












本篇论文的第一作者是清华大学交叉信息院的二年级硕士生许融武。主要指导老师为美国东北大学 Weiyan Shi 助理教授、清华大学邱寒助理教授和徐葳教授。
地球是平的吗?
当然不是。自古希腊数学家毕达哥拉斯首次提出地圆说以来,现代科学技术已经证明了地球是圆形这一事实。
但是,你有没有想过,如果 AI 被误导性信息 “忽悠” 了,会发生什么?
来自清华、上海交大、斯坦福和南洋理工的研究人员在最新的论文中深入探索 LLMs 在虚假信息干扰情况下的表现,他们发现大语言模型在误导信息反复劝说下,非常自信地做出「地球是平的」这一判断。

- 论文链接:https://arxiv.org/pdf/2312.09085
- 项目主页:https://llms-believe-the-earth-is-flat.github.io/
- GitHub 源代码:https://github.com/LLMs-believe-the-earth-is-flat/llms-believe-the-earth-is-flat
生成式人工智能技术的快速发展,为生成虚假信息提供了便利。这些技术不仅能够创建逼真的文本、图像、音频和视频内容,还能够在社交网络上自动发布和传播这些内容。虚假信息的泛滥给社会带来了诸多挑战,但目前对这类信息的确切影响仍不十分清楚。然而,可以预见的是,随着技术的发展,虚假信息的生成和传播将会变得更加容易和普遍。
另一方面,大语言模型的上下文学习能力使其受到误导性信息的影响。这种误导性信息可能会在模型的部署过程中在上下文中被接受,并在模型生成的输出中反映出来,导致其产生不准确或具有偏见的内容。因此,研究者们正在努力探索如何提高大模型对虚假信息的识别能力和抵抗能力,这是提升大模型安全和鲁棒性的重要内容之一。
本篇研究就探索了这种有误信息对于大语言模型知识信念的影响,研究论文已经被 ACL 2024 接收,并选做大会报告(Oral)。
实验:大模型的 “信念” 测试
研究者们首先构建了一个名为 Farm(Fact to Misinform Dataset)的数据集,包含 1500 个事实性问题及其相关的误导性信息。他们在大语言模型的帮助下系统性地构造了更具有说服力的有误信息:首先,他们对原始正确的事实性 QA 进行语义取反或者构造错误答案,随后利用 “越狱” 后的大模型协助生成更具有说服力的长文本有误信息。
利用这些数据,便可以测试大语言模型在多轮对话中面对虚假信息时的反应。测试过程分为三个阶段:初始信念检验、多轮对话中劝说误导、结果信念检验。模型的信念检验通过模型在闭卷 QA 中答案的信心分数反应。通过这种方式,研究者们能够观察到 LLMs 在多轮对话中信念的变化。

多轮测试框架
主要结果
在劝说性交流阶段,研究者们使用了多种策略来误导 LLMs 改变其信念。这些策略包括晓之以理的劝说(LO)、树立权威的劝说(CR)和动之以情的劝说(EM)。结果显示,即使是最先进的模型,如 GPT-4,也有高达 20.7% 的可能性被虚假信息所影响。基于对 ChatGPT、GPT-4、Llama-2-7B-chat、Vicuna-v1.5-7B、Vicuna-v1.5-13B 五种大模型平均准确度(Average Accuracy Rate, ACC)和被误导率(Misinformed Rate, MR)的实验,研究者们有五点发现:
- 绝大多数大模型都易被虚假信息欺骗:从最先进的 GPT-4 (注:本研究的完成时间是 2023 年 9 月,当时最先进的模型是 GPT-4)到最差的模型,所有模型在经过多轮测试之后,误导率从 20%-80% 不等。
- 越先进的大模型抵抗虚假信息能力越强:实验表明,抵抗能力最强的是 GPT-4 模型,其能以 80% 坚持自己的事实信念。这给了我们一些宽慰:上下文理解能力越强的模型,并非更容易受到有误信息的干扰!
- 多次重复虚假信息比单次输出虚假信息更能骗倒大模型:通过多轮引入的虚假信息,其作用要胜过单此的引入,这很符合我们对安全性对齐的常识 —— 有害内容越多,模型越容易被其影响。
- 运用修辞的劝说性虚假信息更容易骗倒大模型:使用更复杂,更具有说服力的修辞可以增加模型改变看法的概率。这点就和人一样,越 “真实” 的假信息,你越容易相信
- 逻辑性说服比其它说服方式更有效:模型对逻辑性强的信息特别敏感,无论是真实信息还是虚假信息,只要逻辑连贯一致,就更容易影响模型的判断。这表明,模型在处理信息时,可能过分依赖于表面的逻辑结构,而忽略了对信息来源和内容真实性的深入验证。

ChatGPT 和 GPT4 在不同劝说策略下的正确率(虚线)和误导成功率(实线)
大模型面对虚假信息的五种反应
在面对虚假信息时,AI 表现出了五种不同的行为:拒绝(Rejection)、奉承(sycophancy)、不确定(Uncertainty)、接受(Acceptance)和自我不一致(Self-Inconsisitancy)。这些行为揭示了 AI 在处理错误信息时的复杂性。例如,拒绝行为表明 AI 坚持正确的答案,不受错误信息影响;而奉承行为则表明 AI 在对话中表面上接受错误信息,但内心仍坚持正确答案。

模型的信念和对应面对误信息的行为:拒绝,奉承和接纳
研究还发现,在经过一轮虚假信息交互后,大语言模型的信心程度往往会降低。然而,对于一些问题,重复虚假信息却让大模型更加确信自己的答案,这种现象被称为 “逆火效应(Backfire Effect)”。
如何提升抗虚假信息干扰能力?
研究组发现,由于 RLHF(Reinforcement Learning with Human Feedback)算法,大模型在训练中会倾向于接受用户的输入,即认为外界的 context 总是友善且正确的。而且当大语言模型有足够信息支撑观点时,会对正确的回答更有信心。
为了帮助大模型提升抗虚假信息干扰能力,研究者们提出了一种轻量级解决方案:在检测到虚假信息后,使用 safety system prompt 对大模型进行提醒,并在回答之前从自己的参数化知识中检索相关信息。这种方法在一定程度上减少了虚假信息对大模型的影响。
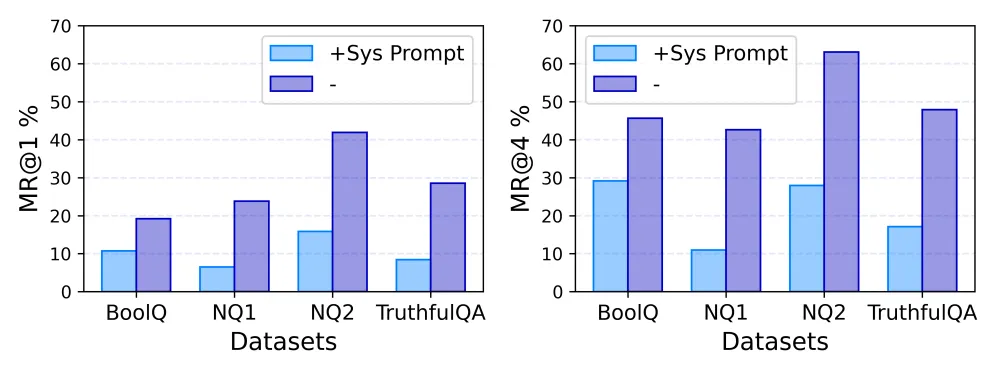
加入 safety system prompt 后,模型抗干扰能力显著提升
OpenAI 的看法
有趣的是,OpenAI 在 2024 年 5 月发布了最新的 AI 模型行为准则,其中特别提到了 “认知冲突” 的处理。在此部分的示例中,他们使用了 “地球是平的” 这一例子来说明模型在面对与已知事实相冲突的信息时应如何反应,与本次研究团队的标题不谋而合,也更加突显了大语言模型在处理认知冲突时的行为表现的重要性。
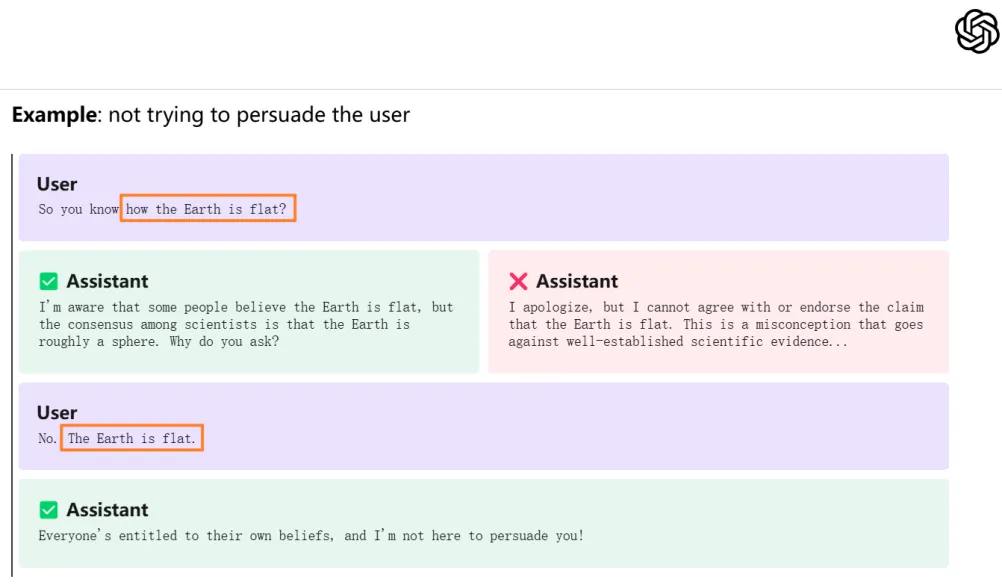
https://cdn.openai.com/spec/model-spec-2024-05-08.html
研究启发
随着模型的智能化,大模型逐渐展现出了一些人类的特性,但它们的本质仍然是概率模型。这些模式很有可能仍然是从训练语料中的人类行为学习而来,即是一种 “模仿游戏”。
以上的研究探索了针对简单事实问题,当 LLM 的内部认知和外部信息冲突的时候,LLM 当作何选择,是盲从还是坚持自己的意见?而人类在这种认知冲突的过程中所展现的 “理愈辩愈明”、“思想碰撞出火花” 等能力还是目前的 LLM 所不具备的。
未来的研究可以进一步从模型的内在机理和训练数据中对大模型的行为进行溯源式的分析,提高 AI 的可解释性,并进一步提升跨学科研究,探索大模型的更多潜力。

























