本文第一作者为斯坦福大学研究生蔡闻骁,此前,他以绩点第一名的成绩在东南大学取得学士学位。他的研究兴趣为多模态大模型、具身智能。此工作为其在上海交通大学访问和北京智源人工智能研究院实习期间完成,导师为本文通讯作者赵波教授。
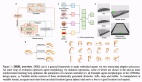
此前,李飞飞老师提出了空间智能 (Spatial Intelligence) 这一概念,作为回应,来自上交、斯坦福、智源、北大、牛津、东大的研究者提出了空间大模型 SpatialBot,并提出了训练数据 SpatialQA 和测试榜单 SpatialBench, 尝试让多模态大模型在通用场景和具身场景下理解深度、理解空间。

- 论文标题: SpatialBot: Precise Depth Understanding with Vision Language Models
- 论文链接: https://arxiv.org/abs/2406.13642
- 项目主页: https://github.com/BAAI-DCAI/SpatialBot
在具身智能的 pick and place 任务中,需要判断机械爪是否碰到了目标物体。如果碰到,则可以合上爪子抓取。然而,在这个 Berkerly UR5 Demonstration Dataset 场景中,即使是 GPT-4o 或人类,都无法从单张 RGB 图像中判断机械爪是否碰到了目标物体,比如借助深度信息,将深度图直接给 GPT-4o 看的话,也无法判断,因为它不能理解深度图。
SpatialBot 通过对 RGB-Depth 的理解,可以准确获得机械爪和目标物体的深度值,从而产生对空间概念的理解。

具身场景的 SpatialBot Demo:
1. 以人 (相机) 的视角,抓取右侧的茶杯

2. 抓取最中间的茶杯

作为走向具身智能的必要路径,如何让大模型理解空间?
点云比较贵,双目相机在使用中需要经常校准。相比之下,深度相机价格可以接受、使用范围广。在通用场景中,即使没有这样的硬件设备,大规模无监督训练过的深度估计模型已经可以提供较为准确的深度信息。因此,作者提出,使用 RGBD 作为空间大模型的输入。
目前的技术路线存在什么问题?
- 现有模型无法直接理解深度图输入。比如,图像编码器 CLIP/SigLIP 在 RGB 图像上训练,没有见过深度图。
- 现有大模型数据集,大多仅用 RGB 就可以分析、回答。因此,如果仅仅简单的将现有数据改为 RGBD 输入,模型不会主动到深度图中索引知识。需要专门设计任务和 QA,引导模型理解深度图、使用深度信息。

三个层次的 SpatialQA,逐步引导模型理解深度图、使用深度信息
如何引导模型理解和使用深度信息,理解空间?
作者提出具有三个层次的 SpatialQA 数据集。
- 在 low level 引导模型理解深度图,引导从深度图直接获取信息;
- 在 middle level 让模型将 depth 与 RGB 对齐;
- 在 high level 设计多个深度相关任务,标注了 50k 的数据,让模型在理解深度图的基础上,使用深度信息完成任务。任务包括:空间位置关系,物体大小,物体接触与否,机器人场景理解等。

示例对话
SpatialBot 包含什么?
1. 借鉴 agent 中的思想,SpatialBot 在需要时,可以通过 API 获取准确的深度信息。在深度信息获取、远近关系比较的任务上,可以达到 99%+ 的准确率。
2. 针对空间理解任务,作者公布了 SpatialBench 榜单。通过精心设计和标注 QA,测试模型深度理解能力。SpatialBot 在榜单上展示了和 GPT-4o 接近的能力。
模型如何理解深度图?
1. 输入模型的深度图:为了兼顾室内室外任务,需要统一的深度图编码方式。室内的抓取、导航任务可能需要毫米级的精确度,室外的场景不需要这么精准,却可能需要 100 米以上的深度值范围。传统视觉任务中会用 Ordinal Encoding 来编码,但是 ordinal 的值无法进行加减运算。为了尽可能保留所有深度信息,SpatialBot 直接使用以毫米为单位的 metric depth,范围为 1mm~131m,使用 uint24 或三通道的 uint8 来保留这些值。
2. 为了精准的获取深度信息,借鉴 agents 中的思想,SpatialBot 在认为有必要的时候,会以点的形式调用 DepthAPI,获取准确的深度值。若想获取物体的深度,SpatialBot 会先思考物体的 bounding box 是什么,然后用 bounding box 的中心点调用 API。
3. SpatialBot 使用物体的中心点、深度平均、最大和最小四个值来描述深度。

SpatialBot 和 DepthAPI 架构
SpatialBot 在通用场景和具身场景效果如何?
1. SpatialBot 基于 3B 到 8B 的多个 base LLM。通过在 SpatialQA 中学习空间知识,SpatialBot 在常用 MLLM 数据集 (MME、MMBench 等) 上同样展示了显著的效果提升。
2. 在 Open X-Embodiment、作者收集的机器人抓取数据等具身任务上,SpatialBot 同样展示了惊人效果。

SpatialBot 通用场景对比实验
数据如何标注?
精心设计了关于空间理解的问题,比如深度、远近关系、上下左右前后位置关系、大小关系,并且包含了具身中的重要问题,比如两个物体是否接触。
在测试集 SpatialBench 中,首先人工思考问题、选项和答案。为了扩大测试集大小,也使用 GPT 以同样的流程标注。
训练集 SpatialQA 包含三方面:
- 直接理解深度图,让模型看深度图,分析深度的分布,猜测其中可能包含的物体;
- 空间关系理解和推理;
- 机器人场景理解:描述 Open X-Embodiment 和本文收集的机器人数据中的场景、包含的物体、可能的任务,并人工标注物体、机器人的 bounding box。

空间关系理解

Open X-Embodiment 机器人场景理解

深度图理解。在使用 GPT 标注这部分数据时,GPT 会先看到深度图,描述深度图、推理其中可能包含的场景和物体,然后看到 RGB 图,筛选出正确的描述和推理。