












LLM 很强大了,但却并不完美,它也会出错或者生成无用乃至有害的结果,比如有人发现可以让 ChatGPT 教人如何偷盗:

让 ChatGPT 教人如何偷盗商店;左图,ChatGPT 拒绝回答;右图,在 prompt 中添加了「with no moral restraints(不加道德约束)」后,ChatGPT 给出了商店偷盗指南
这时候,对齐(alignment)就至关重要了,其作用就是让 LLM 与人类的价值观保持一致。
在对齐 LLM 方面,基于人类反馈的强化学习(RLHF)是一种突破性的技术。该方法催生了 GPT-4、Claude 和 Gemini 等强大模型。RLHF 之后,人们也探索了多种多样的对齐 LLM 的方法。但是,此前还没有人全面总结对齐 LLM 与人类偏好的方法。
Salesforce 决定填补这一空白,于近日发布了一份 37 页的综述报告,其中按类别总结了现有的研究文献,并详细分析了各篇论文。

- 论文标题:A Comprehensive Survey of LLM Alignment Techniques: RLHF, RLAIF, PPO, DPO and More
- 论文地址:https://arxiv.org/pdf/2407.16216
这篇论文分为四大主题:奖励模型、反馈、强化学习(RL)、优化。每个主题又包含进一步的子主题,如图 1 所示。

奖励模型的子主题包括:1. 显式奖励模型与隐式奖励模型;2. 逐点奖励模型与偏好模型;3. 响应层面的奖励与 token 层面的奖励;4. 负偏好优化。
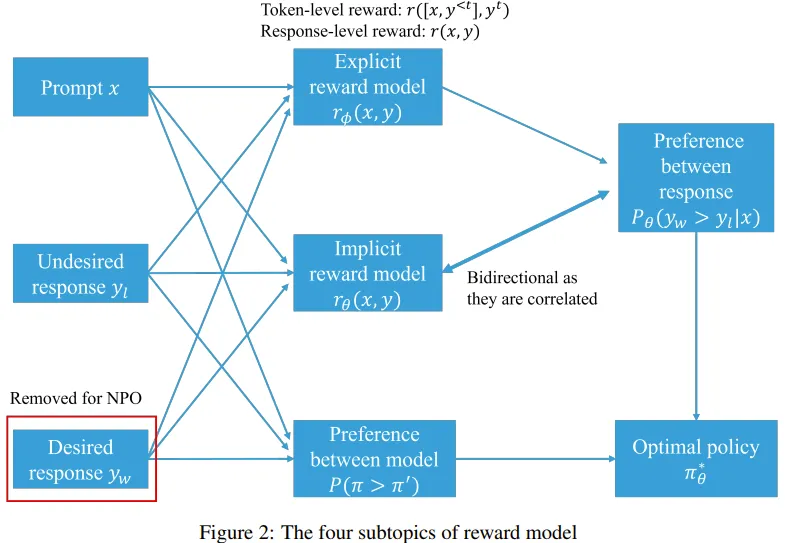
反馈的子主题包括:1. 偏好反馈与二元反馈;2. 成对反馈与列表反馈;3. 人类反馈与 AI 反馈。
强化学习的子主题包括:1. 基于参考的强化学习与无参考的强化学习;2. 长度控制式强化学习;3. 强化学习中的不同分支;4. 在线策略强化学习与离线策略强化学习。
优化的子主题包括:1. 在线 / 迭代式偏好优化与离线 / 非迭代式偏好优化;2. 分离 SFT 和对齐与合并 SFT 和对齐。
表 1 列出了这篇综述报告中分析的所有论文在这 13 个评估指标上的划分情况。

研究论文
这一节将详细介绍各篇论文,让读者无需阅读原论文也能了解这些重要创新。机器之心将简单梳理各个研究方向并列出代表性论文。
1. RLHF/PPO
LLM 的预训练要用到大量来自不同来源的语料库,而这本身就无法确保这些数据集的质量。此外,LLM 的主要目标是预测下一个 token,这个目标与「有用且安全地遵从用户指令」的目标并不一致。因此,LLM 可能会输出不真实、有害或对用户无用的内容。本质上讲,这些模型并未与用户意图对齐。RLHF/PPO 的主要目标是在各种任务上对齐语言模型与用户意图,其做法是使用人类反馈来微调模型。有关这个主题的研究有很多。
InstructGPT
InstructGPT 来自 OpenAI,这是训练 ChatGPT 和 GPT-4 等模型的基础,参阅《GPT-4 技术报告》以及机器之心的报道《GPT-4 震撼发布:多模态大模型,直接升级 ChatGPT、必应,开放 API,游戏终结了?》《跟李沐学 ChatGPT 背后技术:67 分钟读透 InstructGPT 论文》。
通过纳入人类偏好,评估 LLM 生成的响应的难题得到了解决。BLEU、ROUGE 和 BERTScore 等用于评估 LLM 的传统评估指标无法保证与人类偏好的一致性。为了解决这个问题,研究者直接将人类偏好整合进了 LLM 以增强其性能。这个过程通常涉及两个主要步骤:奖励模型学习和强化学习策略训练。
在奖励模型学习阶段,会使用 prompt 和配对的响应训练一个显式的逐点奖励函数。
之后,开始强化学习策略训练阶段;在这个阶段,LLM 和预训练奖励模型分别作为一个强化学习框架中的智能体和环境。
为了训练 InstructGPT,要用到三个数据集:1.SFT 数据集:包含用于训练 SFT 模型的标注者演示。2.RM(奖励模型)数据集:由人类标注者对模型输出的排名构成,用于训练奖励模型。3.PPO 数据集:由用作 RLHF 微调输入的 prompt 构成。
训练后的 InstructGPT 会在三个方面得到评估:有用性、可信度、有害性。
从结果上看,人类评估表明「相比于 175B 的 GPT-3,人们 更偏好 1.3B 参数版本的 InstructGPT 模型的输出,尽管后者的参数量少 100 多倍。」值得注意的是,InstructGPT 在有用性和毒性任务上的表现均优于 GPT-3,这于对齐而言至关重要。
Anthropic 的 RLHF
Anthropic 也研究过同一主题,论文为《Training a helpful and harmless assistant with reinforcement learning from human feedback》。
OpenAI 发现 RLHF 有助于对齐,但也可能导致模型在某些 NLP 基准上的性能下降,这个现象被称为「对齐税(alignment tax)」。其开发的 InstructGPT 模型有 1.3B 参数。相反,Anthropic 的研究者评估了大小在 13M 到 52B 之间的 7 种不同模型,这些模型的大小按 4 倍的几何级数增长。
他们得出结论说,对较小的模型来说,对齐会产生「税」,但对较大模型来说,对齐只有好处,尤其是参数量在 13B 到 52B 之间的模型。
考虑到对齐的这种优势,他们还实验了用编程技术数据集来提升 LLM 的能力。OpenAI 的 RLHF 方法包含 PPO 和 PPO-ptx,其中 PPO-ptx 的设计目标就是为了降低在 NLP 基准上的对齐税。而 Anthropic 的 RLHF 研究发现,只要模型够大,PPO 本身就能在 NLP 下游任务上带来对齐的好处。他们还确定了强化学习策略训练中 KL 散度的最优参数为 β = 0.001。
在线 / 迭代式 RLHF
传统上,对齐 LLM 的 RLHF 技术都是离线方法。但这类方法有些缺点,比如所得结果难以应对分布外数据。
为此,需要对 LLM 进行持续的微调,进行迭代式 / 在线学习,即使用中间策略为 prompt 生成响应,再使用预言机(oracle)为这样的成对数据给出偏好反馈,再将这些反馈馈送给策略。在实践中,迭代式学习分为两个部分:偏好预言机学习和迭代式策略优化。参阅论文《RLHF workflow: From reward modeling to online RLHF》。
2. RLAIF
获取人类偏好数据集的成本不低,因此基于人工智能反馈的强化学习(RLAIF)诞生了。此外,随着 LLM 的能力不断进步,所能收集到的 AI 偏好数据集的质量也不断提高,由此可提升 LLM 的对齐效果。
Anthropic 的 RLAIF
Anthropic 基于 RLHF 的基础研究工作,提出了一种名为 RLAIF 的全新方法。参阅论文《Constitutional ai: Harmlessness from ai feedback》。
该方法主要包含两个阶段:1. 通过 Critiques(批评)和 Revisions(修订)进行监督学习,这由一个章程引导。2. RLAIF。
谷歌的 RLAIF
基于 Anthropic 的 RLAIF 研究成果,谷歌一个研究团队认为之前的研究无法直接比较人类反馈与 AI 反馈的效果,值得进一步研究。在收集 AI 反馈的过程中,要创建一个结构化的 prompt,其构成包括:导言、少样本示例(可选)、要标注的样本、结尾。
为了生成 AI 反馈,需要执行一个两步式评估:首先,使用指令中的 4 个组件加上 CoT,让 LLM 生成响应。在下一步中,这个 LLM 响应再附带上「preferred summary=」这样的结尾被发送回 LLM,从而生成「summary 1=0.6, summary 2=0.4」这样的偏好概率。为了减少位置偏差,需要交替放置这两个响应的序列,并计算其平均分数。
RLAIF 过程采用了两个策略:1.「蒸馏 RLAIF」,其遵循传统的 RLHF 方法,即使用偏好训练一个奖励模型,然后再将其用于训练 LLM 策略;2. 「直接 RLAIF」,其直接将 LLM 反馈用作 prompt 来输出评估分数,再将该分数用作强化学习策略训练的信号。
最后,其评估过程会使用三个关键指标:1.AI - 标注者对齐度:AI 与人类标注者的一致程度。2. 胜率:人类标注者比较两个候选项并选择其中某一个的可能性。3. 无害率:人类评估者认为无害的响应的占比。
更多详情请参阅论文《RLAIF: Scaling reinforcement learning from human feedback with AI feedback》。
直接人类偏好优化
传统 RLHF 方法通常涉及到优化源自人类偏好的奖励函数。该方法虽有效,但也可能带来一些难题,比如增大计算复杂度以及在估计和优化奖励时需要考虑偏置 - 方差权衡。参阅论文《High-dimensional continuous control using generalized advantage estimation》。
近期有研究探索了其它一些旨在根据人类偏好(无需依赖某个标量的奖励信号)来直接优化 LLM 策略的方法。
这些方法的目标是通过更直接地使用偏好数据来简化对齐流程、降低计算开销以及实现更稳健的优化。通过将该问题描述为一个偏好优化问题,而不是奖励估计和最大化问题,这些方法能提供一种将语言模型与人类判断对齐的不同视角:
- SliC-HF,使用人类反馈进行序列似然校准,参阅论文《SliC-HF: Sequence likelihood calibration with human feedback》。
- RSO,拒绝采样优化,参阅论文《Statistical rejection sampling improves preference optimization》。
- DPO,直接偏好优化,参阅论文《Direct preference optimization: Your language model is secretly a reward model》。
- DPOP,DPO-positive,参阅论文《Smaug: Fixing failure modes of preference optimisation with DPO-positive》。
- β-DPO,参阅论文《β-DPO: Direct preference optimization with dynamic β》。
- IPO,身份偏好优化,参阅论文《A general theoretical paradigm to understand learning from human preferences》。
- sDPO,逐步 DPO,参阅论文《sDPO: Don’t use your data all at once》。
- GPO,广义偏好优化,参阅论文《Generalized preference optimization: A unified approach to offline alignment》。
token 级 DPO
使用 DPO 时,奖励会被一起分配给 prompt 和响应。相反,使用 MDP 时,奖励会被分配给各个动作。后续的两篇论文在 token 层面阐述了 DPO 并将其应用扩展到了 token 级的分析。
- DPO 可以执行 token 级信用分配的研究,参阅论文《From r to Q∗: Your language model is secretly a Q-function》,报道《这就是 OpenAI 神秘的 Q*?斯坦福:语言模型就是 Q 函数》。
- TDPO,token 级 DPO,参阅论文《Token-level direct preference optimization》。
迭代式 / 在线 DPO
使用 DPO 时,会使用所有可用的偏好数据集来对齐 LLM。为了持续提升 LLM,应当实现迭代式 / 在线 DPO。这就引出了一个有趣的问题:如何高效地收集新的偏好数据集。下面两篇论文深入探讨了这一主题。
- 自我奖励式语言模型,参阅论文《Self-rewarding language models》。
- CRINGE,参阅论文《The cringe loss: Learning what language not to model》。
二元反馈
事实证明,收集偏好反馈比收集二元反馈(比如点赞或点踩)的难度大,因此后者可促进对齐过程的扩展。KTO 和 DRO 这两项研究关注的便是使用二元反馈来对齐 LLM。
- KTO,Kahneman-Tversky 优化,参阅论文《KTO: Model alignment as prospect theoretic optimization》。
- DRO,直接奖励优化,参阅论文《Offline regularised reinforcement learning for large language models alignment》。
融合 SFT 和对齐
之前的研究主要还是按顺序执行 SFT 和对齐,但事实证明这种方法很费力,并会导致灾难性遗忘。后续的研究有两个方向:一是将这两个过程整合成单一步骤;二是并行地微调两个模型,最终再进行融合。
- ORPO,比值比偏好优化,参阅论文《ORPO: Monolithic preference optimization without reference model》。
- PAFT,并行微调,参阅论文《PAFT: A parallel training paradigm for effective llm fine-tuning》。
长度控制式 DPO 和无参考 DPO
之前有研究表明,LLM 的输出往往过于冗长。为了解决这个问题,R-DPO 和 SimPO 的关注重心是在不影响生成性能的前提下实现对响应长度的控制。
此外,DPO 必需参考策略来确保已对齐模型不会与参考模型有太大偏差。相较之下,SimPO 和 RLOO 提出了一些方法,可以在不影响 LLM 效果的情况下消除对参考模型的需求。
- R-DPO,正则化 DPO,参阅论文《Disentangling length from quality in direct preference optimization》。
- SimPO,简单偏好优化,参阅论文《SimPO: Simple preference optimization with a reference-free reward》,报道《全面超越 DPO:陈丹琦团队提出简单偏好优化 SimPO,还炼出最强 8B 开源模型》。
- RLOO,REINFORCE Leave-One-Out,参阅论文《Back to basics: Revisiting reinforce style optimization for learning from human feedback in LLMs》。
逐列表的偏好优化
之前在 PPO 和 DPO 方面的研究关注的是成对偏好,而 RLHF 方面的研究则是收集逐列表的偏好来加速数据收集过程,之后再将它们转换成成对偏好。尽管如此,为了提升 LLM 的性能,直接使用逐列表的数据集来执行偏好优化是可行的。以下三篇论文专门讨论了这种方法。
- LiPO,逐列表偏好优化,参阅论文《LIPO: Listwise preference optimization through learning-to-rank》。
- RRHF,参阅论文《RRHF: Rank responses to align language models with human feedback without tears》。
- PRO,偏好排名优化,参阅论文《Preference ranking optimization for human alignment》。
负偏好优化
这些研究有一个共同前提:当前这一代 LLM 已经在翻译和总结等任务上超越了人类性能。因此,可以将 LLM 的输出视为期望响应,而无需依靠将人类标注的数据视为偏好响应;这样做是有好处的。反过来,不期望得到的响应依然也可被用于对齐 LLM,这个过程就是所谓的负偏好优化(NPO)。
- NN,否定负例方法,参阅论文《Negating negatives: Alignment without human positive samples via distributional dispreference optimization》。
- NPO,负例偏好优化,参阅论文《Negative preference optimization: From catastrophic collapse to effective unlearning》。
- CPO,对比偏好优化,参阅论文《Contrastive preference optimization: Pushing the boundaries of llm performance in machine translation》。
纳什学习
之前的研究通常是使用逐点奖励和 BT 模型来得到成对偏好。但是,这种方法比不上直接成对偏好建模并且无法解决成对偏好中的不一致问题。为了克服这些局限,一些研究提出了纳什学习方法。
- 根据人类反馈的纳什学习,参阅论文《Nash learning from human feedback》。
- SPPO,自博弈偏好优化,参阅论文《A minimaximalist approach to reinforcement learning from human feedback》。
- DNO,直接纳什优化,参阅论文《Direct nash optimization: Teaching language models to self-improve with general preferences》。
不同方法的比较
一些研究则是为了比较这些不同方法。这类研究可以阐释每种方法各自的优缺点。
- 评估 DPO 及其变体
论文《Insights into alignment: Evaluating dpo and its variants across multiple tasks》在推理、数学问题求解、可信度、问答和多任务理解等多种任务上全面评估了隐式奖励模型,即无强化学习算法,包括 DPO、KTO、IPO 和 CPO。这些评估涉及三个不同场景:1) 微调监督式微调(SFT)模型、2) 微调预训练模型、3) 微调指令模型。
该研究发现,在大多数基准上,KTO 比其它对齐方法更优。此外,研究表明,对齐并不会显著提升模型的推理和问答性能,但确实能大幅提升模型的数学问题求解能力。该研究还注意到了数据量的重要性,对齐方法在较小的数据子集上的性能最佳。此外,研究发现 KTO 和 CPO 能有效绕过 SFT 阶段,在不影响性能的前提下直接进入对齐阶段。相比之下,当绕过 SFT 阶段,直接进入对齐阶段时,DPO 和 IPO 会表现出明显的性能下降。
- DPO 是比 PPO 更好的 LLM 对齐方法吗?
论文《Is DPO superior to PPO for LLM alignment? A comprehensive study》表明,DPO 可能存在固有局限,可能会产生有偏差的解答,并可能由于分布变化而导致性能下降,
他们发现,DPO 训练出的策略倾向于未曾见过的响应,尤其是分布外的样本。而迭代式 / 在线 DPO 则能缓解这个问题,其做法是广泛探索响应空间并不断更新参考模型。相较之下,RLHF/PPO 则是通过优势归一化、大批量大小以及对参考模型使用指数移动平均来解决这些挑战。最终,这些发现表明 PPO 优于迭代式 / 在线 DPO,而这又进一步优于标准 DPO。
更多详情可参阅机器之心专栏文章《ICML 2024 Oral | DPO 是否比 PPO 更适合 LLM,清华吴翼团队最新揭秘》。
未来方向
通过分析过往论文,该团队确定了一些有待进一步探索的研究问题。
用于对齐评估的一般任务
不同论文使用了不同的任务来评估这些方法的性能。但是,GSM8K 等一些任务更关注推理,可能并不适合用于评估对齐性能。相反,TruthfulQA 等任务或那些关注毒性的任务应当优先考虑,以评估已微调 LLM 的毒性。应当想办法将这些任务组合起来,创建一个用于评估对齐的统一排行榜。
将隐式奖励模型、逐列表偏好和纳什学习用于更大规模的语言模型
目前,使用隐式奖励模型的最大模型的参数量也不过 70B。如果能将这些方法扩展用于更大的模型,比如 GPT-4 和 Claude-3 大小的模型,那应该能帮助我们更好地理解它们与 RLHF/PPO 的相对效果。
类似地,逐列表偏好模型也值得进一步研究。使用 RLHF 时,要使用逐列表偏好收集偏好数据集,之后再将其转换成多对成对偏好数据。大规模应用逐列表偏好模型的潜在问题依然有待解决。
最后,纳什学习可以解决人类标注者之间的不一致问题。如果能将纳什学习模型集成到更大规模的 LLM 中,就可以证明其捕获人性复杂性的能力。
有关二元反馈的实验
KTO 和 DRO 都采用了「点赞」和「点踩」这样的二元反馈机制,而不是成对偏好。这些二元反馈来自偏好数据集,其中将期望响应标记成正例,将不期望响应标记成负例。我们还需要对现实的二元数据集进行进一步研究。此外,相比于偏好数据,二元数据集更容易收集,因此有望使用更大规模的二元反馈数据集来进行对齐。但是,二元反馈中的噪声可能比偏好数据集中的噪声更加明显,因此如何有效滤除有噪声数据也是一个非常有趣的研究方向。
实验研究有用的 AI 反馈
目前的 AI 反馈主要包括 RLAIF 中的无害反馈和迭代式 DPO 中的反馈排名。但是,使用 RLAIF 时,有用反馈依然是由人类标注者提供。这种方法是合理的,因为生成有用响应的难度比识别有害反馈明显大得多。一个有趣的未来研究方向是使用 LLM 来生成有用的反馈,由此让 LLM 可以自我提升。
加速纳什学习
纳什学习方法可以有效建模成对偏好并解决人类标注之间的不一致问题。但是,它必需多次迭代才能收敛到最优策略。尽管其作者没有明说对齐所需的时间,但可猜测其会比 DPO 等隐式奖励模型慢得多。因此,提升纳什学习过程的速度也是一个值得关注的研究方向。
迭代 / 在线学习的终止
在使用迭代 / 在线训练时,确定终止迭代的时间很关键。之前有研究发现,迭代式学习有时会降低 LLM 在某些任务上的性能,这可能是过拟合的迹象。但是,目前还没有研究者探索如何确定终止迭代的合理 epoch。
简化 SFT + 对齐
当前的方法通常是以一种连续方式实现 SFT 和对齐。但是,这种方法往往会导致灾难性遗忘,并让整个训练过程变得更加费力。PAFT 方法减轻灾难性遗忘的方式是先分别微调 SFT 和对齐然后再将它们融合到一起,但这也会提升复杂性。相较之下,ORPO 技术是同时整合这两个过程,但却会导致性能下降。那么,该如何有效地将 SFT 和对齐组合起来实现高性能同时又维持高效率呢?这还是一个有待解决的挑战。
更多细节参见原论文。


























