一、引言
编写目的
本文详细描述了SQL限流特性的需求设计方案以及使用方式,开发、测试人员可根据本文实现功能的开发、测试,DBA可根据本文合理使用SQL限流功能。
需求概述
生产环境中可能出现由于业务量增长过快或者慢SQL等原因导致CPU使用率打满,当CPU打满时,会影响所有依赖该数据库实例的业务,因此需要有手段限制影响CPU的业务执行,保证其他核心业务不受影响。
SQL限流的目标是在出现CPU使用率打满影响所有业务时,通过限制非核心业务或者慢SQL的业务,实现核心业务的快速恢复。
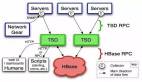
软件结构
MySQL软件结构如下图所示:
 图片
图片
参考资料
MySQL官网:https://dev.mysql.com/doc/refman/5.7/en/
二、概要设计
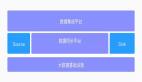
架构设计
 图片
图片
总体架构如图所示,SQL限流的主要功能在执行器工作阶段通过限流规则与查询串的匹配来实现。
流程图
 图片
图片
三、详细设计
功能设计
对外接口
针对SQL限流功能设计对外提供管理命令,如下:
- 开关控制命令(du_flow_control)
 图片
图片
用于控制限流功能是否启用。
- 大小写敏感命令(du_flow_control_case_sensitive)
 图片
图片
用于控制限流规则匹配时是否大小写敏感。
- 预留用户命令(du_flow_control_reserve_user)
 图片
图片
限流功能对于预留用户不生效。
预留用户参数以字符串的形式接受输入,如果存在多个预留用户,使用 ',' 进行分隔。
在服务启动时,需格式化该参数,后续在做限流判断时,需要根据格式化之后参数识别是否是预留用户,如果是预留用户,则不进行限流操作,无需进行后续的限流规则匹配。
预留用户参数接受NULL和空串 '',当该参数为NULL或空串时,表明所有用户都不是预留用户。
对于预留用户字符串的处理,与MySQL社区对于用户名的处理逻辑保持一致,即忽略每个用户名前后的无意义字符(如空格、换行等),保留用户名之间的无意义字符。
- 分隔符设置命令(du_flow_control_delimiter)
 图片
图片
用于控制限流规则的分隔符。
分隔符不可为空,且长度小于等于1024。
修改分隔符之后,需要重新加载限流规则,对限流规则进行解析,会消耗系统资源,因此不建议在系统负载过高时修改分隔符。
对于预留用户的处理,核心功能如下:
// 更新
static bool update_delimiter(sys_var *self, THD *thd, enum_var_type type)
{
reload_rules(thd);
}
// 校验
static bool check_delimiter(sys_var *self, THD *thd, set_var *var)
{
judge(var->value);
judge(str);
judge(length);
}功能模块详细设计
- 规则管理
SQL限流使用的场景为CPU负载过高,为了防止加重系统的负担,限流规则应该事先加载到内存中。基于此,需要对内存中的限流规则进行管理,涉及的操作有:规则的读取、移除、解析。
读取
规则读取的场景有:
- 主动执行自定义读取命令,用于更新限流规则到内存。每当添加限流规则后,需手动执行该操作,更新限流规则到内存。
- 修改分隔符时。修改分隔符后,限流规则需要重新解析,因此也需要重新读取。
- 数据库实例启动时。基于性能考虑,在实例启动时,将限流规则加载到内存中。
移除
规则移除的场景有:
- 系统停止时移除限流规则时。
- 手动删除限流规则时。
解析
用户输入的规则在物理表中的表现是一个字符串,在将其加载到内存时,需要根据限流规则的分隔符将其解析为对应的规则模式串,在模式串中包含的关键字全部被满足时,需要进行限流。解析过程如下:
- 将物理表中的限流规则字符串读取到内存字符串中。
- 根据分隔符将字符串解析为关键字组成的模式串链表。
- 流程控制
SQL限流的的流程控制添加在SQL执行阶段,主要的内容有:
启动时:
- 加载、解析限流规则到内存中。
- 解析预留用户。
int mysqld_main(int argc, char **argv)
{
...
load_rules();
...
}执行时:
- 在具体执行语句之前对查询语句进行判断,如果当前的执行线程是复制相关的系统线程、存储过程和方法、用户是预留用户,则无需进行规则匹配;否则,根据规则匹配的结果来决定是否进行SQL限流。匹配的效率与限流规则的数量、大小、查询串的大小都有关系,由于此时解析完成的限流规则都已在内存中,因此整个匹配过程消耗资源较少。但还是建议用户设置的限流规则更加通用、长度更短、数量更少,这样更能提高限流功能的执行效率。
- 查询执行完成后,维护对应限流规则的当前并发度。具体实现为在thd中添加id字段,在进行限流时,id为非0值,如果在流程中判断id非0,且限流功能已开启,则在限流规则中查找,根据规则节点的id与thd->id进行匹配,如果存在匹配的限流规则,则将其当前并发度减一。
void dec_conc(THD *thd, int command)
{
// 根据查询类型在对应链表找节点
node = find_by_id(list, thd->id);
// 并发数量减1
if (node) {
__sync_sub_and_fetch(&(node->concur), 1);
}
// 重置状态
thd->id = 0;
}关闭时:
关闭服务时,释放限流规则占用的内存资源(遍历规则链表,释放其中每一个节点占用的内存)。
void clean_up()
{
cleanup();
}- 限流匹配
SQL限流的基本功能的实现逻辑为查询串与规则串的匹配,匹配主要的策略如下:
根据DB判断是否是对系统表的查询,如果是对系统表的查询,不做限流。
/* The flow control does not take effect on system tables */
if (check_system_table(first_table->db)) {
return ret;
}针对不同的操作类型,在相应的限流规则链表上做模式匹配。
- 获取并解析链表上的节点,根据链表节点中保存的关键字串与查询串匹配;
- 如果关键字串都匹配到,则匹配成功。
bool check_rule_matched(THD* thd, LIST* list)
{
while (满足条件,无异常) {
// 根据大小写开关是否打开,分别进行模式串匹配
it = find(query_str, item->key_array[nums]);
// 如果it为空,没有匹配到,查看下一个list,否则继续匹配当前限流规则节点
judge();
}
// 匹配成功,或者对下一个节点进行匹配
}在匹配过程中维护原子变量cur_concur、cur_reject、total_reject,分别表示当前并发数、当前限流次数、总的限流次数,用以判断是否需要进行限流以及在系统运行期间观察SQL限流的执行状态。
- 数据获取
用户输入的限流规则保存在限流规则系统表中,在需要读取物理表中的数据时,需要打开表、读取数据、关闭表。
通过创建限流规则表读取类来控制对表的操作,类的定义如下:
class Du_table_access {
public:
Du_table_access() : m_drop_thd_object(NULL) {}
virtual ~Du_table_access() {}
// 初始化打开表的环境、锁表并且打开表
bool init(THD **thd, TABLE **table, bool is_write);
// 关闭表,清理环境
bool deinit(THD *thd, TABLE *table, bool error, bool need_commit);
// 设置打开表的策略
void before_open(THD *thd);
// 如果需要的话创建线程,大部分时候并不需要,因为手动执行读取数据的时候已经在线程中了
THD *create_thd();
// 如果手动创建了 thd,则需要手动清理
void drop_thd(THD *thd);
};读取到的数据以节点的形式保存,并且挂在LIST中进行管理。
限流规则表设计
- 定义系统表保存限流规则,表格式如下:
 图片
图片
SET @cmd= "CREATE TABLE IF NOT EXISTS du_flow_control_rules (
id BIGINT NOT NULL AUTO_INCREMENT COMMENT 'Id of the flow control rules.',
type ENUM('SELECT', 'UPDATE', 'INSERT', 'DELETE') CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT 'Type of flow control rules.',
max_concur INT NOT NULL COMMENT 'Max concurrent of sql.',
orig_str VARCHAR(1024) CHARSET SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT 'Original string of flow control rules.',
PRIMARY KEY(id)) DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT 'Flow control rules info.'";
SET @str=IF(@have_innodb <> 0, CONCAT(@cmd, ' ENGINE= INNODB;'), CONCAT(@cmd, ' ENGINE= MYISAM;'));
PREPARE stmt FROM @str;
EXECUTE stmt;
DROP PREPARE stmt;- 权限与格式控制
通过存储过程实现权限与格式控制:
DELIMITER $$
CREATE DEFINER='root'@'localhost' PROCEDURE mysql.add_flow_control ( IN sql_type INT, IN str VARCHAR(1024), IN max_num INT )
COMMENT '
Description
-----------
Basic functions for inserting rules.
It is not recommended to call it directly, but to call it through add_select_flow_control、
add_update_flow_control、add_update_flow_control and add_delete_flow_control.
'
SQL SECURITY INVOKER
BEGIN
IF (sql_type = 0) THEN
INSERT INTO mysql.du_flow_control_rules(type, max_concur, orig_str) VALUES('SELECT', max_num, str);
ELSEIF (sql_type = 1) THEN
INSERT INTO mysql.du_flow_control_rules(type, max_concur, orig_str) VALUES('UPDATE', max_num, str);
ELSEIF (sql_type = 2) THEN
INSERT INTO mysql.du_flow_control_rules(type, max_concur, orig_str) VALUES('INSERT', max_num, str);
ELSEIF (sql_type = 3) THEN
INSERT INTO mysql.du_flow_control_rules(type, max_concur, orig_str) VALUES('DELETE', max_num, str);
ELSE
SIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = 'Sql type is error, please input correctly.';
END IF;
END$$
CREATE DEFINER='root'@'localhost' PROCEDURE mysql.add_select_flow_control (IN str VARCHAR(1024), IN max_num INT )
COMMENT '
Description
-----------
Used to add select type rules to the current rule table.
Parameters
-----------
str (VARCHAR(1024)):
The string of select rules entered by user.
max_num (INT):
The number of queries that can be executed concurrently.
Example
--------
mysql> SELECT * FROM du_flow_control_rules;
Empty set (0.00 sec)
mysql> CALL add_select_flow_control(''select~from~t1'', 100);
Query OK, 1 row affected (0.00 sec)
mysql> SELECT * FROM du_flow_control_rules;
+----+--------+------------+----------------+
| id | type | max_concur | orig_str |
+----+--------+------------+----------------+
| 1 | SELECT | 100 | select~from~t1 |
+----+--------+------------+----------------+
1 row in set (0.00 sec)
'
SQL SECURITY INVOKER
BEGIN
CALL add_flow_control(0, str, max_num);
END$$
DELIMITER ;性能设计
当开关关闭时,对于每一个查询在内核中执行,增加了对开关是否打开的判断的消耗,该操作对于整个语句的执行来说影响较小,可以忽略。
当开关打开时,需要将查询字符串与限流规则进行匹配,整个过程是内存操作,且根据类型将限流规则分为不同的链表,加快匹配速度,整个过程对性能的影响与限流规则的数量以及复杂度有关(注:加入SQL限流特性对系统有影响,影响程度与限流规则的数量和复杂度有关,但实际使用场景是针对少部分业务进行限流,且不需要限流的时候不启用该功能,因此该场景对性能的影响不决定最终实现)。
性能设计:
- 刷新限流规则到节点时,为了提升加载效率,节省不必要的遍历,使用MySQL原生的链表插入方法,且只增删限流规则,不允许修改限流规则。具体流程为,在限流规则节点增加ID字段,该字段与规则表中的自增主键ID对应,即该字段递增。在从系统表中读取数据后,根据ID可以快速判断出该条记录该插入的情况,此时对于该条记录,可能有两种场景:一是该条记录已经加载并解析到内存(链表中存在该节点),无需再次插入;二是这条记录还没有加载到内存,找到对应位置插入即可。
- 在数据库实例启动时,从已有系统表中加载一次数据,提升后续限流效率。
- 使用方面:
由于分隔符的选择决定了限流规则的不同形式,因此修改分隔符会导致限流规则全部重新加载解析一次,尽量不在业务高峰期修改分隔符。
SQL限流的性能取决于限流规则的数量、关键字数量、查询的单词数量,因此在使用时,应尽量使用较为通用的限流规则。
功能限制
- 当SQL语句匹配多条限流规则时,优先生效最新添加的规则;
- 在添加SQL限流规则之前,已经开始执行的SQL语句,不会被记入并发数;
- 存储过程、触发器、函数和对系统表的查询不受SQL限流的限制;
- 当设置过多限流规则时,对性能有一定影响。
四、总结
本文详细描述了基于MySQL内核的SQL限流功能的整体架构、主要功能模块等关键要素。SQL限流的设计与实现基于原生MySQL的执行原理与字符串匹配规则实现。整体功能对原生MySQL嵌入修改较少,除了对是否进行限流的判断以外,其他功能以独立模块呈现,安全可控。