












在当前 AI 领域,大语言模型采用的主流架构是 Transformer。不过,随着 RWKV、Mamba 等架构的陆续问世,出现了一个很明显的趋势:在语言建模困惑度方面与 Transformer 较量的循环大语言模型正在快速进入人们的视线。
令人兴奋的是,这些架构在推理期间使用了恒定量的内存。不过,受制于有限的内存,循环语言模型(LM)无法记忆并使用长上下文中的所有信息,这导致了上下文学习(in-context learning,ICL)质量的不佳。因此,获得高效大语言模型的关键挑战在于选择存储或者丢弃哪些信息。
在最近的论文《Just read twice: closing the recall gap for recurrent language models》中,来自斯坦福大学、布法罗大学的研究者通过简单观察发现,数据在推理期间涌入循环语言模型的排序极大地影响了在有限内存中预测存储哪些信息的难度。
我们假设根据文档 D(比如伽利略・伽利莱的详细维基百科)来提问:伽利略是什么时候搬到的佛罗伦萨?这时,如果提示遵循了 [Q, D] 的排序,则模型只需要记住文档 D 中的一个事实即可。相反,如果提示遵循了 [D, Q] 的排序,则模型需要记住所有事实。如下图 1(左)所示。

因此,本文首先从理论上形式化了数据排序如何影响内存需求,然后提出两种方法来减轻对数据排序的依赖,分别是 Just-read-twice(JRT)提示策略和 JRT 循环架构。本文主要分为以下几个部分展开:
理解数据排序的作用。研究者得出的第一个洞见是:记忆问题的 hardness 要降低到与设置剥离(set disjointness,SD)相同,这是通信复杂度理论中持续数十年的最典型问题。SD 要求一种流算法(比如循环模型)来决定上下文中提供的输入集是否剥离:

理论分析和实验结果表明,第一个集 | A | 掌控了求解 SD 所需的内存。因果模型需要存储 A 中的所有元素以与 B 中的元素进行比较。这表明了,使用上下文中的「正确数据排序」(如将最小 min (|A|, |B|) 的集放在首位)将有助于内存受限的模型。更进一步,观察到上下文非因果逻辑的模型可在空间最小的 (|A|, |B|) 中求解 SD,而无需考虑数据排序。
其次是利用「正确的」排序。本文提出了一种非常简单的 JRT-Prompt 策略,在模型生成答案之前在上下文中将信息重复多次(如上图 1 右所示)。在第二以及更多轮次中,语言模型在决定存储哪些信息时要以完整的上下文为条件,从而有效避免了将数据排序「归正」的问题。
结果表明,JRT-Prompt 在 16 个已有循环语言模型和 6 项 ICL 任务上,实现了平均 11.0 ± 1.3 百分点的提升,而吞吐量是 FlashAttention-2(长度 32k、批大小 16)的 11.9 倍。JRT-Prompt 虽然增加了上下文长度,但渐进来看仍然比注意力更加地计算和内存高效。
超越因果模型。本文提出了 JRT-RNN,它的灵感来源于简单的 Prefix-LM 编码器解码器架构设计。大多数的上下文学习输入包含两部分内容,分别是输入的提示(上下文、指令)和作为输出的模型生成文本。在 Prefix-LM 架构中,LM 并没有遵循因果逻辑地处理提示区域,而对输出进行了因果解码,其中在因果区域仅使用了标准的下一个 token 预测损失,以及非因果区域上的损失。
不过遗憾的是,此前 Prefix-LM 模型的训练方法取得的成功有限,并使用了低效的 Transformer 主干。因此本文通过一些简单的改变来提高质量和效率,包括改进训练损失并使用称之为「Prefix Linear Attention,PLA」 的线性注意力公式。研究者发现,使用他们的 IO 感知实现,JRT-RNN 在 360m 和 1.3b 参数设置下,分别可以提供 13.7 和 6.9 百分点的平均质量改进,吞吐量是 FA2 的 19.2 倍。

- 论文地址:https://arxiv.org/pdf/2407.05483
- 项目主页:https://github.com/HazyResearch/prefix-linear-attention
JRT-Prompt 方法概览
上下文学习任务以 (C, Q, Y) 作为输入,其中 C 为一些上下文来源(如文档或代码存储库),Q 为给定上下文时对模型的一些问题或请求,Y 为答案。对于使用自回归 LM A 的标准上下文学习,研究者输入 C 和 Q,并根据正确的完成情况 Y 来评估生成的输出 Yˆ = A (C, Q)。
JRT-Prompt 是一种极其简单的方法,在提示模型输出答案之前会在上下文中重复提示中的信息(如问题和文档),例如下图 1 右的 Yˆ = A (C, Q, C, Q)。因此,在上下文第二次出现时,模型根据完整的上下文来决定存储哪些信息。

此外,JRT-Prompt 可以与现成的 LLM 一起使用。研究者在零样本提示下,在一系列记忆密集型上下文任务上评估了以下 LM:
- Based 预训练 LM,参数规模为 1.3B,在 Pile 的 10 − 50B 个 token 上进行训练;
- Mamba 预训练的 LM,参数规模为 130M、370M、1.4B 和 2.8B,在 Pile 的 300B 个 token 上进行训练;
- Gated Linear Attention 预训练的 LM,参数规模为 1.3B 和 2.7B,在 SlimPajama 数据集的 100B 个 token 上进行训练;
- Mamba-2 预训练的 LM,参数规模为 130M、370M、1.3B 和 2.7B,在 Pile 的 300B 个 token 上进行训练。
结果如下表 1 所示,通过增加状态(state)大小,研究者发现 JRT-Prompt 方法在各个模型和任务上平均带来了 11.0 ± 1.3 百分点的性能提升,利用该方法的 Based 模型平均优于利用标准提示的 Transformer 模型。
他们还发现,JRT-Prompt 可以使 Transformer 模型受益,并且该方法在一些任务上(附录 2)比少样本学习更加有效。值得注意的是,Springer 等人在论文《Repetition improves language model embeddings》中提出使用自回归 Transformer 模型来重复上下文以实现生成嵌入的目的,本文的研究结果也类似。研究者专注于亚二次架构和上下文学习任务。

JRT-Prompt 虽然由于重复而增加了上下文长度,但是其使用的亚二次循环架构仍比使用二次 Transformer 模型更高效。研究者发现,在序列长度 N = 32768、批大小为 16 时,使用 JRT-Prompt(序列长度 2N)在英伟达 H100 上提供的吞吐量是 FlashAttention-2(序列长度 N)的 11.9 倍。
JRT-RNN:编码器 - 解码器循环架构
JRT-RNN 的灵感来自于 Prefix-LMs,但侧重于扩展质量 - 效率权衡空间的帕累托边界(Pareto frontier)。为了提高质量,JRT-RNN 在编码器端使用了单独的 k_e 和 v_e 映射,在解码器端使用了 k_d 和 v_d 映射。虽然 Prefix LM 模型对编码器和解码器区域使用了共享映射权重,但研究者发现使用两组映射可以提高质量。
为了提高效率,JRT-RNN 为编码器使用了非因果线性注意力,而为解码器使用标准因果线性注意力。研究者称为 Prefix Linear Attention(PLA)(图 1 右),公式如下:
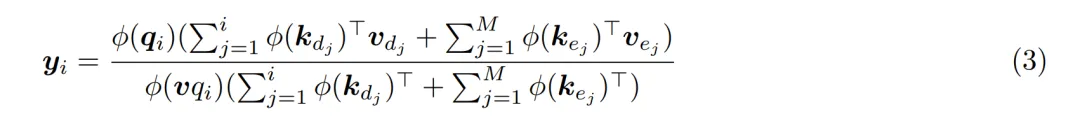
JRT-RNN 训练目标。Prefix LMs 通常不计算非因果区域的损失,而 JRT-RNN 将下一个 token 预测与掩码语言建模(MLM)目标进行了结合。并且对于添加的 MLM 目标,研究者用一个 [MASK] token 替换了来自编码器区域 {u_1, ..., u_M} 的比例为 P 的 tokens,并在预测原始 token 时测量了交叉熵损失 。
。
损失如下:

实验结果
在实验中,研究者评估了 JRT-RNN 在以下三个指标上的质量和效率:
- 上下文学习质量
- 整体语言建模
- 生成
上下文学习质量
如下表 2 所示,研究者发现,JRT-RNN 在参数为 360M(30B tokens)时比仅解码器的基线(Based)平均高出 13.7 个百分点,在参数为 1.3B(50B tokens)时平均高出 6.9 个百分点。
同时,JRT-RNN 在参数为 360M 和 1.3B 时与 Transformer++ 的差距分别缩小到了 0.5 个百分点和 1.9 个百分点之内。
在下表 3 中,研究者比较了当 prefill 长度 l 小于编码器长度 M 时,JRT-RNN 与同类推理策略的表现。

整体自然语言理解
根据以往研究,研究者进一步将困惑度分为了两组:联想记忆「AR slice」包括了被称为「AR hits」的 tokens,它们需要模型按照顺序执行记忆以正确地预测下一个 token;而「Other slice」包含剩余的 tokens(如记忆的知识)。
对于记忆频率,JRT-RNN 在「AR slice」表现出色。对于训练期间不常见的二元组(即不太可能在模型参数中被记住的),JRT-RNN 的困惑度相对于 Based 和 Mamba 这两个强大的因果循环基线有所改善。
对于记忆距离,在「AR slice」中,JRT-RNN 与仅解码器基线之间的差距随着上下文中重复二元组的增加而扩大。这也进一步证明了 JRT-RNN 可以帮助完成更长的上下文记忆任务。
非记忆频率。对于训练期间很少见到的二元组的非记忆「Other slice」,JRT-RNN 的困惑度比仅解码器的 LM 更差。这是意料之中的结果,因为 JRT-RNN 计算了仅解码器 LM 的 65% tokens 的损失。
我们预计这一差距会随着规模和训练时间的延长而缩小(随着二元语法频率的增加而增加)(图 3,左上角)。

生成吞吐量
生成可以分解为提示「prefill 处理」和解码「下一个 token 预测」两步。相较于标准的仅解码器循环模型,JRT-RNN 不会修改解码步骤,因此讨论重点在 prefill 阶段。
使用 Simran Arora 等人论文《Simple linear attention language models balance the recall-throughput tradeof》中提出的 Based CUDAn 内核,JRT-Prompt 在处理 prefill 时吞吐量分别是 FlashAttention-2 和 FLA Triton 内核的 11.9 和 13.7 倍,如下表 5 所示。
当研究者将批大小增加到 64 时,JRT-Prompt 吞吐量分别是 FlashAttention-2 和 FLA Triton 内核的 6.1 倍和 7.2 倍。
接下来他们扩展了 Based 内核以支持 JRT-RNN,并且证明了当将序列长度增加到 32768 时,吞吐量分别是 FlashAttention-2 和 FLA 的 19.2 倍和 22.0 倍。当将批大小增加到 64 时,JRT-RNN 分别又提供了 9.7 倍和 11.5 倍的吞吐量提升。JRT-RNN 所需的时间是 Based prefill 的 1.24 倍,比 JRT-Prompt 更加高效。

更多技术细节和实验结果请参阅原论文。

















