问题背景
假设我们有一个大文件,里面包含了100亿个整数。我们只有10MB的内存,要在其中找到中位数。首先,什么是中位数呢?简单来说,中位数就是排序后位于中间位置的那个数。对于100亿个整数来说,中位数就是第50亿个数。
问题的挑战:
- 数据量巨大:100亿个整数可不是小数目,如果每个整数占用4字节,那么100亿个整数需要大约400GB的存储空间。
- 内存限制:仅有10MB的内存,根本无法一次性载入这些数据。
面对如此大数据量和有限的内存,我们该如何找到中位数呢?别慌,我们一起来看看如何应对这两种情况!
内存够的情况下
如果你有足够的内存,那就简单多了!我们可以一次性将所有数据载入内存,然后进行排序,找到排序后中间位置的那个数即可。哪怕你使用最简单的冒泡排序也可以解决问题。
 图片
图片
这个方法虽然简单粗暴,但在实际中几乎不可能,因为面试官不会给你那么多内存!
内存不够的情况下
当内存不够时,我们就得动点脑筋了。我们可以通过“分治”的思想将大问题逐步缩小到内存能够处理的范围。
思路解析
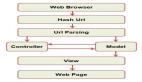
- 分文件处理:由于我们只关心中位数,所以可以通过二进制的位来将数据分成多个子文件。每次处理一个子文件,缩小范围,直到我们能够找到中位数。
- 二进制位划分:首先,读取文件中的数据到内存中(不超过10MB),然后根据数字的二进制最高位(第32位,符号位)将数字分成两个文件。如果最高位为0,表示这个数是非负数,则写入file_0文件中;如果最高位为1,表示这个数是负数,则写入file_1文件中。
具体实现
以下是这个过程的Java代码实现:
 图片
图片
 图片
图片
代码解析
- 划分文件:通过divideFile方法,我们可以根据指定的二进制位将文件中的数字分成两个文件。这里用的是BufferedReader和BufferedWriter来处理文件IO,以确保效率。
- 递归查找中位数:findMedianInFile方法中,我们不断缩小范围,直到文件中的数据可以直接在内存中处理(通过排序找出中位数)。
进一步优化
如果文件过大,读取和写入操作可能会成为瓶颈。可以考虑使用更高效的IO方式或者利用多线程并发处理来提升性能。此外,对于非常大的数据集,分布式处理也是一种可行的方案。
END
在解决大数据问题时,内存的限制是必须要考虑的因素。通过分治法,我们能够有效地将问题规模逐步缩小,最终在有限的内存内找到答案。这个思路不仅仅适用于寻找中位数的问题,还可以推广到其他需要处理大数据的场景中。