














译者 | 李睿
审校 | 重楼
Vaswani等研究人员在2017年发表的开创性论文《注意力是你所需要的一切》中介绍了Transformer架构,该架构不仅彻底改变了语音识别技术,也改变了许多其他领域。本文探讨了Transformer的演变,追溯其从最初设计到最先进模型的发展轨迹,并重点介绍这一过程中取得的重大进展。
原始Transformer
原始Transformer模型引入了几个突破性的概念:
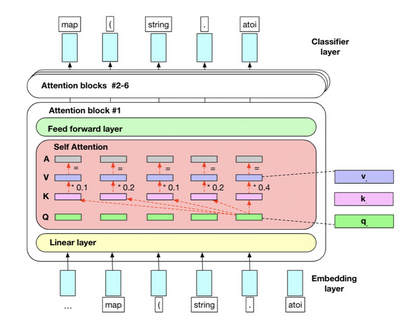
- 自关注机制:这让模型确定每个组件在输入序列中的重要性。
- 位置编码:在序列中添加有关令牌位置的信息,使模型能够捕获序列的顺序。
- 多头注意力:这一功能允许模型同时关注输入序列的不同部分,增强其理解复杂关系的能力。
- 编码器-解码器架构:分离输入和输出序列的处理,实现更高效的序列到序列学习。
这些元素结合在一起,创建了一个强大而灵活的架构,其性能优于之前的序列到序列(S2S)模型,特别是在机器翻译任务中。
编码器-解码器 Transformer 及其超越发展
最初的编码器-解码器架构已经被改编和修改,并取得了一些显著的进步:
- BART (双向和自回归Transformer):结合了双向编码和自回归解码,在文本生成方面取得了显著的成功。
- T5 (文本到文本迁移转换器):将所有NLP任务重新转换为文本到文本的问题,促进多任务处理和迁移学习。
- mT5(多语言T5):将T5的功能扩展到101种语言,展示了其对多语言环境的适应性。
- MASS (掩码序列到序列预训练):为序列到序列学习引入新的预训练目标,提高了模型性能。
- UniLM(统一语言模型):集成双向、单向和序列到序列语言建模,为各种NLP任务提供统一的方法。
BERT和预训练的兴起
谷歌公司于2018年推出的BERT(基于Transformer的双向编码器表示)是自然语言处理领域的一个重要里程碑。BERT推广并完善了在大型文本语料库上进行预训练的概念,导致了NLP任务方法的范式转变。以下了解BERT的创新及其影响。
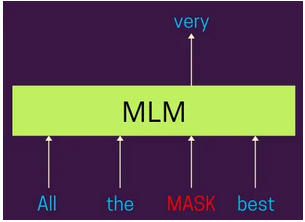
掩码语言建模(MLM)
- 过程:随机屏蔽每个序列中15%的令牌。然后,该模型尝试根据周围的场景来预测这些被屏蔽的令牌。
- 双向场景:与之前从左到右或从右到左处理文本的模型不同,掩码语言建模(MLM)。
- 允许BERT同时从两个方向考虑场景。
- 深入理解:这种方法迫使模型对语言有更深入的了解,包括语法、语义和场景关系。
- 变体掩码:为了防止模型在微调过程中过度依赖[MASK]令牌(因为[MASK]在推理过程中不会出现),80%的掩码令牌被[MASK]替换,10%被随机单词替换,10%保持不变。
下句预测(NSP)
- 过程:模型接收成对的句子,并且预测原文中的第二个句子是否紧跟着第一个句子。
- 执行:50%的时间,第二个句子是实际的下一个句子,50%是从语料库中随机抽取的句子。
- 目的:这项任务帮助BERT理解句子之间的关系,这对于问答和自然语言推理等任务至关重要。

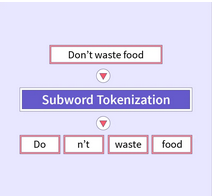
子单词令牌化
- 过程:将单词划分为子单词单元,平衡词汇量的大小和处理词汇外单词的能力。
- 优点:这种方法使BERT能够处理各种语言,并有效地处理形态丰富的语言。
GPT:生成式预训练Transformer
OpenAI公司的生成式预训练Transformer (GPT)系列代表了语言建模方面的重大进步,重点关注用于生成任务的Transformer解码器架构。GPT的每次迭代都在规模、功能和对自然语言处理的影响方面带来了实质性的改进。
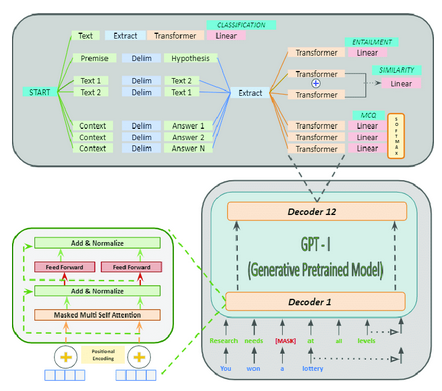
GPT-1 (2018年发布)
第一个GPT模型引入了大规模无监督语言理解的预训练概念:
- 架构:基于12层和1.17亿个参数的Transformer解码器。
- 预训练:利用各种在线文本。
- 任务:根据前面的单词预测下一个单词。
- 创新:证明了一个单一的无监督模型可以针对不同的下游任务进行微调,在没有特定任务架构的情况下实现高性能。
- 影响:GPT-1展示了NLP中迁移学习的潜力,其中在大型语料库上预训练的模型可以通过相对较少的标记数据对特定任务进行微调。
GPT-2 (2019年发布)
GPT-2显著增加了模型大小,并表现出令人印象深刻的零样本学习能力:
- 架构:最大的版本有15亿个参数,是GPT-1的10倍多。
- 训练数据:使用更大、更多样化的网页数据集。
- 特点:能够在各种主题和风格上生成连贯和场景相关的文本。
- 零样本学习: 通过简单地在输入提示中提供指令,展示了执行未经专门训练的任务的能力。
- 影响:GPT-2强调了语言模型的可扩展性,并引发了关于强大文本生成系统的伦理影响的讨论。
GPT-3 (2020年发布)
GPT-3代表了规模和能力的巨大飞跃:
- 架构:由1750亿个参数组成,比GPT-2大100多倍。
- 训练数据:利用来自互联网、书籍和维基百科的大量文本。
- 少样本学习:在不需要微调的情况下,只用少量例子或提示就能完成新任务。
- 多功能性:展示了在各种任务中的熟练程度,包括翻译、问答、文本摘要,甚至基本的编码。
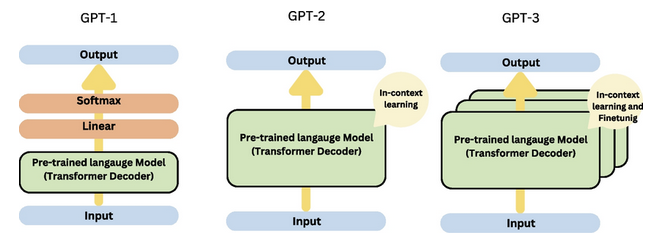
GPT-4 (2023年发布)
GPT-4在之前版本模型奠定的基础上,进一步拓展了语言模型的可能性。
- 架构:虽然具体的架构细节和参数数量尚未公开披露,但GPT-4被认为比GPT-3更大、更复杂,其底层架构得到了增强,以提高效率和性能。
- 训练数据:GPT-4在更广泛和多样化的数据集上进行了训练,包括广泛的互联网文本、学术论文、书籍和其他来源,确保了对各种学科的全面理解。
- 先进的少样本和零样本学习:GPT-4表现出更强的能力,以最少的例子执行新任务,进一步减少了对特定任务微调的需要。
- 增强的场景理解:场景感知的改进使GPT-4能够生成更准确、更符合场景的响应,使其在对话系统、内容生成和复杂问题解决等应用程序中更加有效。
- 多模态功能:GPT-4将文本与其他模态(例如图像和可能的音频)集成在一起,实现了更复杂、更通用的人工智能应用程序,可以处理和生成不同媒体类型的内容。
- 伦理考虑和安全:OpenAI公司非常重视GPT-4的伦理部署,实施先进的安全机制来减少潜在的滥用,并确保负责任地使用该技术。
注意力机制的创新
研究人员对注意力机制提出了各种修改,并取得了重大进展:
- 稀疏注意力:通过关注相关元素的子集,可以更有效地处理长序列。
- 自适应注意力:根据输入动态调整注意力持续时间,增强模型处理不同任务的能力。
- 交叉注意力变体:改进解码器处理编码器输出的方式,从而产生更准确和场景相关的生成。
结论
Transformer架构的演变是显著的。从最初的介绍到现在最先进的模型,Transformer一直在突破人工智能的极限。编码器-解码器结构的多功能性,加上注意力机制和模型架构的不断创新,将继续推动NLP及其他领域的进步。随着研究的继续,人们可以期待进一步的创新,将这些强大的模型的功能和应用扩展到各个领域。
原文标题:Exploring the Evolution of Transformers: From Basic To Advanced Architectures,作者:Suri Nuthalapati
























