解奠定基础。仅在视觉对齐阶段训练视觉连接器。表 1 总结了所使用的训练数据,除了纯文本部分。

视觉模态
首先是视觉编码器。研究者使用 InternViT-300M-448px 作为视觉编码器,它以分辨率 448×448 的图像作为输入,并在使用一个作为简单两层 MLP 的视觉连接器后生成了 256 个 token。对于高分辨率图像输入,研究者利用动态 patching 策略来捕捉局部细节。
视频被视作图像的特殊用例。如果视频长度短于 4 秒,则统一每秒采样 4 帧。如果视频长度在 4 秒到 16 秒之间,则每秒采样一帧。对于时长超过 16 秒的视频,统一采样 16 帧。
其次是视觉对齐。研究者仅在视觉对齐阶段训练视觉连接器,并且在该阶段没有使用音频问题。
最后是数据级联。对于纯文本数据和图像数据,该研究旨在将上下文长度级联到 6K token,如图 4 所示。值得注意的是,视频数据不进行级联。

级联不同的数据有两个好处:
- 它支持更长的上下文长度,允许从单个图像问题交互扩展到多个图像问题交互,从而产生更灵活的输入形式,并扩展上下文长度。
- 它提高了计算效率,因为视频帧通常包含大量视觉 token。通过级联图像 - 问题对,该研究可以在训练批中保持平衡的 token 数量,从而提高计算效率。
此外,该研究发现使用级联数据训练的模型与使用原始数据训练的模型性能相当。
音频模态
一方面是音频编码器。输入音频在最开始通过一个 Mel 滤波器组块进行处理,该块将音频信号分解为 mel 频率范围内的各个频带,模仿人类对声音的非线性感知。随后,研究者先后利用了一个 4×CNN 的下采样层和一个 24 层的 transformer,总共 3.41 亿参数,用来处理输入特征。同时他们使用一个简单的两层 MLP 作为音频 - 文本模态连接器。最后,每 2 秒的音频输入被编码为 25 个 tokens。
另一方面是音频对齐。对于对齐任务,研究者利用了自动语言识别(ASR)。数据集包括 Wenetspeech(拥有超过 1 万小时的多领域语音识别数据,主要侧重于中文任务)和 Gigaspeech(拥有 1 万小时的高质量音频数据,大部分数据面向英文语音识别任务)。对于音频字幕任务,研究者使用了 Wavcaps 的 AudioSet SL 子集,包含了 400k 个具有相应音频字幕的音频片段。在对齐过程中,音频编码器和连接器都经过了训练。
多模态指令微调
该研究对模型进行了指令调整,以增强其指令遵循能力,无论是文本还是音频。
数据构建。指令调优阶段的数据源与表 1 中对齐阶段的数据源相同,但该研究做了以下改进:
问题被随机(大约一半)替换为其音频版本(使用 TTS 技术,例如 GPT-SoVITS6),旨在增强模型对音频查询的理解及其指令遵循能力。
设置不同的系统 prompt,避免不同类型数据之间的冲突,如表 2 所示。例如,有些问题可以根据视觉信息来回答或者基于模型自己的知识,导致冲突。此外,图像数据已被 patch,类似于多帧视频数据,这可能会混淆模型。系统 prompt 显式区分不同数据类型,有助于更直观地理解。

为了实现两种交互功能,即非唤醒交互和音频中断交互,该研究提出了复式部署框架,即同时部署了两个 VITA 模型,如图 1 所示。

在典型情况下,生成模型(Generation model)会回答用户查询。同时,监控模型(Monitoring model)在生成过程中检测环境声音。它忽略非查询用户声音,但在识别到查询音频时停止生成模型的进度。监控模型随后会整合历史上下文并响应最新的用户查询,生成模型和监控模型的身份发生了转换。

实验评估
语言性能。为了验证语言模型训练过程的有效性,研究者使用了四个数据集,分别是 C-EVAL、AGIEVAL、MMLU 和 GSM8K。这些数据集涵盖了各种场景,包括一般选择题、多学科问答题以及数学和逻辑推理任务,同时覆盖了中英文上下文。
下表 3 的结果表明,本文的训练显著增强了语言模型在中文评估集(C-EVAL 和 AGIEVAL)上的能力,同时保持了在英文相关基准(MMLU)上的原始性能水平,并在数学推理任务(GSM8K)上实现显著提升。

音频性能。为了验证模型学得的语音表示的稳健性,研究者在 Wenetspeech 和 Librispeech 两个数据集上进行了测试。
其中 Wenetspeech 有两个评估指标,分别是 test_net 和 test_meeting,前者数据源与训练数据更加一致,因而更容易;后者提出了更大的挑战。作为模型的 held-out 数据集,Librispeech 评估了模型在未见过数据集上的泛化能力,它有四个评估集,以「dev」开头的是验证集,以「test」开头的是测试集,「Clean」代表挑战性较低的集,「other」代表挑战性更高的集。
从下表 4 的结果可以看到,VITA 在 ASR 基准测试上取得了非常不错的结果。

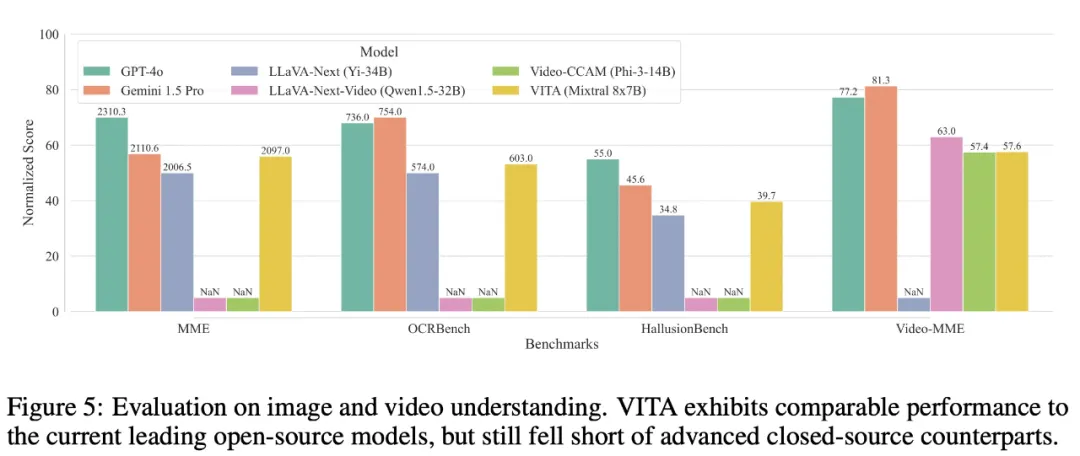
多模态性能。为了评估多模态能力,该研究在四个基准上评估了 VITA,包括 MME 、OCRBench、HallusionBench 和 Video-MME。结果如图 5 所示。
在图像理解方面,VITA 优于图像专用开源模型 LLaVA-Next,并且接近闭源模型 Gemini 1.5 Pro。
在视频理解方面,VITA 超过了视频开源模型 Video-CCAM。尽管 VITA 和视频专用的 LLaVA-Next-Video 之间存在差距,但考虑到 VITA 支持更广泛的模态并优先考虑可交互性,因而这是可以接受的。
最后,值得注意的是,目前开源模型与专有模型在视频理解能力方面仍存在较大差距。