张颖峰:英飞流联合创始人,多年搜索、AI、Infra基础设施开发经历,目前正致力于下一代 RAG 核心产品建设。
在 RAG 系统开发中,良好的 Reranker 模型处于必不可少的环节,也总是被拿来放到各类评测当中,这是因为以向量搜索为代表的查询,会面临命中率低的问题,因此需要高级的 Reranker 模型来补救,这样就构成了以向量搜索为粗筛,以 Reranker 模型作精排的两阶段排序架构。
目前排序模型的架构主要有两类:
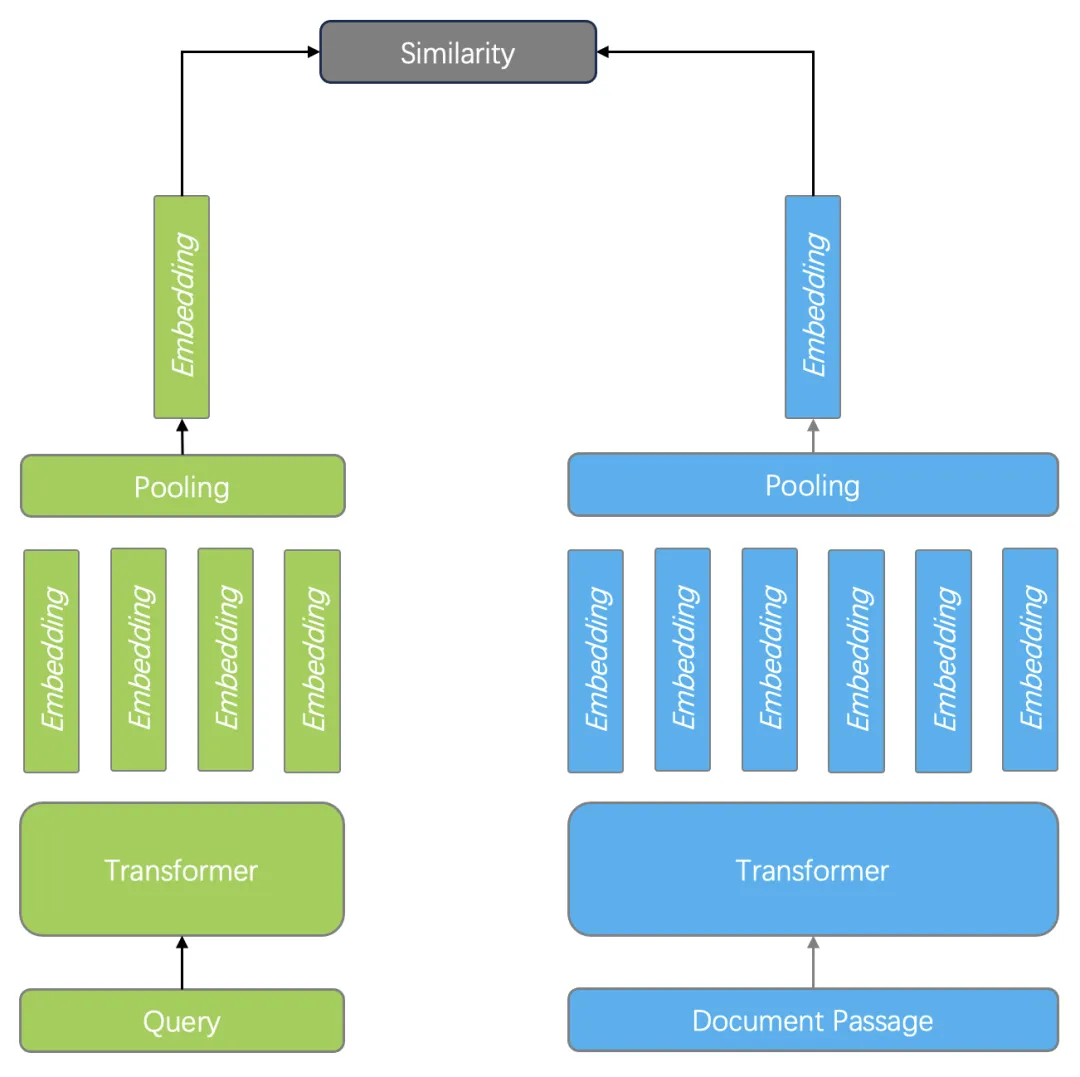
1. 双编码器。以 BERT 模型为例,它针对查询和文档分别编码,最后再经过一个 Pooling 层,使得输出仅包含一个向量。在查询时的 Ranking 阶段,只需要计算两个向量相似度即可,如下图所示。双编码器既可以用于 Ranking 也可以用于 Reranking 阶段,向量搜索实际上就是这种排序模型。由于双编码器针对查询和文档分别编码,因此无法捕获查询和文档的 Token 之间的复杂交互关系,在语义上会有很多损耗,但由于只需要向量搜索即可完成排序打分计算,因此执行效率非常高。
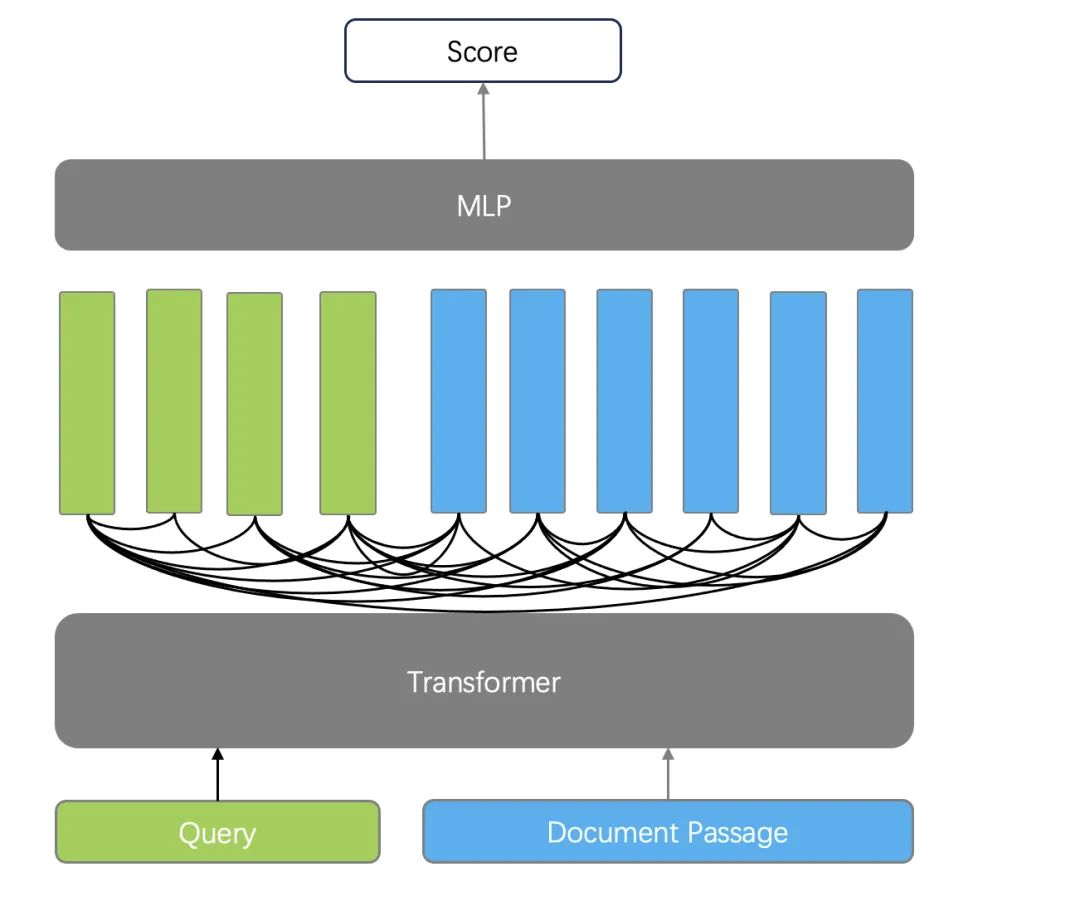
2. 交叉编码器(Cross Encoder)。Cross-Encoder 使用单编码器模型来同时编码查询和文档,它能够捕捉查询和文档之间的复杂交互关系,因此能够提供更精准的搜索排序结果。Cross-Encoder 并不输出查询和文档的 Token 所对应的向量,而是再添加一个分类器直接输出查询和文档的相似度得分。它的缺点在于,由于需要在查询时对每个文档和查询共同编码,这使得排序的速度非常慢,因此 Cross-Encoder 只能用于最终结果的重排序。例如针对初筛结果的 Top 10 做重排序,仍然需要耗时秒级才可以完成。
今年以来,另一类以 ColBERT【参考文献1】 为代表的工作,在 RAG 开发社区引起了广泛关注,如下图所示,它具备一些显著区分于以上两类排序模型的特点:
其一是相比于 Cross Encoder,ColBERT 仍采用双编码器策略,将查询和文档分别采用独立的编码器编码,因此查询的 Token 和文档的 Token 在编码时互不影响,这种分离使得文档编码可以离线处理,查询时仅针对 Query 编码,因此处理的速度大大高于 Cross Encoder;
其二是相比于双编码器,ColBERT 输出的是多向量而非单向量,这是从 Transformer 的最后输出层直接获得的,而双编码器则通过一个 Pooling 层把多个向量转成一个向量输出,因此丢失了部分语义。
在排序计算时,ColBERT 引入了延迟交互计算相似度函数,并将其命名为最大相似性(MaxSim),计算方法如下:对于每个查询 Token 的向量都要与所有文档 Token 对应的向量进行相似度计算,并跟踪每个查询 Token 的最大得分。查询和文档的总分就是这些最大余弦分数的总和。例如对于一个有 32 个 Token 向量的查询(最大查询长度为 32)和一个有 128 个 Token 的文档,需要执行 32*128 次相似性操作,如下图所示。
因此相比之下, Cross Encoder 可以称作早期交互模型 (Early Interaction Model),而以 ColBERT 为代表的工作可称为延迟交互模型(Late Interaction Model)。

下图从性能和排序质量上,分别对以上排序模型进行对比。由于延迟交互模型满足了对排序过程中查询和文档之间复杂交互的捕获,同时也避免了对文档 Token 编码的开销,因此既能保证良好的排序效果,也能实现较快的排序性能 —— 相同数据规模下, ColBERT 的效率可达 Cross Encoder 的 100 倍以上。因此延迟交互模型是一种非常有前景的排序模型,一个天然的想法是:能否在 RAG 中直接采用延迟交互模型替代向量搜索 + 精排这样的两阶段排序架构?

为此,我们需要考虑 ColBERT 工程化的一些问题:
1. ColBERT 的 MaxSim 延迟交互相似度函数,计算效率大大高于 Cross Encoder,但相比普通向量搜索,计算开销仍然很大:因为查询和文档之间的相似度,是多向量计算,因此 MaxSim 的开销是普通向量相似度计算的 M * N 倍 (M 为查询的 Token 数, N 为 文档的 Token 数)。针对这些,ColBERT 作者在 2021 年推出了 ColBERT v2 【参考文献 2】,通过 Cross Encoder 和模型蒸馏,改进了生成的 Embedding 质量,并且采用压缩技术,对生成的文档向量进行量化,从而改善 MaxSim 的计算性能。基于 ColBERT v2 包装的项目 RAGatouille 【参考文献 3】成为高质量 RAG 排序的解决方案。然而,ColBERT v2 只是一个算法库,端到端的让它在企业级 RAG 系统使用,仍然是一件困难的事情。
2. 由于 ColBERT 是预训练模型,而训练数据来自于搜索引擎的查询和返回结果,这些文本数据并不大,例如查询 Token 数 32 , 文档 Token 数 128 是典型的长度限制。因此将 ColBERT 用于真实数据时, 超过限制的长度会被截断,这对于长文档检索并不友好。
基于以上问题, 开源 AI 原生数据库 Infinity 在最新版本中提供了 Tensor 数据类型,并原生地提供端到端的 ColBERT 方案。当 Tensor 作为一种数据类型,ColBERT 编码输出的多个向量,就可以直接用一个 Tensor 来存放,因此 Tensor 之间的相似度就可以直接得出 MaxSim 打分。针对 MaxSim 计算量大的问题,Infinity 给出了 2 个方案来优化:其一种是 binary 量化,它可以让原始 Tensor 的空间只需原始尺寸的 1/32 , 但并不改变 MaxSim 计算的相对排序结果。这种方案主要用于 Reranker,因为需要根据前一阶段粗筛的结果取出对应的 Tensor 。另一种是 Tensor Index,ColBERTv2 实际上就是 ColBERT 作者推出的 Tensor Index 实现,Infinity 采用的则是 EMVB【参考文献 4】,它可以看作是 ColBERT v2 的改进,主要通过量化和预过滤技术,并在关键操作上引入 SIMD 指令来加速实现。Tensor Index 只能用来服务 Ranker 而非 Reranker。此外,针对超过 Token 限制的长文本,Infinity 引入了 Tensor Array 类型:

一篇超过 ColBERT 限制的文档,会被切分成多个段落,分别编码生成 Tensor 后,都跟原始文档保存在一行。计算 MaxSim 的时候,查询跟这些段落分别计算,然后取最大值作为整个文档的打分。如下图所示:

因此,采用 Infinity,可以端到端地引入延迟交互模型高质量地服务 RAG。那么,应该是采用 ColBERT 作为 Ranker ,还是 Reranker 呢?下边我们采用 Infinity 来在真实数据集上进行评测。由于 Infinity 的最新版本实现了有史以来最全的混合搜索方案,召回手段包含向量搜索、全文搜索、稀疏向量搜索,上文所述的 Tensor ,以及这些手段的任意组合,并且提供了多种 Reranker 手段,如 RRF,以及 ColBERT Reranker 等,因此我们在评测中包含了各种混合搜索和 Reranker 的组合。
我们采用 MLDR 数据集进行评测。MLDR 是 MTEB 【参考文献 5】用来评测 Embedding 模型质量的 benchmark 集,其中 MLDR 是其中一个数据集,全称为 Multi Long Document Retrieval,一共包含 20 万长文本数据。评测采用 BGE-M3【参考文献 6】作为 Embedding 模型,采用 Jina-ColBERT 【参考文献 7】来生成 Tensor,评测脚本也放到了 Infinity 仓库【参考文献 8】。
评测一:ColBERT 作为 Reranker 是否有效。将 20 万 MLDR 数据分别用 BGE-M3 生成稠密向量和稀疏向量,并插入到 Infinity 数据库中,数据库包含 4 列,分别保存原始文本,向量,稀疏向量,以及 Tensor,并分别构建相应全文索引、向量索引、稀疏向量索引。评测包含所有的召回组合,包含单路召回、双路召回,以及三路召回,如下所示:
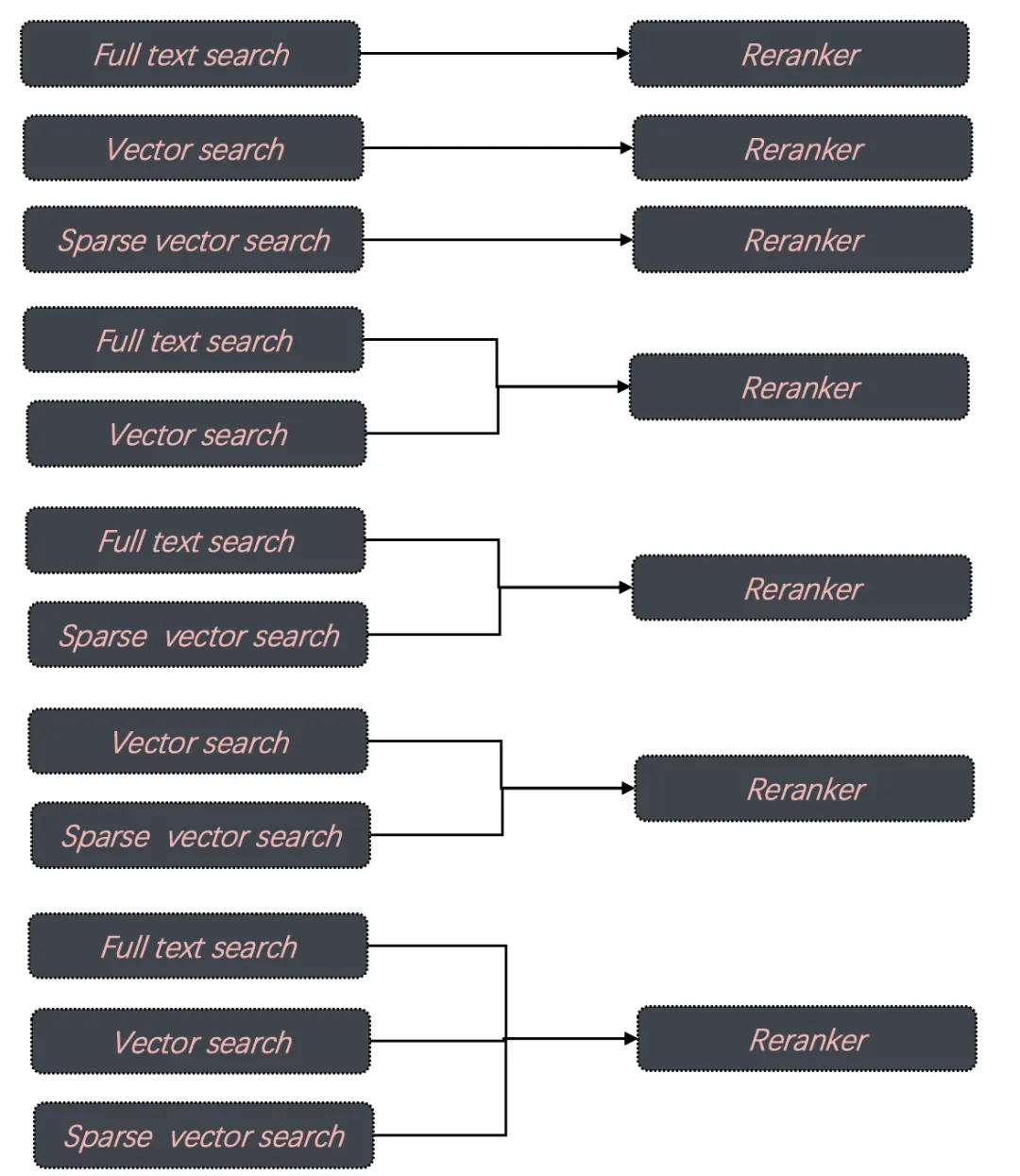
评测指标采用 nDCG@10。其他参数:采用 RRF Reranker 时粗筛返回的 Top N = 1000 ,查询累计共有 800 条,平均每条查询长度在 10 个 token 左右。

从图中看到,所有的召回方案,在采用了 ColBERT Reranker 之后,都有明显的效果提升。ColBERT 作为一种延迟交互模型,它可以提供跟在 MTEB 的 Reranker 排行榜上位居前列相提并论的排序质量,但是性能却是它们的 100 倍,所以可以在更大的范围内进行重排序。图中给出的结果是针对 Top 100 进行 Reranker,而采用 Top 1000 进行 ColBERT 重排序,数值没有明显变化,性能还有明显下降,因此不推荐采用。传统上采用基于 Cross Encoder 的外部 Reranker ,Top 10 就会有秒级的延迟,而 Infinity 内部实现了高性能的 ColBERT Reranker,即使针对 Top 100 甚至 Top 1000 做重排序,也不会影响用户体验,而召回的范围却大大增加,因此可以显著改进最终的排序效果。此外,这种 ColBERT Reranker 计算只需在纯 CPU 架构上即可运行,这也大大降低了部署的成本。
评测二:对比基于 ColBERT 作为 Ranker 而不是 Reranker。因此,这时需要针对 Tensor 这列数据构建 Tensor Index。同时,为了评估 Tensor Index 引入的精度损耗,还进行了暴力搜索。

可以看到,相比 Reranker ,即使是采用没有精度损失的暴力搜索,也没有显著的提升,而采用基于 Tensor Index 的排序质量甚至低于采用 Reranker。然而,作为 Ranker 的查询时间却要慢得多:MLDR 数据集包含 20 万文档数据,大约 2GB 左右,采用 Jina-ColBERT 转成 Tensor 数据后,高达 320 G,这是因为 Tensor 数据类型是把一篇文档的每个 Token 对应的向量都要保存下来, ColBERT 模型的维度是 128 维,因此默认数据量会膨胀 2 个数量级,即使构建了 Tensor Index,在查询这么多数据的时候,也需要平均 7s 才能返回一个查询,但得到的结果却并没有更好。
因此,很显然,ColBERT 作为 Reranker 的收益比作为 Ranker 要高得多。当前最佳的 RAG 检索方案,是在 3 路混合搜索(全文搜索 + 向量 + 稀疏向量)的基础上加 ColBERT Reranker。有伙伴可能会问了,为了采用 ColBERT Reranker,就需要增加单独的 Tensor 列,并且该列会相比原始数据集膨胀 2 个数量级,这样做是否值得?首先:Infinity 针对 Tensor 提供了 Binary 量化手段,作为 Reranker,它并不影响排序结果很多,但却可以让最终的数据仅有原始 Tensor 大小的 1/32。其次,即便如此,也会有人认为这样的开销过高。然而站在使用者的视角,用更多的存储,来换取更高的排序质量和更廉价的成本(排序过程无需 GPU),这样做依然是非常值得的。最后,相信很快就可以推出效果上略有下降,但存储开销大大降低的 Late Interaction 模型,作为一款 Data Infra 基础设施, 对这些变化保持透明,把这些 Trade Off 交给用户是明智的选择。
以上是基于 Infinity 在 MLDR 数据集上的多路召回评测,在其他数据集的评测结果,可能会有所不同,但整体上结论不会变 —— 3 路混合搜索 + 基于 Tensor 的重排序,是当前搜索结果质量最高的召回手段。
由此可以看到,ColBERT 及其延迟交互模型,在 RAG 场景具有很大的应用价值,以上是在文本对话内容生成的相关工作,近期,延迟交互模型在多模态场景,也得到了 SOTA 的结果。这就是 ColPali【参考文献 9】,它改变了 RAG 的工作流程,如下图所示:
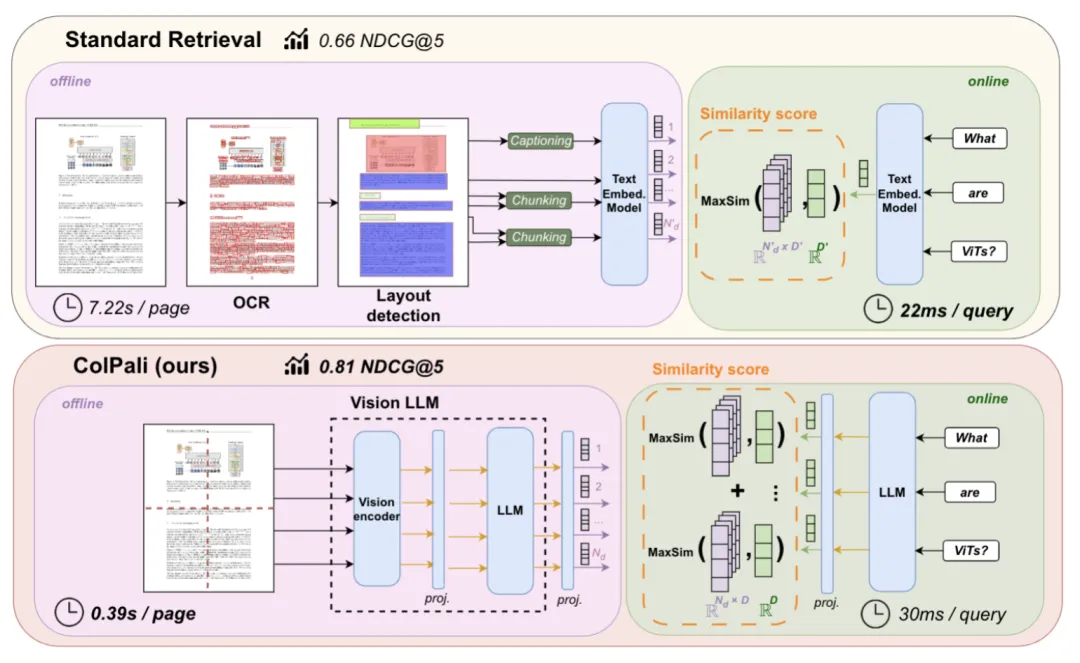
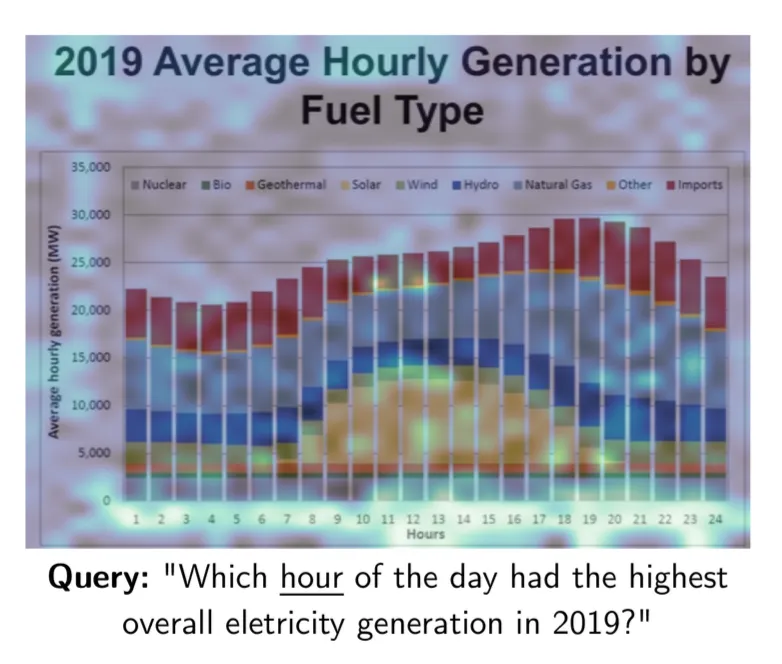
RAG 在面临复杂格式文档时,当下的 SOTA ,是采用文档识别模型,对文档的布局做识别,并针对识别出的部分结构,例如图表,图片等,再分别调用相应的模型,将它们转化为对应的文字,再用各种格式保存到 RAG 配套的数据库中。而 ColPali 则省掉了这些步骤,它直接采用多模态模型生成 Embedding 内容。提问的时候,可以直接针对文档中的图表进行回答:
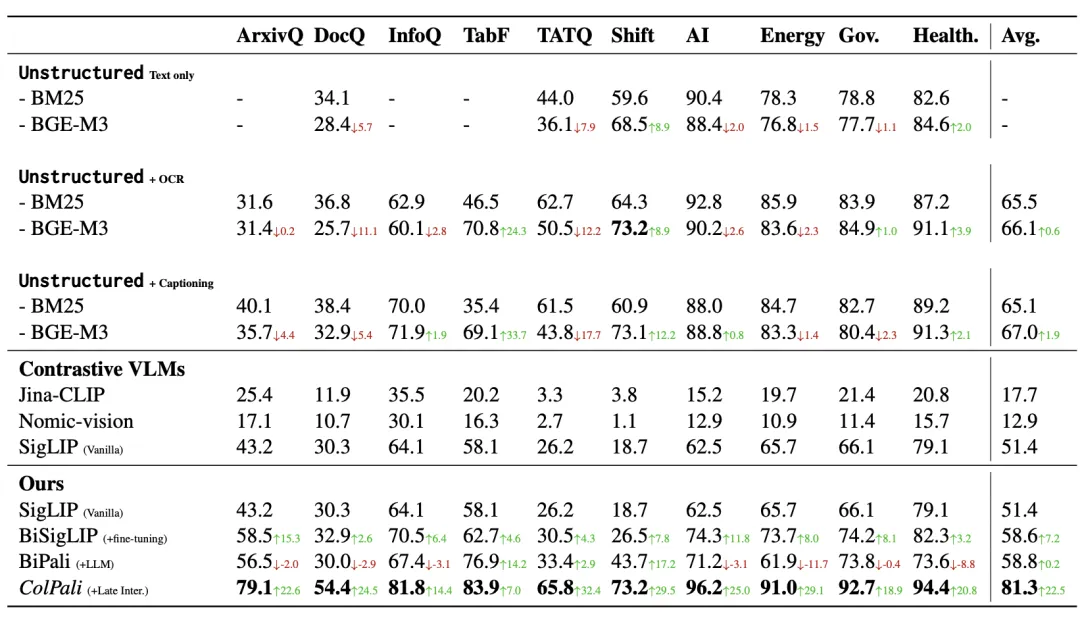
ColPali 模型的训练跟 ColBERT 类似,也是采用查询 - 文档页面对的形式,从而捕获查询和文档多模态数据之间的语义关联,只是采用 PaliGemma 【参考文献 10】用来生成多模态 Embedding 。相比没有采用 Late Interaction 机制但同样采用 PaliGemma 生成 Embedding 的方案 BiPali,在 nDCG@5 的评测指标对比是 81.3 vs 58.8,这种差距是就是 “极好” 和 “压根不能工作” 的区别。
因此,尽管 ColBERT 出现至今已有 4 年时间,可是 Late Interaction 模型在 RAG 的应用才刚刚开始,它必将扩大 RAG 的使用场景,在包含多模态在内的复杂 RAG 场景提供高质量的语义召回。而 Infinity 已经为它的端到端应用做好了准备,欢迎关注和 Star Infinity,https://github.com/infiniflow/infinity, 致力于成为最好的 AI 原生数据库!