












列表(list)是 Python 中最常见且最基础的数据结构之一,它是一个存储对象的容器,可以包含任何类型的对象,包括字符串、数字,甚至其他对象。列表还可以混合存储不同类型的数据。掌握列表的各种操作,如创建、添加、排序等,不仅可以提高编程效率,还能简化数据处理过程。
基本操作
接下来将了解添加、移除或访问列表元素的不同方法。从添加元素的方法开始。
添加元素
可以使用 append() 方法在列表末尾添加一个元素,或者使用 insert() 方法在指定位置添加一个元素。对于添加多个元素,最好的方法是使用 extend()。
fruits = ['apple', 'banana']
# Adds at the end
fruits.append('cherry')
fruits 图片
图片
# Inserts at position 1
fruits.insert(1, 'orange')
fruits 图片
图片
# Adds multiple items
fruits.extend(['date', 'elderberry',100])
fruits 图片
图片
- append() 和 extend() 在各自的用途上都很高效。append() 具有常数时间复杂度,使其在添加单个元素时非常高效。
- insert():对于较长的列表来说,可能效率不高,因为列表中的所有后续元素可能需要移动以为新元素腾出空间。
- extend() 比在循环中使用 append() 添加多个元素更高效,因为它最小化了反复调整列表大小的开销。
移除元素
移除元素的方法有多种:
- 使用 del 根据索引或切片删除元素。
- 使用 pop() 删除指定位置的元素(如果没有指定位置,则删除最后一个元素)。
- 使用 remove() 根据值删除元素。
# Removes by value
fruits.remove('banana')
fruits 图片
图片
popped_fruit = fruits.pop(2)
print(popped_fruit)
fruits 图片
图片
del fruits[0]
fruits 图片
图片
- remove(value):删除给定值的第一个实例。当你知道要删除的值但不知道其位置时,这个方法非常有用。
- pop(index):删除指定位置的对象并返回它。如果未提供索引,则删除并返回最后一个元素。当你确切知道要删除的对象的位置或需要返回已删除的对象时,这个方法非常适合。
- del list[index]:从给定的切片或索引中删除项目。被删除的对象不会被返回。当你根据位置删除切片或项目且不需要返回已删除的对象时,这个方法非常理想。
访问元素和切片
使用元素的索引是访问列表中元素的简单方法。对列表进行切片可以获取其中的一个子集。
first_fruit = fruits[0]
first_fruit 图片
图片
# Gets a slice from index 1 to 2
fruit_slice = fruits[1:3]
fruit_slice 图片
图片
- 索引访问:当需要列表中的特定元素时,这是理想的方法。就像从书架上选择一本书,确切地知道它的位置。
- 切片:适用于多种需求。就像在书架上选择两个位置之间的一系列书。
搜索和排序列表
搜索元素
in 关键字可以用来检查列表中是否存在某个元素。使用 index() 方法可以进行更深入的搜索,例如确定某个元素的索引。以下是相关代码。
fruits = ['apple', 'banana', 'cherry']
# Returns True if 'banana' is in the list
is_banana_present = 'banana' in fruits
is_banana_present 图片
图片
# Gets the index of 'banana'
banana_index = fruits.index('banana')
banana_index
排序列表
sort() 方法用于就地排序,会直接修改原始列表,使排序变得简单。使用 sorted() 可以获取排序后的列表副本,而不改变原始列表。
numbers = [3, 1, 4, 1, 5, 9, 2]
# Sorts the list in-place
numbers.sort()
print(numbers)
# Returns a new sorted list. The original remains unchanged
sorted_numbers = sorted(numbers)
sorted_numbers
反转列表
使用 reverse() 方法可以就地反转列表,或者使用步长为 -1 的切片来创建一个反转的列表副本。
numbers.reverse()
numbers 图片
图片
reversed_numbers = numbers[::-1]
reversed_numbers 图片
图片
- 使用 reverse() 方法,当你需要反转列表元素且不再需要原始顺序时。
- 使用步长为 -1 的切片,当你需要一个反转版本的列表,同时保留原始列表的顺序以供进一步使用时。
高级列表操作技巧
上面描述了基本的列表方法和技巧,让我们来看看一些更高级的列表操作技巧。
列表推导式用于简洁高效的循环
列表推导式( list comprehensions)是一种基于现有列表创建新列表的简单方法。它类似于用一行代码编写一个循环。这在应用于数据科学的转换数据或过滤数据时非常有用。
# Creates a list of squares
squares = [x**2 for x in range(10)]
squares 图片
图片
通过添加条件来实现偶数的平方列表:
even_squares = [x**2 for x in range(10) if x % 2 == 0]
even_squares 图片
图片
嵌套列表和矩阵操作
列表中的列表称为嵌套列表。在数据科学中,它们常用于表示矩阵或二维数据。
# A 3x3 matrix
matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
print(matrix)
first_row = matrix[0]
first_row 图片
图片
使用 filter()、map() 和 reduce() 方法处理列表
这些方法为列表的函数式编程交互提供了工具:
- filter() 根据条件选择项目。
- map() 对每个项目应用一个函数。
- reduce() 将所有项目聚合为一个输出。
现在让我们逐一应用它们。首先创建一个列表并进行过滤。以下是代码示例:
from functools import reduce
# 创建一个列表
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 使用 filter() 选择偶数
even_numbers = list(filter(lambda x: x % 2 == 0, numbers))
print(even_numbers)
# 使用 map() 将每个数字平方
squared_numbers = list(map(lambda x: x ** 2, numbers))
print(squared_numbers)
# 使用 reduce() 计算所有数字的和
sum_of_numbers = reduce(lambda x, y: x + y, numbers)
print(sum_of_numbers) 图片
图片
处理列表副本
在处理 Python 列表副本时,有两种类型的副本:浅拷贝(Shallow copies)和深拷贝(Deep copies)。
尽管浅拷贝会创建一个新列表,但它不会复制其内部的元素。这意味着,如果你有嵌套列表,原始列表和副本将共享这些嵌套列表。另一方面,深拷贝完全独立于原始列表,因为它会生成一个新列表,并复制其中的每个元素。
浅拷贝(Shallow copies
import copy
original_list = [[1, 2, 3], [4, 5, 6]]
shallow_copied_list = copy.copy(original_list)
shallow_copied_list[0][0] = 'changed'
print(f"{original_list=}")
print(f"{shallow_copied_list=}") 图片
图片
深拷贝(Deep copies)
import copy
original_list = [[1, 2, 3], [4, 5, 6]]
shallow_copied_list = copy.deepcopy(original_list)
shallow_copied_list[0][0] = 'changed'
print(f"{original_list=}")
print(f"{shallow_copied_list=}")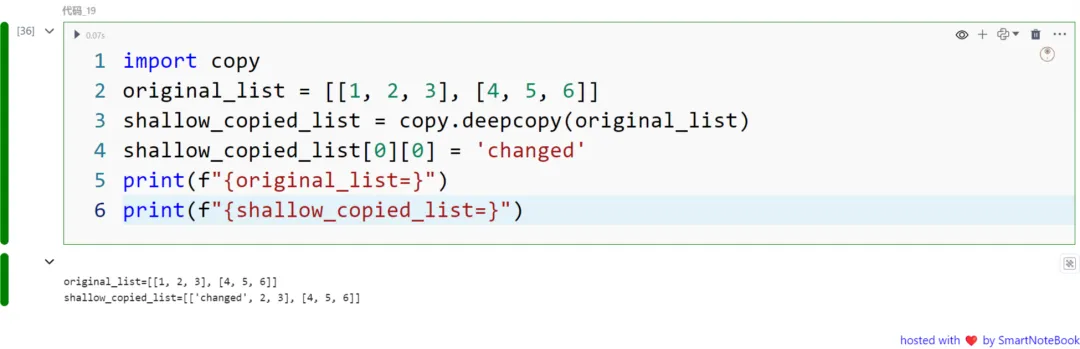
在数据中处理复杂数据结构时,了解浅拷贝和深拷贝之间的区别对于防止意外后果至关重要。
列表操作的提示
- 构建列表时使用列表推导式而不是循环,它们通常更快且更易于理解。
- 减少在循环中操作:在可能的情况下,使用列表推导式或 map() 生成列表比在循环中附加更有效。
- 注意浅拷贝和深拷贝:了解其区别以防止意外修改。
- 不要过度使用列表推导式:尽管功能强大,但如果过于复杂,可能会变得难以阅读,保持简单和整洁。
上述探讨了Python列表的多种方法与技巧,从基本操作如添加、删除和访问元素,到高级技巧如列表推导式、嵌套列表和函数式编程方法。理解浅拷贝和深拷贝的区别、合理使用列表推导式等优化技巧,有助于提高编程效率和简化数据处理。掌握这些方法对于数据科学、数据分析的编程至关重要。



























