1、集群环境及存在问题
1.1 集群环境
- 1 台宿主机,2 个 ES 节点。
- 宿主机配置:56 核 CPU, 256G 内存,普通非SSD 磁盘
- 宿主机除了部署 ES 集群两个节点,还部署了其他服务如 redis、其他(不详)。
1.2 索引分片
- 单索引 700 GB 左右。
- 20 个分片。
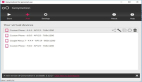
1.3 改动过如下配置
 图片
图片
1.4 存在问题
Elasticsearch 查询特别慢,内存使用率 93%, 现在没什么解决思路。
————问题来自球友:https://t.zsxq.com/LcRV0
2、仅如上信息,可以发现的问题
2.1 存在典型问题
两节点分布在一台机器,还有混部了一些其他的服务。
本质是两虚拟机共享一个实体服务器。
混合部署了 Redis 等服务,这是大问题。
Redis 属于内存数据库,“吃内存”厉害。我们一般不建议这么搞,官方也不建议这么搞。
2.2 盲目修改集群配置,可能带来潜在风险
其中,search.max_buckets 默认值:10000。现在扩大了1000倍,改成了 1000 万。
该配置项用于限制 Elasticsearch 中聚合查询(如 histogram 聚合)中返回的最大桶数。过高的桶数可能会导致内存使用过多,影响集群性能。
其中,thread_pool.write.queue_size 默认值:200。现在改成 2048,扩大了 10 倍+。
该配置项用于指定写入操作的线程池队列大小,当队列满时,新的写入请求将被拒绝。
增大队列大小可以缓解写入压力,但也会增加内存消耗。其中,indices.fielddata.cache.size 默认值:未设置具体默认值(动态分配),
该配置项用于限制字段数据缓存的大小,默认情况下是根据 JVM 堆内存动态调整。可以使用百分比表示,例如 20% 表示使用最大可用堆内存的 20% 作为缓存。
也就是这个支持动态调整的,咱们给写死了。
上述修改其实都经不起推敲和验证,非常的“大胆”,但出问题往往也会超出咱们的预期。
2.2 其他问题不明显
- 疑似问题1:单索引是700g左右, 分片20?单分片大小35g,具体单文档细节不详。
- 疑似问题2:只有2台机器。本质两台机器角色都具备:主节点、数据节点角色,其中一台还充当协调节点角色。
- 疑似问题3:症状提及的查询慢问题,需要给出慢查询日志,需要给出监控指标数据,需要描述一下业务,需要给出检索的DSL语句。
3、拿到集群日志,一切变得明朗
 图片
图片
如上截图为两个节点的日志,-02-1 为主节点日志,-02-2 为另外一个节点的日志。
4、主节点日志“逆向”分析
4.1 test-1016-2024-08-02-1.log 日志含拒绝请求“9790”次
从最早日期:[2024-08-02T17:15:54,487
到最晚日期:[2024-08-02T17:28:57,460]
累计时长:13 分 2.973 秒。
共有如下类似相同报错:9790 次。
日志截取如下:
Caused by: org.elasticsearch.common.util.concurrent.EsRejectedExecutionException: rejected execution of org.elasticsearch.common.util.concurrent.TimedRunnable@5ccc5247 on QueueResizingEsThreadPoolExecutor[name = slav1/search, queue capacity = 1000, min queue capacity = 1000, max queue capacity = 1000, frame size = 2000, targeted response rate = 1s, task execution EWMA = 12.2ms, adjustment amount = 50, org.elasticsearch.common.util.concurrent.QueueResizingEsThreadPoolExecutor@10c62020[Running, pool size = 85, active threads = 85, queued tasks = 1000, completed tasks = 370806]]也就是说,当前节点已经高负荷扛不住了。
 图片
图片
上述错误是由于 Elasticsearch 线程池饱和导致的。这具体表现在 EsRejectedExecutionException 中,表示有任务被拒绝执行。
详细原因拆解如下:
- QueueResizingEsThreadPoolExecutor 饱和
报错信息显示 search 线程池的队列已经达到最大容量(queue capacity = 1000),并且活动线程数已经达到最大(active threads = 85),所以新任务被拒绝执行。
- 任务积压
报错信息中提到有 1000 个任务在队列中等待执行,说明当前系统的负载很高,可能是因为查询请求过多或请求处理时间较长。
- 搜索请求过多或复杂
从报错信息看,搜索请求的参数和查询条件比较复杂(包含多重布尔查询、排序等,见 4.2 的 DSL 语句),这可能导致了较高的计算和处理时间。
可能的解决方案探讨:
- 方案1:增加节点资源
增加 Elasticsearch 集群中的节点数,或者增加现有节点的资源(CPU、内存等),以分担负载。
看老板给不给硬件投入支持。
- 方案2:优化查询
简化查询条件,减少不必要的字段返回和高亮显示等操作,尽量优化查询性能。见4.2 章节分析。
- 方案3:调整线程池设置
调整 search 线程池的配置,如增大 queue capacity 和 pool size,以便处理更多的并发请求。
但前提:必须结合硬件资源进行合理调整,而不是盲改 100倍、1000倍甚至更大的值。
4.2 打开slow_log 慢日志后,DSL语句显现。
Elasticsearch 日志能否把全部请求打印出来?
 图片
图片
4.2.1 问题1:"track_total_hits": 2147483647
问题描述:将 track_total_hits 设置为 2147483647(即 2^31-1)是非常高的一个值,会导致性能问题。
- 原因:
(1)性能消耗大。
计算所有匹配文档的总数需要遍历所有匹配的文档,这对于大规模数据集来说是非常耗时和耗资源的操作。
(2)不必要的精确度。
通常用户并不需要一个如此精确的匹配数量,大部分情况下一个较小的估算值已经足够。
Elasticsearch 8.X 聚合查询下的精度问题及其解决方案
- 推荐优化后的解决方案:
(1)合理设置 track_total_hits
将 track_total_hits 设置为 true 或者一个合理的数值,例如 10000,以满足大多数统计需求,同时减少系统负担。
(2)分页处理
通过分页获取数据,而不是一次性获取大量匹配文档的总数。
干货 | 全方位深度解读 Elasticsearch 分页查询
4.2.2 问题2:基于脚本排序
问题描述:脚本排序会极大地影响查询性能,尤其是在处理大量数据时。
原因:
- (1)计算开销大
脚本排序需要在每个匹配的文档上执行脚本计算,这会导致高额的 CPU 开销。
- (2)缓存难以利用
脚本排序结果难以缓存,因为每次请求可能都会涉及不同的计算逻辑和参数。
- 推荐解决方案
(1)预计算字段
尽量将排序逻辑预计算成字段,存储在文档中,避免在查询时实时计算。
例如,预先计算并存储评分、排名等,可以借助 ingest pipeline 预处理实现。
这就是咱们之前多次强调过的“空间换时间”。
Elasticsearch的ETL利器——Ingest节点
Elasticsearch 预处理没有奇技淫巧,请先用好这一招!
(2)优化脚本
如果必须使用脚本排序,确保脚本尽可能简单和高效。使用 Painless 脚本语言并确保脚本已编译优化。最好别用!
(3)索引优化
使用合适的索引结构和字段类型,确保查询性能和排序效率。
4.2.3 问题3:Mapping 中有超级多字段,仅 includes 就有:41 个 字段。
Mapping 中包含过多字段,尤其是查询时 _source 包含大量字段,会增加查询负担。
原因:
(1)I/O 开销大
每次查询需要从磁盘读取大量字段数据,增加了 I/O 开销。
(2)网络传输慢
返回的数据量大,增加了网络传输时间,影响响应速度。
(3)内存消耗大
在返回大量字段数据(41个字段的数据)时,会占用较多内存,影响系统性能。
- 建议解决方案:
(1)按需返回字段
仅在 _source 中包含必要的字段,减少数据量。例如,只包含用户实际需要显示或处理的字段。
(2)字段分类管理
将常用字段和不常用字段分开管理,常用字段可以集中存储和索引,不常用字段可以进行更高效的压缩和存储。
Elasticsearch 8.x 存储有无压缩?能压缩到多少?
(3)动态字段处理
考虑使用动态字段(借助运行时字段实现)或字段别名,在需要时动态扩展,而不是在 Mapping 中预先定义所有可能的字段。
4.3 No search context found for id [XXXXXXX],报错:236次。
如下错误:
org.elasticsearch.search.SearchContextMissingException: No search context found for id [208049],在 13 分 2.973 秒内共发生 236 次。
 图片
图片
这表明在执行 Scroll 查询时,某些查询上下文已经丢失或超时。
[2024-08-02T12:05:44,520][DEBUG][o.e.a.s.TransportSearchScrollAction] [slave] [208049] Failed to execute query phase
org.elasticsearch.transport.RemoteTransportException: [slav1][172.17.0.1:29302][indices:data/read/search[phase/query/scroll]]
Caused by: org.elasticsearch.search.SearchContextMissingException: No search context found for id [208049]4.3.1 “上下文丢失”可能的原因分析
- 查询上下文过期 Scroll 查询上下文默认在保持不活动状态下只会持续一段时间(默认 1 分钟)。如果查询处理时间超过此时间,上下文会被清除,从而导致此错误。
- 高并发导致上下文管理混乱 在高并发场景下,大量 Scroll 查询请求可能导致系统无法及时管理和维护这些上下文,造成上下文丢失。
- 节点重启或崩溃 执行 Scroll 查询的节点如果在查询过程中重启或崩溃,会导致查询上下文丢失。
4.3.2 解决方案
- 方案1:增加 Scroll 上下文的保持时间
需要排查咱们做了啥?
在 Scroll 查询请求中增加 scroll 参数,例如设置为 5 分钟:
{
"scroll": "5m"
}根据查询复杂度和数据量调整保持时间,确保足够长的时间完成查询。
如果数据量不大或可以分段处理,使用常规分页查询代替 Scroll 查询,减少对上下文的依赖。
- 方案二:优化查询性能 简化查询条件,减少不必要的计算,提升查询速度。
如前所述,“空间换时间”,预先计算和缓存部分查询结果,减少实时计算量。
5、非主节点日志“逆向分析”
除了类似主节点报错外,非主节点报错如下:
[2024-08-02T17:41:21,517][WARN
org.elasticsearch.cluster.block.ClusterBlockException: blocked by: [SERVICE_UNAVAILABLE/2/no master]; 图片
图片
大致推测:[2024-08-02T17:41:21,517] 主节点宕机了。
5.1 问题描述
上述日志报错表明 Elasticsearch 集群当前没有主节点(master node)。
在 Elasticsearch 集群中,主节点负责管理集群状态和元数据(例如索引和节点信息)。如果集群中没有主节点,整个集群会变得不可用,导致无法执行任何操作,包括索引和查询。
5.2 原因猜测
- 主节点故障:当前主节点可能已经发生故障或崩溃(猜测就是第4部分分析的,扛不住压力导致宕机)。
- 资源不足:主节点所在的物理机器资源不足(如内存、CPU),导致主节点崩溃。
6、小结
通过合理配置和优化,Elasticsearch 集群的性能问题是可以逐步解决的。
但,爆改集群默认配置是不建议的。
关键在于合理分配资源,优化查询和索引操作,同时结合监控工具和日志分析,及时发现并解决潜在问题。
希望上述分析和建议能够帮助大家更好地管理和优化 Elasticsearch 集群,提高系统的稳定性和响应速度。
第一部分提到的集群配置、节点角色划分、分片大小、文档大小、文档映射、检索语句、监控指标等都值得进一步深入探讨......